 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint learning of interpretation and distillation
Paper and Code
May 24, 2020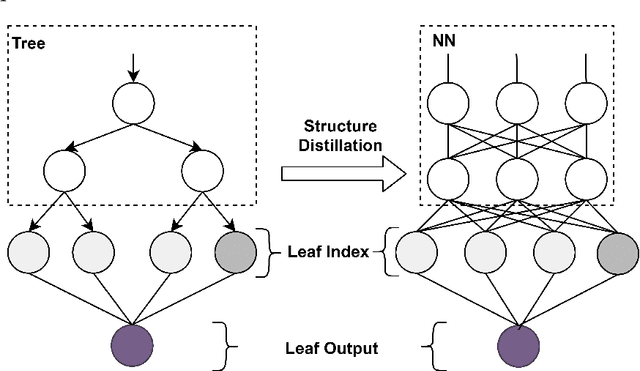

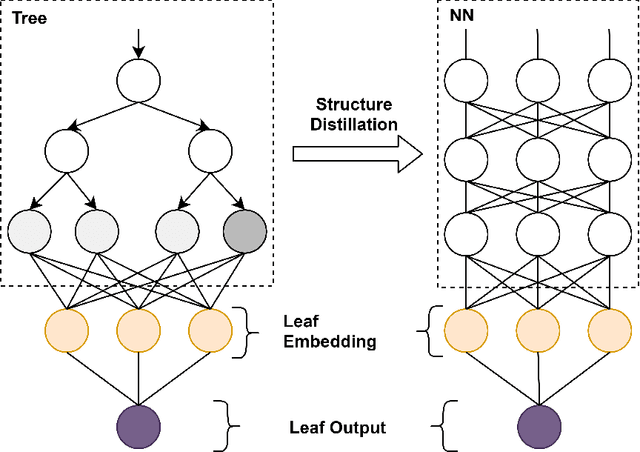
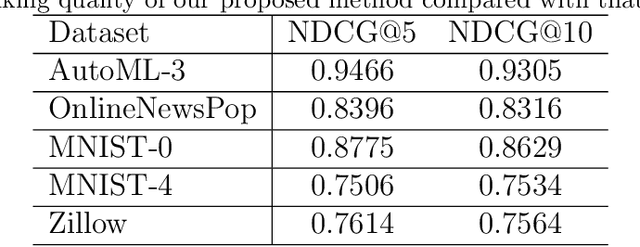
The extra trust brought by the model interpretation has made it an indispensable part of machine learning systems. But to explain a distilled model's prediction, one may either work with the student model itself, or turn to its teacher model. This leads to a more fundamental question: if a distilled model should give a similar prediction for a similar reason as its teacher model on the same input? This question becomes even more crucial when the two models have dramatically different structure, taking GBDT2NN for example. This paper conducts an empirical study on the new approach to explaining each prediction of GBDT2NN, and how imitating the explanation can further improve the distillation process as an auxiliary learning task. Experiments on several benchmarks show that the proposed methods achieve better performance on both explanations and predictions.