 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating System Log Processing by Semi-supervised Learning: A Technical Report
Paper and Code
Oct 29, 2018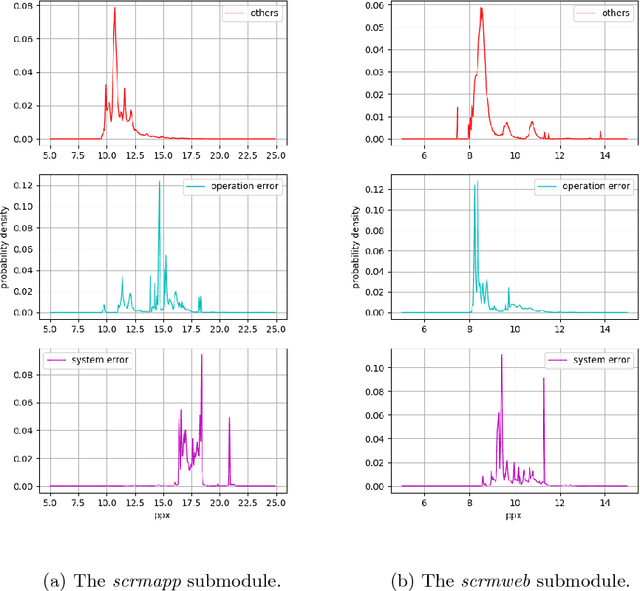

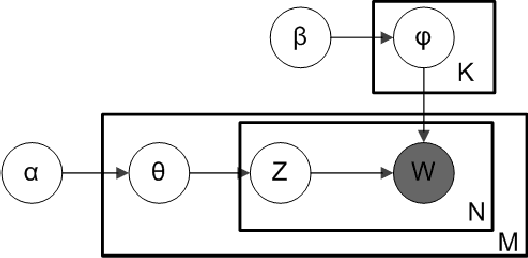
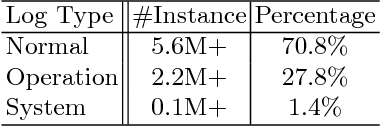
There is an increasing need for more automated system-log analysis tools for large scale online system in a timely manner. However, conventional way to monitor and classify the log output based on keyword list does not scale well for complex system in which codes contributed by a large group of developers, with diverse ways of encoding the error messages, often with misleading pre-set labels. In this paper, we propose that the design of a large scale online log analysis should follow the "Least Prior Knowledge Principle", in which unsupervised or semi-supervised solution with the minimal prior knowledge of the log should be encoded directly. Thereby, we report our experience in designing a two-stage machine learning based method, in which the system logs are regarded as the output of a quasi-natural language, pre-filtered by a perplexity score threshold, and then undergo a fine-grained classification procedure. Tests on empirical data show that our method has obvious advantage regarding to the processing speed and classification accuracy.