 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioNeMo Framework: a modular, high-performance library for AI model development in drug discovery
Nov 15, 2024



Artificial Intelligence models encoding biology and chemistry are opening new routes to high-throughput and high-quality in-silico drug development. However, their training increasingly relies on computational scale, with recent protein language models (pLM) training on hundreds of graphical processing units (GPUs). We introduce the BioNeMo Framework to facilitate the training of computational biology and chemistry AI models across hundreds of GPUs. Its modular design allows the integration of individual components, such as data loaders, into existing workflows and is open to community contributions. We detail technical features of the BioNeMo Framework through use cases such as pLM pre-training and fine-tuning. On 256 NVIDIA A100s, BioNeMo Framework trains a three billion parameter BERT-based pLM on over one trillion tokens in 4.2 days. The BioNeMo Framework is open-source and free for everyone to use.
Learning Probabilistic Models from Generator Latent Spaces with Hat EBM
Oct 29, 2022



This work proposes a method for using any generator network as the foundation of an Energy-Based Model (EBM). Our formulation posits that observed images are the sum of unobserved latent variables passed through the generator network and a residual random variable that spans the gap between the generator output and the image manifold. One can then define an EBM that includes the generator as part of its forward pass, which we call the Hat EBM. The model can be trained without inferring the latent variables of the observed data or calculating the generator Jacobian determinant. This enables explicit probabilistic modeling of the output distribution of any type of generator network. Experiments show strong performance of the proposed method on (1) unconditional ImageNet synthesis at 128x128 resolution, (2) refining the output of existing generators, and (3) learning EBMs that incorporate non-probabilistic generators. Code and pretrained models to reproduce our results are available at https://github.com/point0bar1/hat-ebm.
EBM Life Cycle: MCMC Strategies for Synthesis, Defense, and Density Modeling
May 24, 2022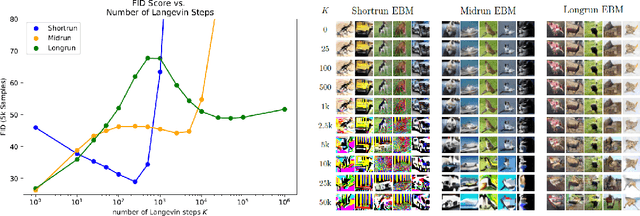

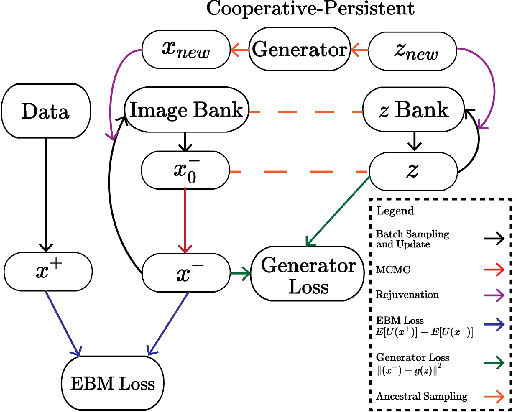
This work presents strategies to learn an Energy-Based Model (EBM) according to the desired length of its MCMC sampling trajectories. MCMC trajectories of different lengths correspond to models with different purposes. Our experiments cover three different trajectory magnitudes and learning outcomes: 1) shortrun sampling for image generation; 2) midrun sampling for classifier-agnostic adversarial defense; and 3) longrun sampling for principled modeling of image probability densities. To achieve these outcomes, we introduce three novel methods of MCMC initialization for negative samples used in Maximum Likelihood (ML) learning. With standard network architectures and an unaltered ML objective, our MCMC initialization methods alone enable significant performance gains across the three applications that we investigate. Our results include state-of-the-art FID scores for unnormalized image densities on the CIFAR-10 and ImageNet datasets; state-of-the-art adversarial defense on CIFAR-10 among purification methods and the first EBM defense on ImageNet; and scalable techniques for learning valid probability densities. Code for this project can be found at https://github.com/point0bar1/ebm-life-cycle.
Stochastic Security: Adversarial Defense Using Long-Run Dynamics of Energy-Based Models
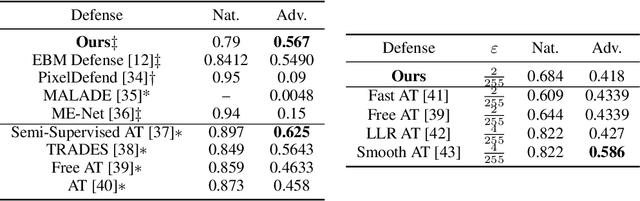
May 27, 2020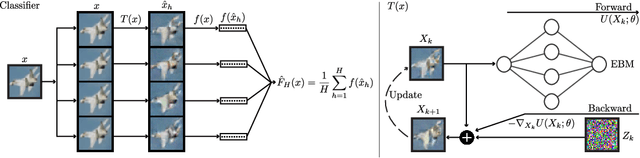
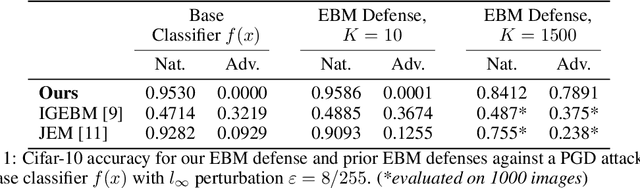


