 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Argument Structure of Learner Chinese Understandable: A Corpus-Based Analysis
Aug 17, 2023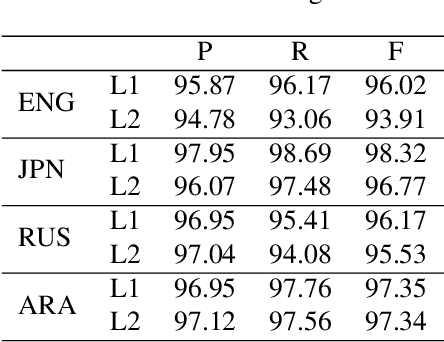
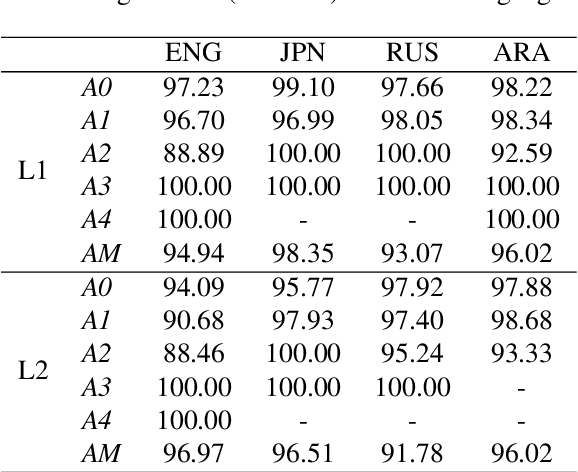
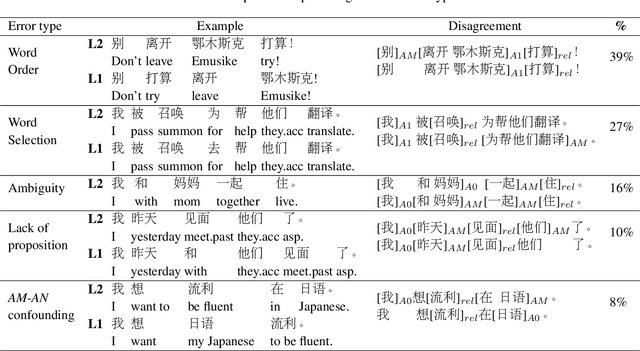
This paper presents a corpus-based analysis of argument structure errors in learner Chinese. The data for analysis includes sentences produced by language learners as well as their corrections by native speakers. We couple the data with semantic role labeling annotations that are manually created by two senior students whose majors are both Applied Linguistics. The annotation procedure is guided by the Chinese PropBank specification, which is originally developed to cover first language phenomena. Nevertheless, we find that it is quite comprehensive for handling second language phenomena. The inter-annotator agreement is rather high, suggesting the understandability of learner texts to native speakers. Based on our annotations, we present a preliminary analysis of competence errors related to argument structure. In particular, speech errors related to word order, word selection, lack of proposition, and argument-adjunct confounding are discussed.
Semantic Role Labeling for Learner Chinese: the Importance of Syntactic Parsing and L2-L1 Parallel Data
Aug 29, 2018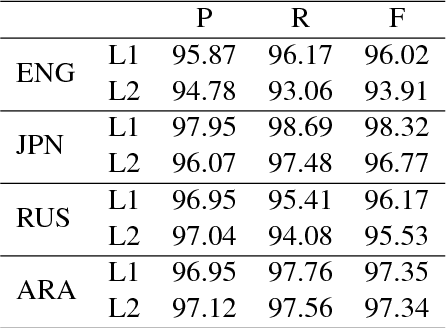
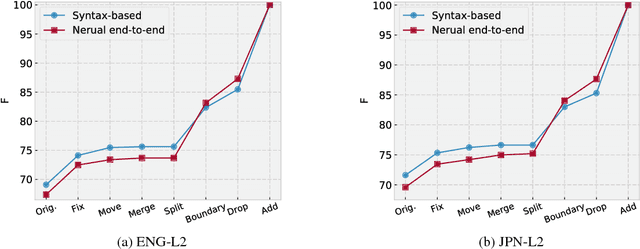
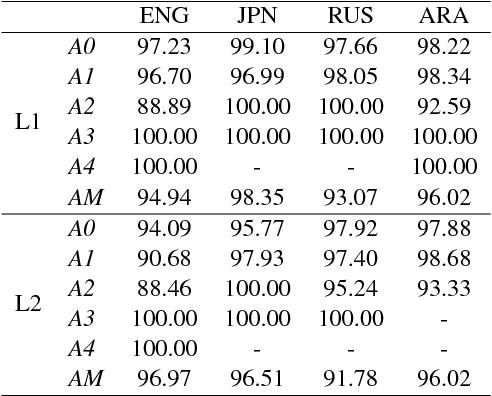

This paper studies semantic parsing for interlanguage (L2), taking semantic role labeling (SRL) as a case task and learner Chinese as a case language. We first manually annotate the semantic roles for a set of learner texts to derive a gold standard for automatic SRL. Based on the new data, we then evaluate three off-the-shelf SRL systems, i.e., the PCFGLA-parser-based, neural-parser-based and neural-syntax-agnostic systems, to gauge how successful SRL for learner Chinese can be. We find two non-obvious facts: 1) the L1-sentence-trained systems performs rather badly on the L2 data; 2) the performance drop from the L1 data to the L2 data of the two parser-based systems is much smaller, indicating the importance of syntactic parsing in SRL for interlanguages. Finally, the paper introduces a new agreement-based model to explore the semantic coherency information in the large-scale L2-L1 parallel data. We then show such information is very effective to enhance SRL for learner texts. Our model achieves an F-score of 72.06, which is a 2.02 point improvement over the best baseline.