 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDHBE: Data-free Holistic Backdoor Erasing in Deep Neural Networks via Restricted Adversarial Distillation
Jun 13, 2023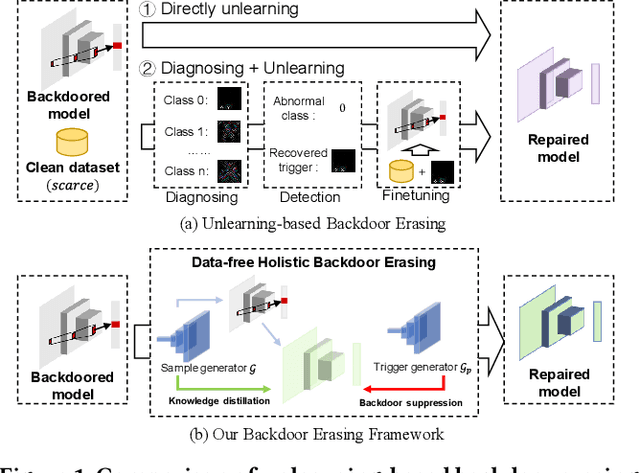
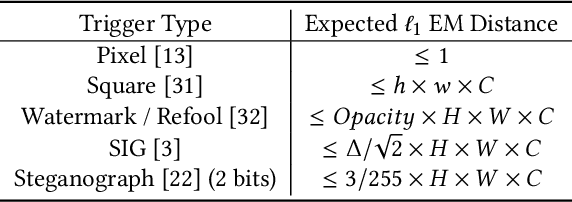
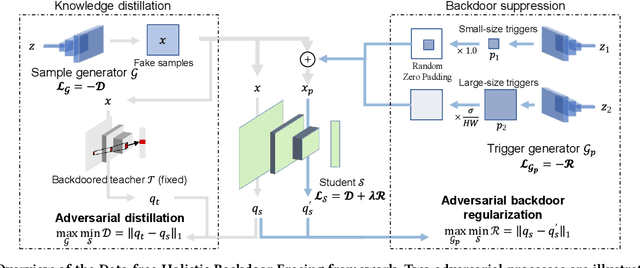

Backdoor attacks have emerged as an urgent threat to Deep Neural Networks (DNNs), where victim DNNs are furtively implanted with malicious neurons that could be triggered by the adversary. To defend against backdoor attacks, many works establish a staged pipeline to remove backdoors from victim DNNs: inspecting, locating, and erasing. However, in a scenario where a few clean data can be accessible, such pipeline is fragile and cannot erase backdoors completely without sacrificing model accuracy. To address this issue, in this paper, we propose a novel data-free holistic backdoor erasing (DHBE) framework. Instead of the staged pipeline, the DHBE treats the backdoor erasing task as a unified adversarial procedure, which seeks equilibrium between two different competing processes: distillation and backdoor regularization. In distillation, the backdoored DNN is distilled into a proxy model, transferring its knowledge about clean data, yet backdoors are simultaneously transferred. In backdoor regularization, the proxy model is holistically regularized to prevent from infecting any possible backdoor transferred from distillation. These two processes jointly proceed with data-free adversarial optimization until a clean, high-accuracy proxy model is obtained. With the novel adversarial design, our framework demonstrates its superiority in three aspects: 1) minimal detriment to model accuracy, 2) high tolerance for hyperparameters, and 3) no demand for clean data. Extensive experiments on various backdoor attacks and datasets are performed to verify the effectiveness of the proposed framework. Code is available at \url{https://github.com/yanzhicong/DHBE}
Joint learning of interpretation and distillation
May 24, 2020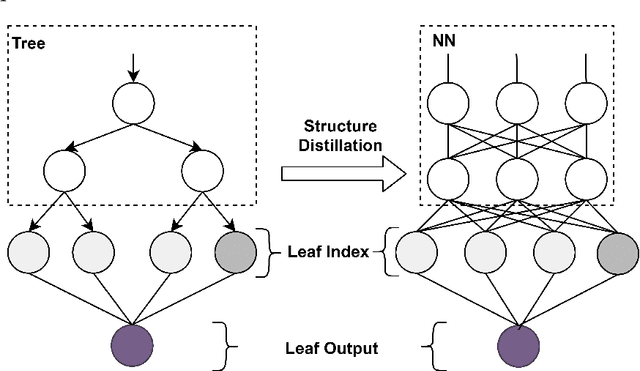

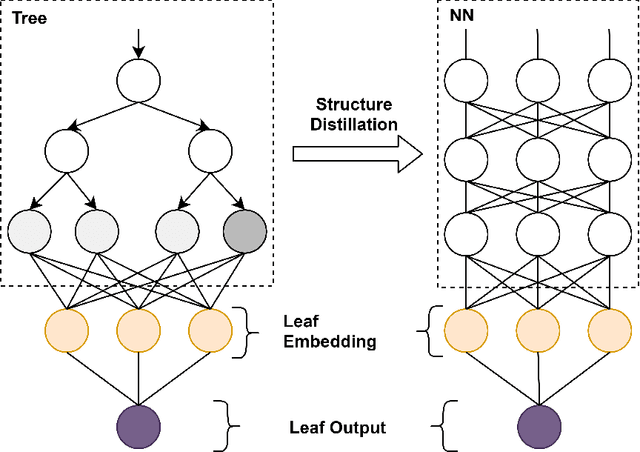
The extra trust brought by the model interpretation has made it an indispensable part of machine learning systems. But to explain a distilled model's prediction, one may either work with the student model itself, or turn to its teacher model. This leads to a more fundamental question: if a distilled model should give a similar prediction for a similar reason as its teacher model on the same input? This question becomes even more crucial when the two models have dramatically different structure, taking GBDT2NN for example. This paper conducts an empirical study on the new approach to explaining each prediction of GBDT2NN, and how imitating the explanation can further improve the distillation process as an auxiliary learning task. Experiments on several benchmarks show that the proposed methods achieve better performance on both explanations and predictions.