 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDF-RAG: Query-Aware Diversity for Retrieval-Augmented Generation
Jan 23, 2026Retrieval-augmented generation (RAG) is a common technique for grounding language model outputs in domain-specific information. However, RAG is often challenged by reasoning-intensive question-answering (QA), since common retrieval methods like cosine similarity maximize relevance at the cost of introducing redundant content, which can reduce information recall. To address this, we introduce Diversity-Focused Retrieval-Augmented Generation (DF-RAG), which systematically incorporates diversity into the retrieval step to improve performance on complex, reasoning-intensive QA benchmarks. DF-RAG builds upon the Maximal Marginal Relevance framework to select information chunks that are both relevant to the query and maximally dissimilar from each other. A key innovation of DF-RAG is its ability to optimize the level of diversity for each query dynamically at test time without requiring any additional fine-tuning or prior information. We show that DF-RAG improves F1 performance on reasoning-intensive QA benchmarks by 4-10 percent over vanilla RAG using cosine similarity and also outperforms other established baselines. Furthermore, we estimate an Oracle ceiling of up to 18 percent absolute F1 gains over vanilla RAG, of which DF-RAG captures up to 91.3 percent.
Synergistic Network Learning and Label Correction for Noise-robust Image Classification
Feb 27, 2022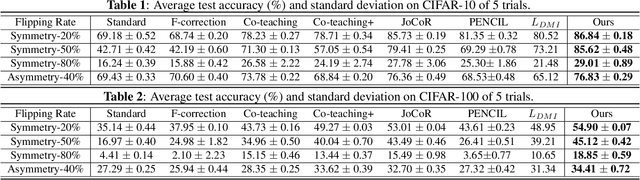
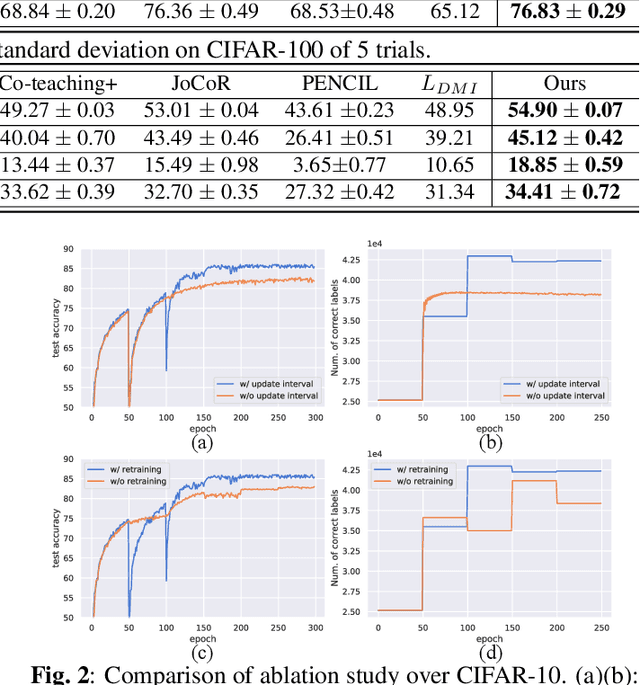
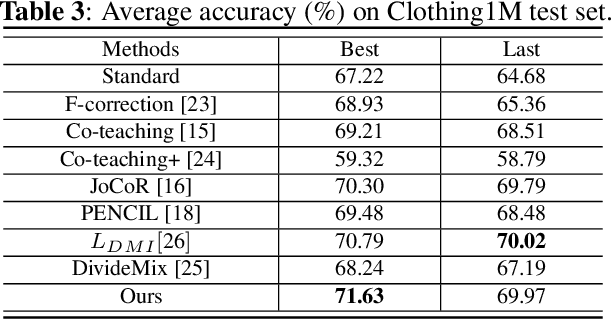
Large training datasets almost always contain examples with inaccurate or incorrect labels. Deep Neural Networks (DNNs) tend to overfit training label noise, resulting in poorer model performance in practice. To address this problem, we propose a robust label correction framework combining the ideas of small loss selection and noise correction, which learns network parameters and reassigns ground truth labels iteratively. Taking the expertise of DNNs to learn meaningful patterns before fitting noise, our framework first trains two networks over the current dataset with small loss selection. Based on the classification loss and agreement loss of two networks, we can measure the confidence of training data. More and more confident samples are selected for label correction during the learning process. We demonstrate our method on both synthetic and real-world datasets with different noise types and rates, including CIFAR-10, CIFAR-100 and Clothing1M, where our method outperforms the baseline approaches.
