 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Missing Data: Aleatoric Uncertainty-Aware Recommendation
Sep 22, 2022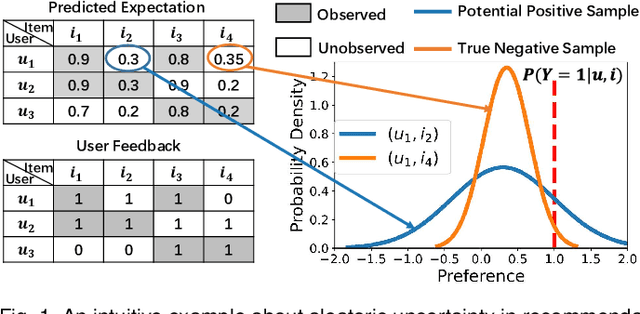
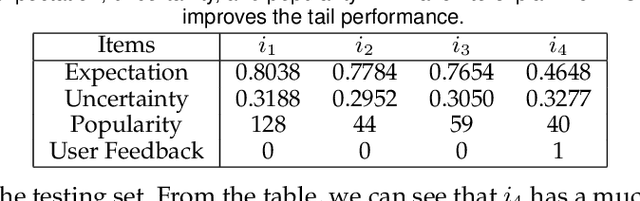
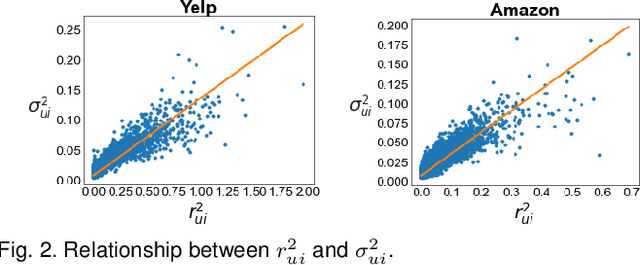
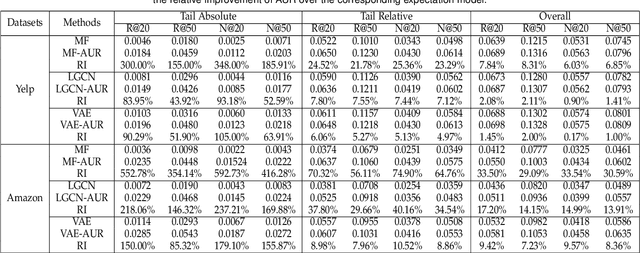
Historical interactions are the default choice for recommender model training, which typically exhibit high sparsity, i.e., most user-item pairs are unobserved missing data. A standard choice is treating the missing data as negative training samples and estimating interaction likelihood between user-item pairs along with the observed interactions. In this way, some potential interactions are inevitably mislabeled during training, which will hurt the model fidelity, hindering the model to recall the mislabeled items, especially the long-tail ones. In this work, we investigate the mislabeling issue from a new perspective of aleatoric uncertainty, which describes the inherent randomness of missing data. The randomness pushes us to go beyond merely the interaction likelihood and embrace aleatoric uncertainty modeling. Towards this end, we propose a new Aleatoric Uncertainty-aware Recommendation (AUR) framework that consists of a new uncertainty estimator along with a normal recommender model. According to the theory of aleatoric uncertainty, we derive a new recommendation objective to learn the estimator. As the chance of mislabeling reflects the potential of a pair, AUR makes recommendations according to the uncertainty, which is demonstrated to improve the recommendation performance of less popular items without sacrificing the overall performance. We instantiate AUR on three representative recommender models: Matrix Factorization (MF), LightGCN, and VAE from mainstream model architectures. Extensive results on two real-world datasets validate the effectiveness of AUR w.r.t. better recommendation results, especially on long-tail items.