The vulnerability of deep networks to adversarial attacks is a central problem for deep learning from the perspective of both cognition and security. The current most successful defense method is to train a classifier using adversarial images created during learning. Another defense approach involves transformation or purification of the original input to remove adversarial signals before the image is classified. We focus on defending naturally-trained classifiers using Markov Chain Monte Carlo (MCMC) sampling with an Energy-Based Model (EBM) for adversarial purification. In contrast to adversarial training, our approach is intended to secure pre-existing and highly vulnerable classifiers. The memoryless behavior of long-run MCMC sampling will eventually remove adversarial signals, while metastable behavior preserves consistent appearance of MCMC samples after many steps to allow accurate long-run prediction. Balancing these factors can lead to effective purification and robust classification. We evaluate adversarial defense with an EBM using the strongest known attacks against purification. Our contributions are 1) an improved method for training EBM's with realistic long-run MCMC samples, 2) an Expectation-Over-Transformation (EOT) defense that resolves theoretical ambiguities for stochastic defenses and from which the EOT attack naturally follows, and 3) state-of-the-art adversarial defense for naturally-trained classifiers and competitive defense compared to adversarially-trained classifiers on Cifar-10, SVHN, and Cifar-100. Code and pre-trained models are available at https://github.com/point0bar1/ebm-defense.
Bounding Box Embedding for Single Shot Person Instance Segmentation
Jul 20, 2018
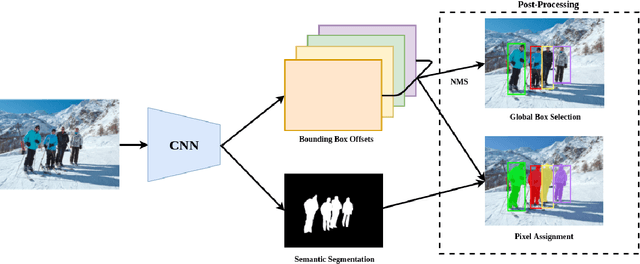
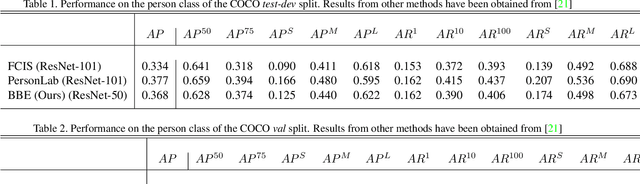

We present a bottom-up approach for the task of object instance segmentation using a single-shot model. The proposed model employs a fully convolutional network which is trained to predict class-wise segmentation masks as well as the bounding boxes of the object instances to which each pixel belongs. This allows us to group object pixels into individual instances. Our network architecture is based on the DeepLabv3+ model, and requires only minimal extra computation to achieve pixel-wise instance assignments. We apply our method to the task of person instance segmentation, a common task relevant to many applications. We train our model with COCO data and report competitive results for the person class in the COCO instance segmentation task.