Stochastic Planner-Actor-Critic for Unsupervised Deformable Image Registration
Dec 14, 2021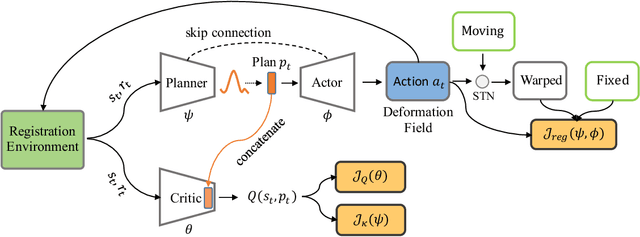
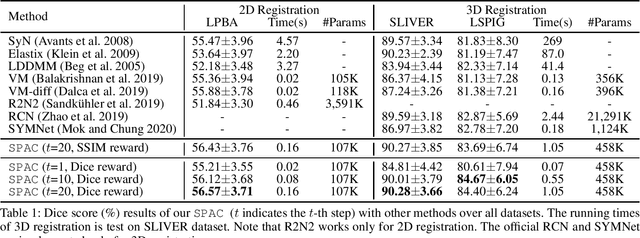
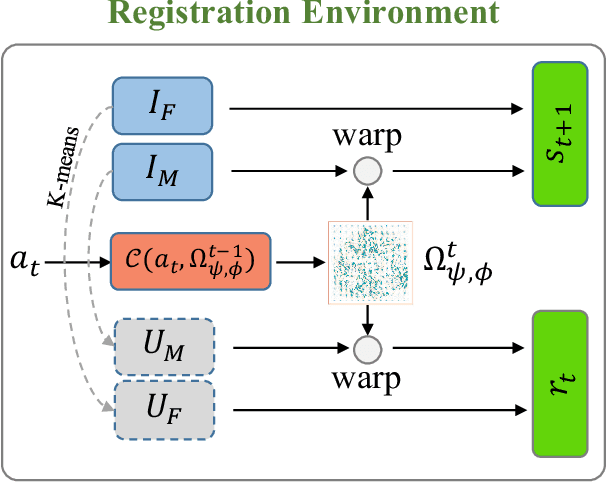
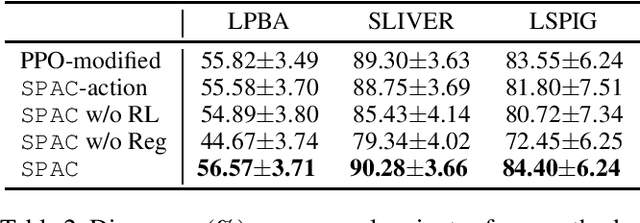
Large deformations of organs, caused by diverse shapes and nonlinear shape changes, pose a significant challenge for medical image registration. Traditional registration methods need to iteratively optimize an objective function via a specific deformation model along with meticulous parameter tuning, but which have limited capabilities in registering images with large deformations. While deep learning-based methods can learn the complex mapping from input images to their respective deformation field, it is regression-based and is prone to be stuck at local minima, particularly when large deformations are involved. To this end, we present Stochastic Planner-Actor-Critic (SPAC), a novel reinforcement learning-based framework that performs step-wise registration. The key notion is warping a moving image successively by each time step to finally align to a fixed image. Considering that it is challenging to handle high dimensional continuous action and state spaces in the conventional reinforcement learning (RL) framework, we introduce a new concept `Plan' to the standard Actor-Critic model, which is of low dimension and can facilitate the actor to generate a tractable high dimensional action. The entire framework is based on unsupervised training and operates in an end-to-end manner. We evaluate our method on several 2D and 3D medical image datasets, some of which contain large deformations. Our empirical results highlight that our work achieves consistent, significant gains and outperforms state-of-the-art methods.