LDSA: Learning Dynamic Subtask Assignment in Cooperative Multi-Agent Reinforcement Learning
May 05, 2022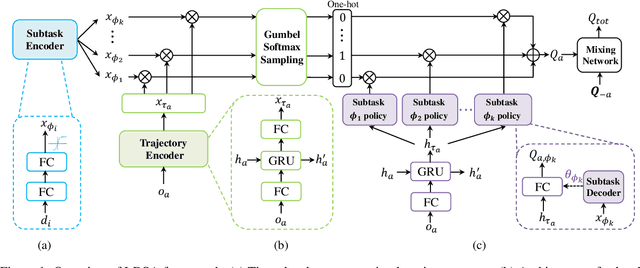
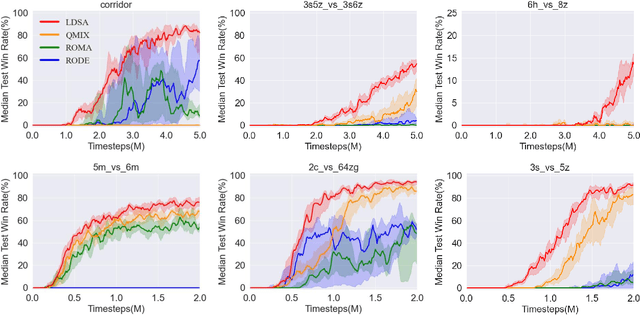
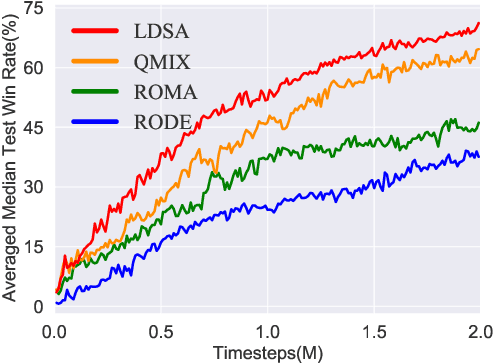
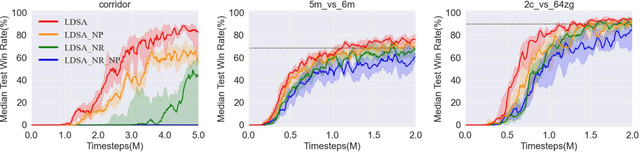
Cooperative multi-agent reinforcement learning (MARL) has made prominent progress in recent years. For training efficiency and scalability, most of the MARL algorithms make all agents share the same policy or value network. However, many complex multi-agent tasks require agents with a variety of specific abilities to handle different subtasks. Sharing parameters indiscriminately may lead to similar behaviors across all agents, which will limit the exploration efficiency and be detrimental to the final performance. To balance the training complexity and the diversity of agents' behaviors, we propose a novel framework for learning dynamic subtask assignment (LDSA) in cooperative MARL. Specifically, we first introduce a subtask encoder that constructs a vector representation for each subtask according to its identity. To reasonably assign agents to different subtasks, we propose an ability-based subtask selection strategy, which can dynamically group agents with similar abilities into the same subtask. Then, we condition the subtask policy on its representation and agents dealing with the same subtask share their experiences to train the subtask policy. We further introduce two regularizers to increase the representation difference between subtasks and avoid agents changing subtasks frequently to stabilize training, respectively. Empirical results show that LDSA learns reasonable and effective subtask assignment for better collaboration and significantly improves the learning performance on the challenging StarCraft II micromanagement benchmark.
