 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint learning of interpretation and distillation
May 24, 2020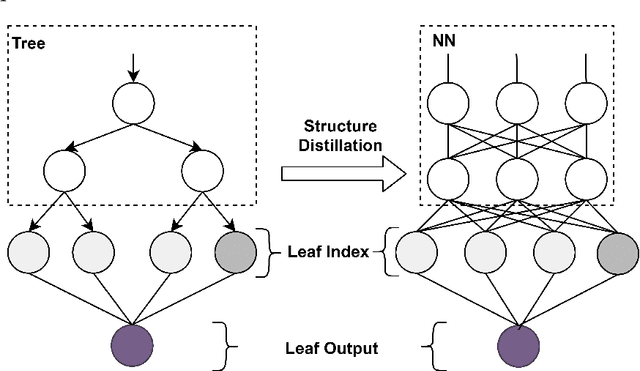

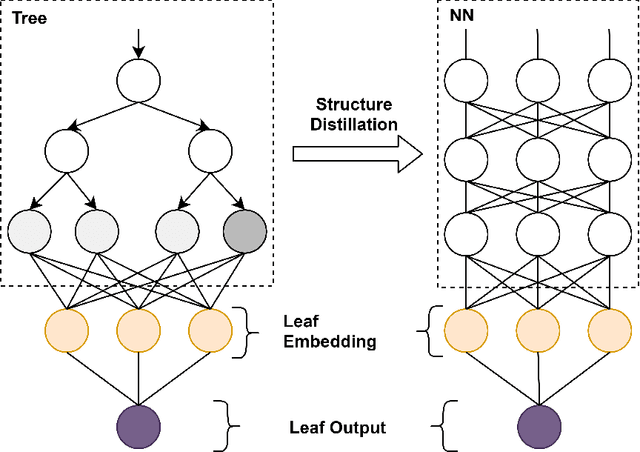
The extra trust brought by the model interpretation has made it an indispensable part of machine learning systems. But to explain a distilled model's prediction, one may either work with the student model itself, or turn to its teacher model. This leads to a more fundamental question: if a distilled model should give a similar prediction for a similar reason as its teacher model on the same input? This question becomes even more crucial when the two models have dramatically different structure, taking GBDT2NN for example. This paper conducts an empirical study on the new approach to explaining each prediction of GBDT2NN, and how imitating the explanation can further improve the distillation process as an auxiliary learning task. Experiments on several benchmarks show that the proposed methods achieve better performance on both explanations and predictions.
Accelerating System Log Processing by Semi-supervised Learning: A Technical Report
Oct 29, 2018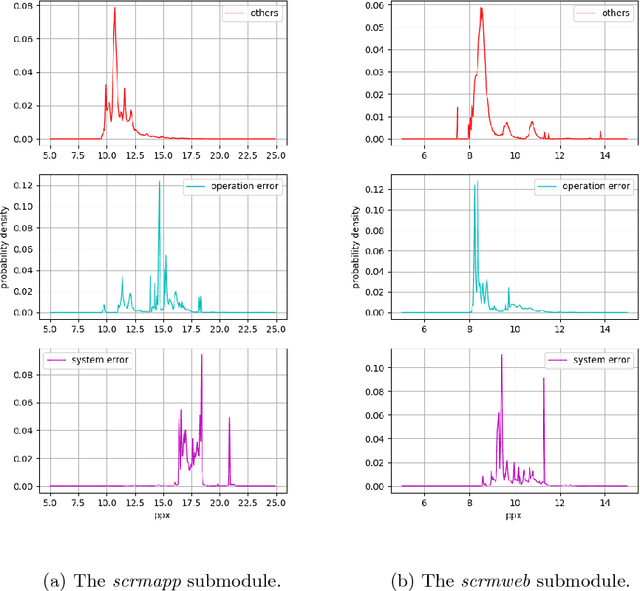

There is an increasing need for more automated system-log analysis tools for large scale online system in a timely manner. However, conventional way to monitor and classify the log output based on keyword list does not scale well for complex system in which codes contributed by a large group of developers, with diverse ways of encoding the error messages, often with misleading pre-set labels. In this paper, we propose that the design of a large scale online log analysis should follow the "Least Prior Knowledge Principle", in which unsupervised or semi-supervised solution with the minimal prior knowledge of the log should be encoded directly. Thereby, we report our experience in designing a two-stage machine learning based method, in which the system logs are regarded as the output of a quasi-natural language, pre-filtered by a perplexity score threshold, and then undergo a fine-grained classification procedure. Tests on empirical data show that our method has obvious advantage regarding to the processing speed and classification accuracy.
Security Matters: A Survey on Adversarial Machine Learning
Oct 23, 2018
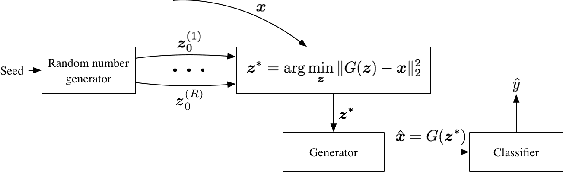
Adversarial machine learning is a fast growing research area, which considers the scenarios when machine learning systems may face potential adversarial attackers, who intentionally synthesize input data to make a well-trained model to make mistake. It always involves a defending side, usually a classifier, and an attacking side that aims to cause incorrect output. The earliest studies on the adversarial examples for machine learning algorithms start from the information security area, which considers a much wider varieties of attacking methods. But recent research focus that popularized by the deep learning community places strong emphasis on how the "imperceivable" perturbations on the normal inputs may cause dramatic mistakes by the deep learning with supposed super-human accuracy. This paper serves to give a comprehensive introduction to a range of aspects of the adversarial deep learning topic, including its foundations, typical attacking and defending strategies, and some extended studies.