Stochastic Actor-Executor-Critic for Image-to-Image Translation
Dec 14, 2021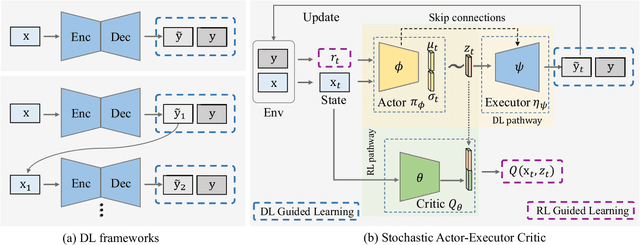
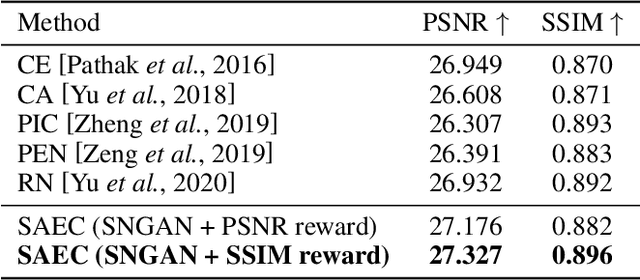


Training a model-free deep reinforcement learning model to solve image-to-image translation is difficult since it involves high-dimensional continuous state and action spaces. In this paper, we draw inspiration from the recent success of the maximum entropy reinforcement learning framework designed for challenging continuous control problems to develop stochastic policies over high dimensional continuous spaces including image representation, generation, and control simultaneously. Central to this method is the Stochastic Actor-Executor-Critic (SAEC) which is an off-policy actor-critic model with an additional executor to generate realistic images. Specifically, the actor focuses on the high-level representation and control policy by a stochastic latent action, as well as explicitly directs the executor to generate low-level actions to manipulate the state. Experiments on several image-to-image translation tasks have demonstrated the effectiveness and robustness of the proposed SAEC when facing high-dimensional continuous space problems.
Transferable Adversarial Examples for Anchor Free Object Detection
Jun 04, 2021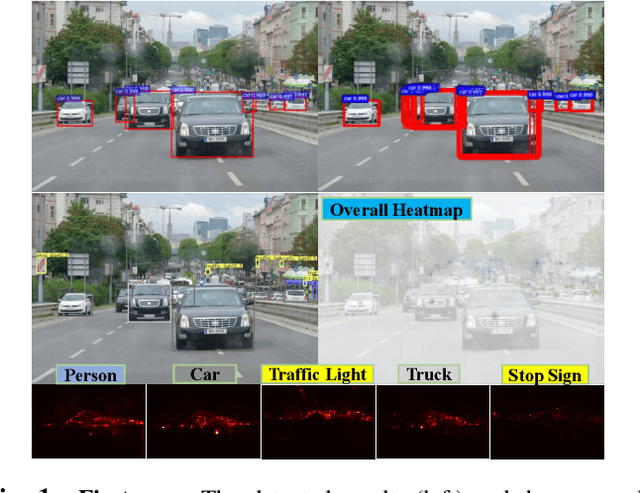
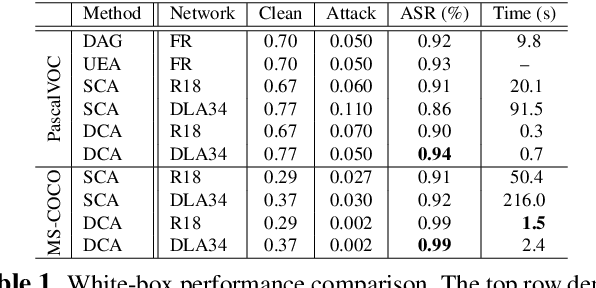
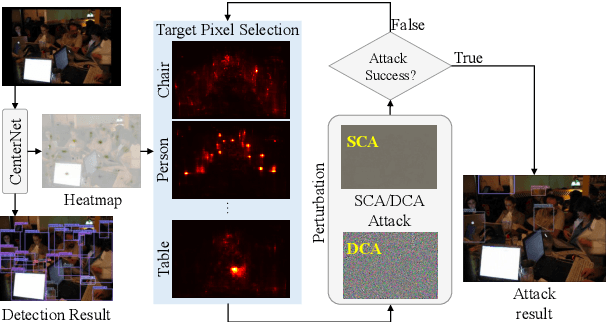
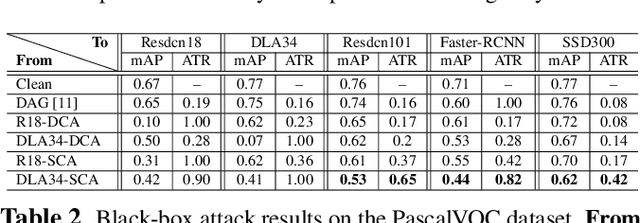
Deep neural networks have been demonstrated to be vulnerable to adversarial attacks: subtle perturbation can completely change prediction result. The vulnerability has led to a surge of research in this direction, including adversarial attacks on object detection networks. However, previous