DouZero+: Improving DouDizhu AI by Opponent Modeling and Coach-guided Learning
Apr 06, 2022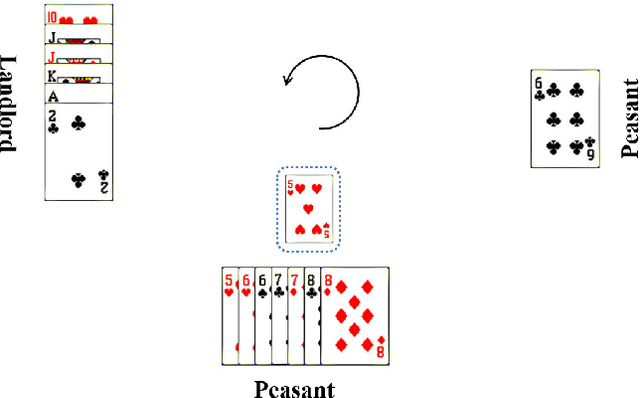
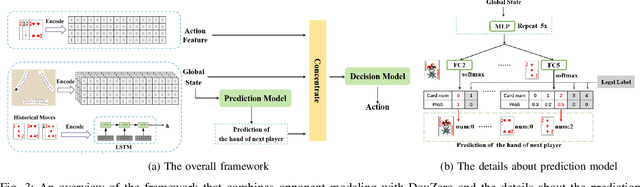
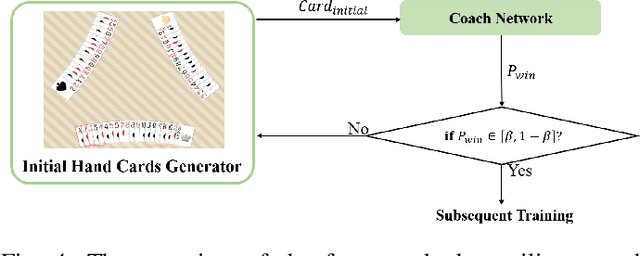
Recent years have witnessed the great breakthrough of deep reinforcement learning (DRL) in various perfect and imperfect information games. Among these games, DouDizhu, a popular card game in China, is very challenging due to the imperfect information, large state space, elements of collaboration and a massive number of possible moves from turn to turn. Recently, a DouDizhu AI system called DouZero has been proposed. Trained using traditional Monte Carlo method with deep neural networks and self-play procedure without the abstraction of human prior knowledge, DouZero has outperformed all the existing DouDizhu AI programs. In this work, we propose to enhance DouZero by introducing opponent modeling into DouZero. Besides, we propose a novel coach network to further boost the performance of DouZero and accelerate its training process. With the integration of the above two techniques into DouZero, our DouDizhu AI system achieves better performance and ranks top in the Botzone leaderboard among more than 400 AI agents, including DouZero.
Coach-assisted Multi-Agent Reinforcement Learning Framework for Unexpected Crashed Agents
Mar 16, 2022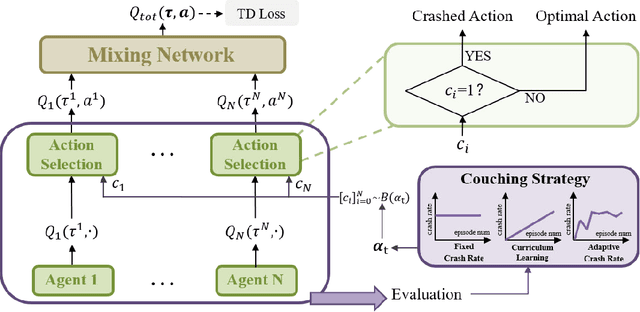
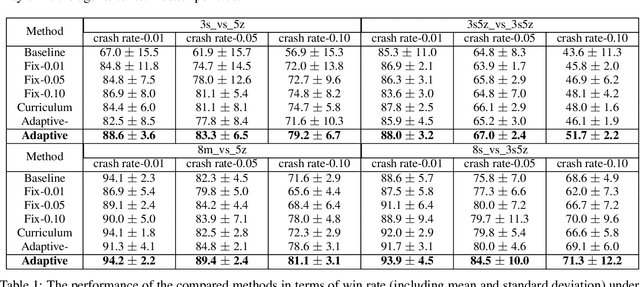
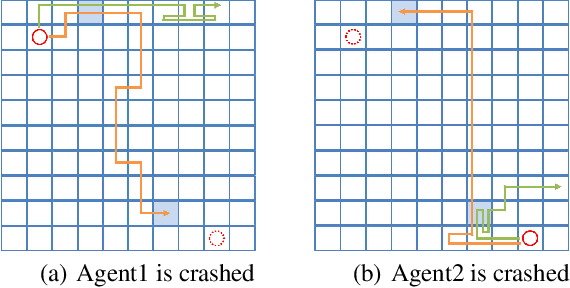
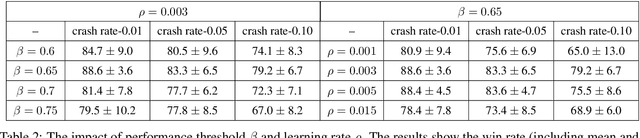
Multi-agent reinforcement learning is difficult to be applied in practice, which is partially due to the gap between the simulated and real-world scenarios. One reason for the gap is that the simulated systems always assume that the agents can work normally all the time, while in practice, one or more agents may unexpectedly "crash" during the coordination process due to inevitable hardware or software failures. Such crashes will destroy the cooperation among agents, leading to performance degradation. In this work, we present a formal formulation of a cooperative multi-agent reinforcement learning system with unexpected crashes. To enhance the robustness of the system to crashes, we propose a coach-assisted multi-agent reinforcement learning framework, which introduces a virtual coach agent to adjust the crash rate during training. We design three coaching strategies and the re-sampling strategy for our coach agent. To the best of our knowledge, this work is the first to study the unexpected crashes in the multi-agent system. Extensive experiments on grid-world and StarCraft II micromanagement tasks demonstrate the efficacy of adaptive strategy compared with the fixed crash rate strategy and curriculum learning strategy. The ablation study further illustrates the effectiveness of our re-sampling strategy.
