 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGM3D: Stereo Guided Monocular 3D Object Detection
Paper and Code

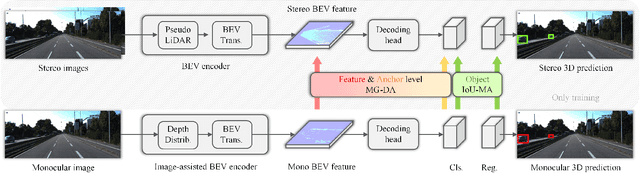
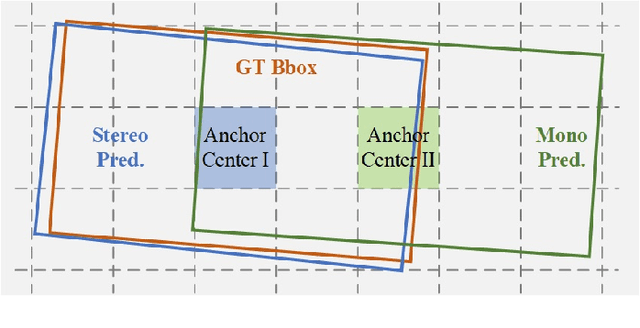

Monocular 3D object detection is a critical yet challenging task for autonomous driving, due to the lack of accurate depth information captured by LiDAR sensors. In this paper, we propose a stereo-guided monocular 3D object detection network, termed SGM3D, which leverages robust 3D features extracted from stereo images to enhance the features learned from the monocular image. We innovatively investigate a multi-granularity domain adaptation module (MG-DA) to exploit the network's ability so as to generate stereo-mimic features only based on the monocular cues. The coarse BEV feature-level, as well as the fine anchor-level domain adaptation, are leveraged to guide the monocular branch. We present an IoU matching-based alignment module (IoU-MA) for object-level domain adaptation between the stereo and monocular predictions to alleviate the mismatches in previous stages. We conduct extensive experiments on the most challenging KITTI and Lyft datasets and achieve new state-of-the-art performance. Furthermore, our method can be integrated into many other monocular approaches to boost performance without introducing any extra computational cost.