studies are dedicated to attacking anchor-based object detectors. In this paper, we present the first adversarial attack on anchor-free object detectors. It conducts category-wise, instead of previously instance-wise, attacks on object detectors, and leverages high-level semantic information to efficiently generate transferable adversarial examples, which can also be transferred to attack other object detectors, even anchor-based detectors such as Faster R-CNN. Experimental results on two benchmark datasets demonstrate that our proposed method achieves state-of-the-art performance and transferability.
Imperceptible Adversarial Examples for Fake Image Detection
Jun 03, 2021
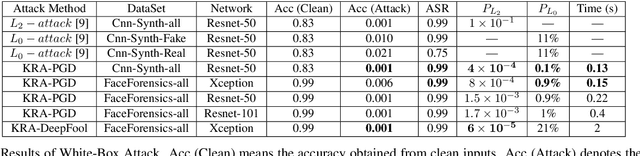

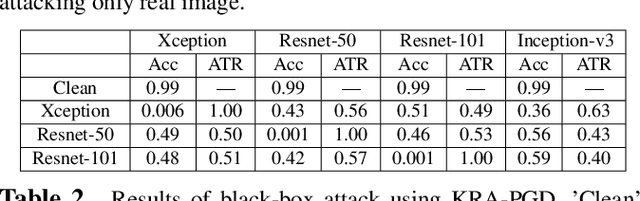
Fooling people with highly realistic fake images generated with Deepfake or GANs brings a great social disturbance to our society. Many methods have been proposed to detect fake images, but they are vulnerable to adversarial perturbations -- intentionally designed noises that can lead to the wrong prediction. Existing methods of attacking fake image detectors usually generate adversarial perturbations to perturb almost the entire image. This is redundant and increases the perceptibility of perturbations. In this paper, we propose a novel method to disrupt the fake image detection by determining key pixels to a fake image detector and attacking only the key pixels, which results in the $L_0$ and the $L_2$ norms of adversarial perturbations much less than those of existing works. Experiments on two public datasets with three fake image detectors indicate that our proposed method achieves state-of-the-art performance in both white-box and black-box attacks.