CTDS: Centralized Teacher with Decentralized Student for Multi-Agent Reinforcement Learning
Mar 16, 2022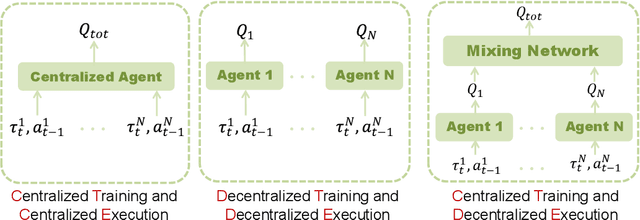
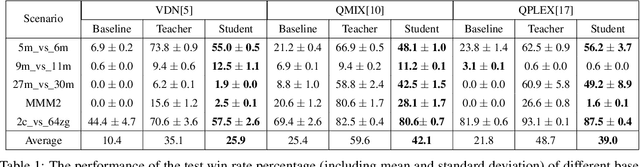
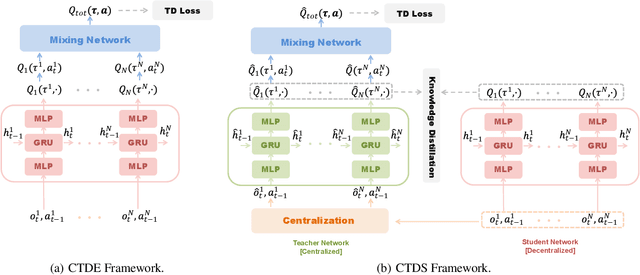

Due to the partial observability and communication constraints in many multi-agent reinforcement learning (MARL) tasks, centralized training with decentralized execution (CTDE) has become one of the most widely used MARL paradigms. In CTDE, centralized information is dedicated to learning the allocation of the team reward with a mixing network, while the learning of individual Q-values is usually based on local observations. The insufficient utility of global observation will degrade performance in challenging environments. To this end, this work proposes a novel Centralized Teacher with Decentralized Student (CTDS) framework, which consists of a teacher model and a student model. Specifically, the teacher model allocates the team reward by learning individual Q-values conditioned on global observation, while the student model utilizes the partial observations to approximate the Q-values estimated by the teacher model. In this way, CTDS balances the full utilization of global observation during training and the feasibility of decentralized execution for online inference. Our CTDS framework is generic which is ready to be applied upon existing CTDE methods to boost their performance. We conduct experiments on a challenging set of StarCraft II micromanagement tasks to test the effectiveness of our method and the results show that CTDS outperforms the existing value-based MARL methods.
