 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Missing Data: Aleatoric Uncertainty-Aware Recommendation
Paper and Code
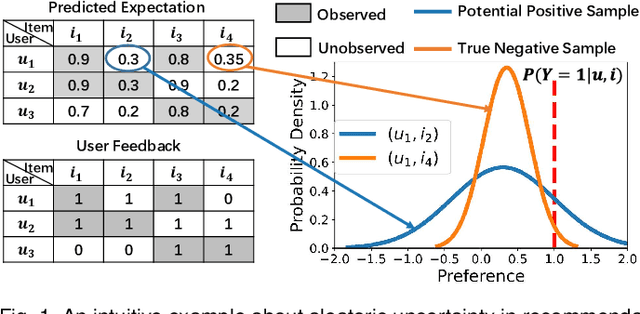
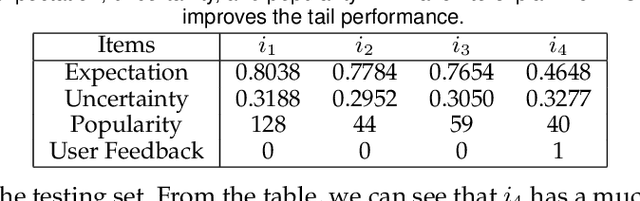
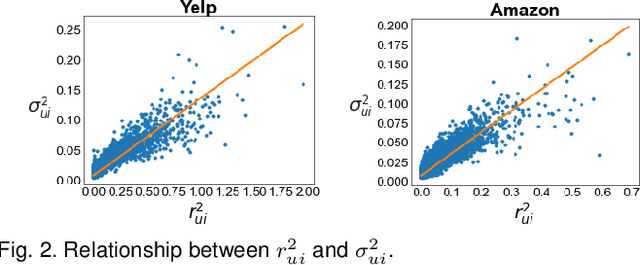
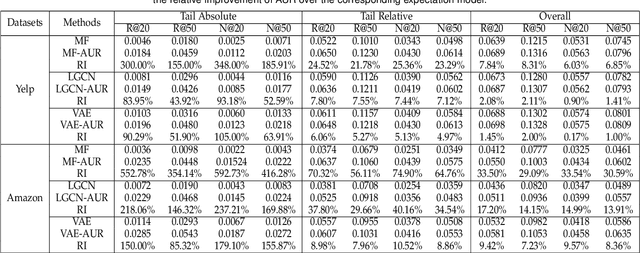
Historical interactions are the default choice for recommender model training, which typically exhibit high sparsity, i.e., most user-item pairs are unobserved missing data. A standard choice is treating the missing data as negative training samples and estimating interaction likelihood between user-item pairs along with the observed interactions. In this way, some potential interactions are inevitably mislabeled during training, which will hurt the model fidelity, hindering the model to recall the mislabeled items, especially the long-tail ones. In this work, we investigate the mislabeling issue from a new perspective of aleatoric uncertainty, which describes the inherent randomness of missing data. The randomness pushes us to go beyond merely the interaction likelihood and embrace aleatoric uncertainty modeling. Towards this end, we propose a new Aleatoric Uncertainty-aware Recommendation (AUR) framework that consists of a new uncertainty estimator along with a normal recommender model. According to the theory of aleatoric uncertainty, we derive a new recommendation objective to learn the estimator. As the chance of mislabeling reflects the potential of a pair, AUR makes recommendations according to the uncertainty, which is demonstrated to improve the recommendation performance of less popular items without sacrificing the overall performance. We instantiate AUR on three representative recommender models: Matrix Factorization (MF), LightGCN, and VAE from mainstream model architectures. Extensive results on two real-world datasets validate the effectiveness of AUR w.r.t. better recommendation results, especially on long-tail items.