Fast Local Attack: Generating Local Adversarial Examples for Object Detectors
Oct 27, 2020

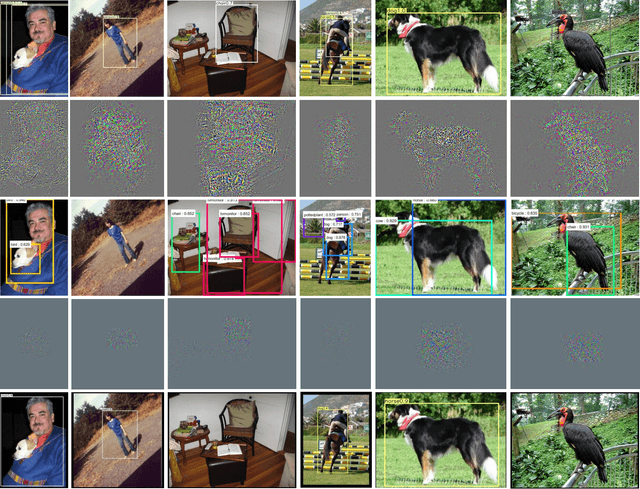

The deep neural network is vulnerable to adversarial examples. Adding imperceptible adversarial perturbations to images is enough to make them fail. Most existing research focuses on attacking image classifiers or anchor-based object detectors, but they generate globally perturbation on the whole image, which is unnecessary. In our work, we leverage higher-level semantic information to generate high aggressive local perturbations for anchor-free object detectors. As a result, it is less computationally intensive and achieves a higher black-box attack as well as transferring attack performance. The adversarial examples generated by our method are not only capable of attacking anchor-free object detectors, but also able to be transferred to attack anchor-based object detector.
Category-wise Attack: Transferable Adversarial Examples for Anchor Free Object Detection
Feb 10, 2020Deep neural networks have been demonstrated to be vulnerable to adversarial attacks: sutle perturbations can completely change the classification results. Their vulnerability has led to a surge of research in this direction. However, most works dedicated to attacking anchor-based object detection models. In this work, we aim to present an effective and efficient algorithm to generate adversarial examples to attack anchor-free object models based on two approaches. First, we conduct category-wise instead of instance-wise attacks on the object detectors. Second, we leverage the high-level semantic information to generate the adversarial examples. Surprisingly, the generated adversarial examples it not only able to effectively attack the targeted anchor-free object detector but also to be transferred to attack other object detectors, even anchor-based detectors such as Faster R-CNN.
Domain Embedded Multi-model Generative Adversarial Networks for Image-based Face Inpainting
Feb 05, 2020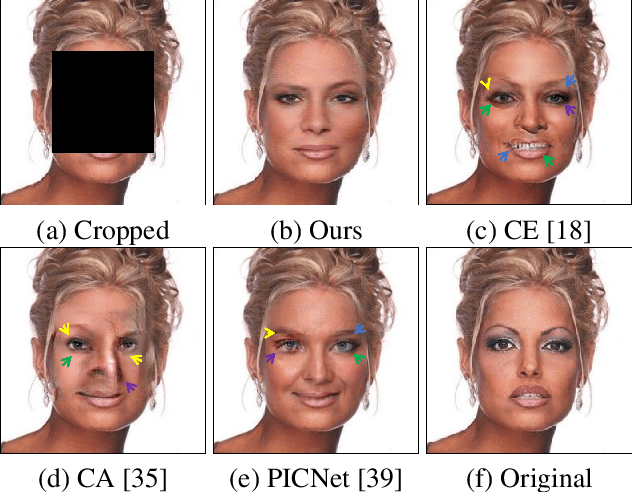
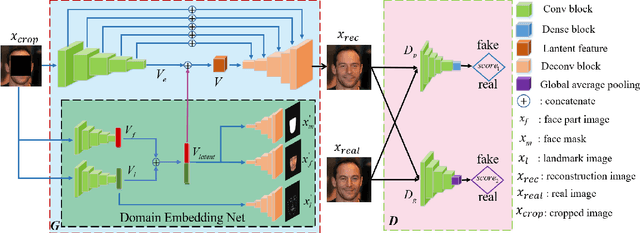
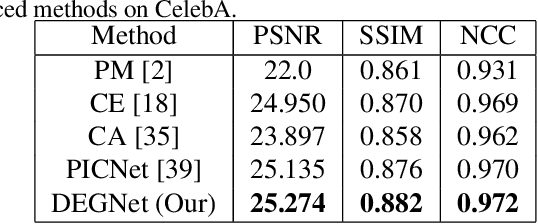
Prior knowledge of face shape and location plays an important role in face inpainting. However, traditional facing inpainting methods mainly focus on the generated image resolution of the missing portion but without consideration of the special particularities of the human face explicitly and generally produce discordant facial parts. To solve this problem, we present a stable variational