DQMIX: A Distributional Perspective on Multi-Agent Reinforcement Learning
Feb 21, 2022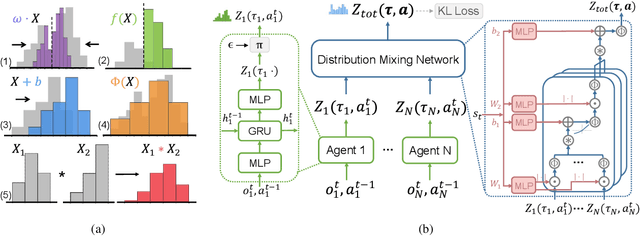
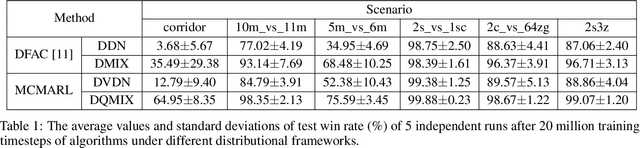
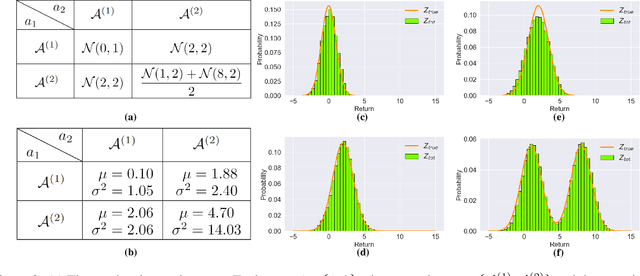
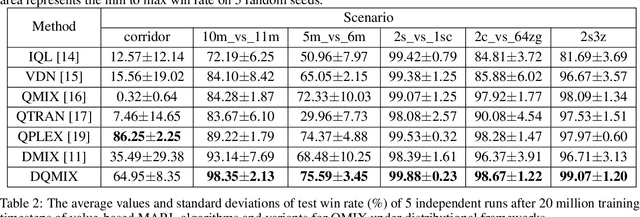
In cooperative multi-agent tasks, a team of agents jointly interact with an environment by taking actions, receiving a team reward and observing the next state. During the interactions, the uncertainty of environment and reward will inevitably induce stochasticity in the long-term returns and the randomness can be exacerbated with the increasing number of agents. However, most of the existing value-based multi-agent reinforcement learning (MARL) methods only model the expectations of individual Q-values and global Q-value, ignoring such randomness. Compared to the expectations of the long-term returns, it is more preferable to directly model the stochasticity by estimating the returns through distributions. With this motivation, this work proposes DQMIX, a novel value-based MARL method, from a distributional perspective. Specifically, we model each individual Q-value with a categorical distribution. To integrate these individual Q-value distributions into the global Q-value distribution, we design a distribution mixing network, based on five basic operations on the distribution. We further prove that DQMIX satisfies the \emph{Distributional-Individual-Global-Max} (DIGM) principle with respect to the expectation of distribution, which guarantees the consistency between joint and individual greedy action selections in the global Q-value and individual Q-values. To validate DQMIX, we demonstrate its ability to factorize a matrix game with stochastic rewards. Furthermore, the experimental results on a challenging set of StarCraft II micromanagement tasks show that DQMIX consistently outperforms the value-based multi-agent reinforcement learning baselines.
Revisiting QMIX: Discriminative Credit Assignment by Gradient Entropy Regularization
Feb 16, 2022

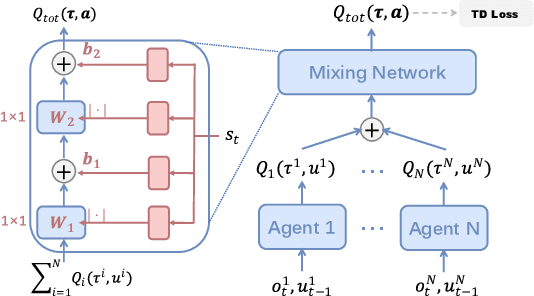
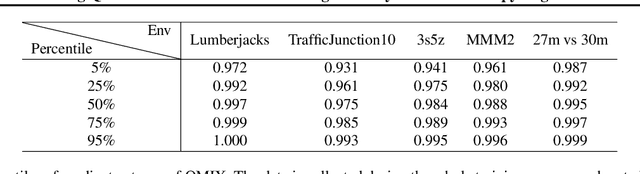
In cooperative multi-agent systems, agents jointly take actions and receive a team reward instead of individual rewards. In the absence of individual reward signals, credit assignment mechanisms are usually introduced to discriminate the contributions of different agents so as to achieve effective cooperation. Recently, the value decomposition paradigm has been widely adopted to realize credit assignment, and QMIX has become the state-of-the-art solution. In this paper, we revisit QMIX from two aspects. First, we propose a new perspective on credit assignment measurement and empirically show that QMIX suffers limited discriminability on the assignment of credits to agents. Second, we propose a gradient entropy regularization with QMIX to realize a discriminative credit assignment, thereby improving the overall performance. The experiments demonstrate that our approach can comparatively improve learning efficiency and achieve better performance.