latent generative model for large inpainting of face images. We firstly represent only face regions with the latent variable space but simultaneously constraint the random vectors to offer control over the distribution of latent variables, and combine with the non-face parts textures to generate a face image with plausible contents. Two adversarial discriminators are finally used to judge whether the generated distribution is close to the real distribution or not. It can not only synthesize novel image structures but also explicitly utilize the latent space with Eigenfaces to make better predictions. Furthermore, our work better evaluates the side face impainting problem. Experiments on both CelebA and CelebA-HQ face datasets demonstrate that our proposed approach generates higher quality inpainting results than existing ones.
DeepCenterline: a Multi-task Fully Convolutional Network for Centerline Extraction
Mar 25, 2019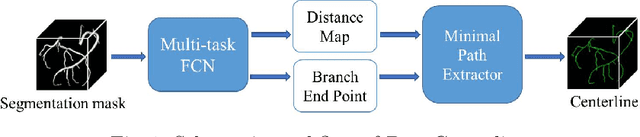

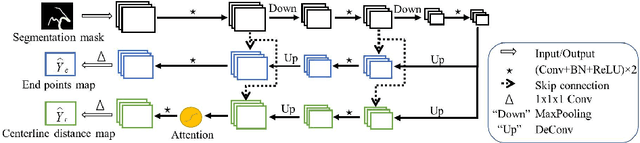
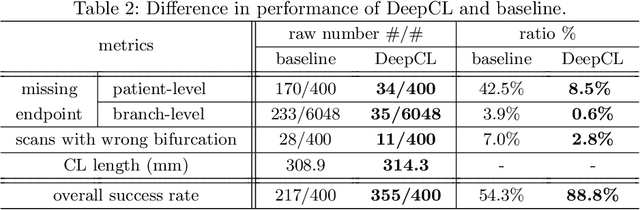
A novel centerline extraction framework is reported which combines an end-to-end trainable multi-task fully convolutional network (FCN) with a minimal path extractor. The FCN simultaneously computes centerline distance maps and detects branch endpoints. The method generates single-pixel-wide centerlines with no spurious branches. It handles arbitrary tree-structured object with no prior assumption regarding depth of the tree or its bifurcation pattern. It is also robust to substantial scale changes across different parts of the target object and minor imperfections of the object's segmentation mask. To the best of our knowledge, this is the first deep-learning based centerline extraction method that guarantees single-pixel-wide centerline for a complex tree-structured object. The proposed method is validated in coronary artery centerline extraction on a dataset of 620 patients (400 of which used as test set). This application is challenging due to the large number of coronary branches, branch tortuosity, and large variations in length, thickness, shape, etc. The proposed method generates well-positioned centerlines, exhibiting lower number of missing branches and is more robust in the presence of minor imperfections of the object segmentation mask. Compared to a state-of-the-art traditional minimal path approach, our method improves patient-level success rate of centerline extraction from 54.3% to 88.8% according to independent human expert review.