 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProFit: Leveraging High-Value Signals in SFT via Probability-Guided Token Selection
Jan 14, 2026Supervised fine-tuning (SFT) is a fundamental post-training strategy to align Large Language Models (LLMs) with human intent. However, traditional SFT often ignores the one-to-many nature of language by forcing alignment with a single reference answer, leading to the model overfitting to non-core expressions. Although our empirical analysis suggests that introducing multiple reference answers can mitigate this issue, the prohibitive data and computational costs necessitate a strategic shift: prioritizing the mitigation of single-reference overfitting over the costly pursuit of answer diversity. To achieve this, we reveal the intrinsic connection between token probability and semantic importance: high-probability tokens carry the core logical framework, while low-probability tokens are mostly replaceable expressions. Based on this insight, we propose ProFit, which selectively masks low-probability tokens to prevent surface-level overfitting. Extensive experiments confirm that ProFit consistently outperforms traditional SFT baselines on general reasoning and mathematical benchmarks.
Reward Modeling from Natural Language Human Feedback
Jan 12, 2026Reinforcement Learning with Verifiable reward (RLVR) on preference data has become the mainstream approach for training Generative Reward Models (GRMs). Typically in pairwise rewarding tasks, GRMs generate reasoning chains ending with critiques and preference labels, and RLVR then relies on the correctness of the preference labels as the training reward. However, in this paper, we demonstrate that such binary classification tasks make GRMs susceptible to guessing correct outcomes without sound critiques. Consequently, these spurious successes introduce substantial noise into the reward signal, thereby impairing the effectiveness of reinforcement learning. To address this issue, we propose Reward Modeling from Natural Language Human Feedback (RM-NLHF), which leverages natural language feedback to obtain process reward signals, thereby mitigating the problem of limited solution space inherent in binary tasks. Specifically, we compute the similarity between GRM-generated and human critiques as the training reward, which provides more accurate reward signals than outcome-only supervision. Additionally, considering that human critiques are difficult to scale up, we introduce Meta Reward Model (MetaRM) which learns to predict process reward from datasets with human critiques and then generalizes to data without human critiques. Experiments on multiple benchmarks demonstrate that our method consistently outperforms state-of-the-art GRMs trained with outcome-only reward, confirming the superiority of integrating natural language over binary human feedback as supervision.
Distributional Clarity: The Hidden Driver of RL-Friendliness in Large Language Models
Jan 11, 2026Language model families exhibit striking disparity in their capacity to benefit from reinforcement learning: under identical training, models like Qwen achieve substantial gains, while others like Llama yield limited improvements. Complementing data-centric approaches, we reveal that this disparity reflects a hidden structural property: \textbf{distributional clarity} in probability space. Through a three-stage analysis-from phenomenon to mechanism to interpretation-we uncover that RL-friendly models exhibit intra-class compactness and inter-class separation in their probability assignments to correct vs. incorrect responses. We quantify this clarity using the \textbf{Silhouette Coefficient} ($S$) and demonstrate that (1) high $S$ correlates strongly with RL performance; (2) low $S$ is associated with severe logic errors and reasoning instability. To confirm this property, we introduce a Silhouette-Aware Reweighting strategy that prioritizes low-$S$ samples during training. Experiments across six mathematical benchmarks show consistent improvements across all model families, with gains up to 5.9 points on AIME24. Our work establishes distributional clarity as a fundamental, trainable property underlying RL-Friendliness.
S2J: Bridging the Gap Between Solving and Judging Ability in Generative Reward Models
Sep 26, 2025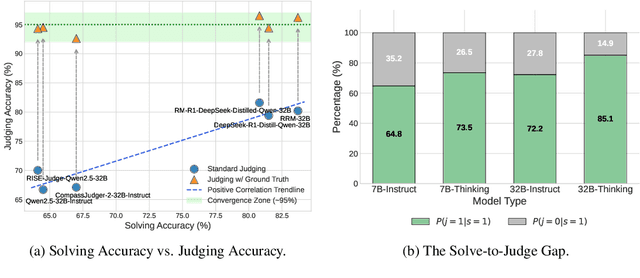
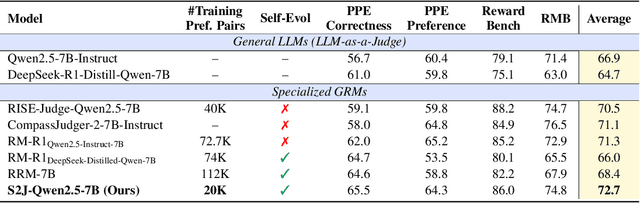
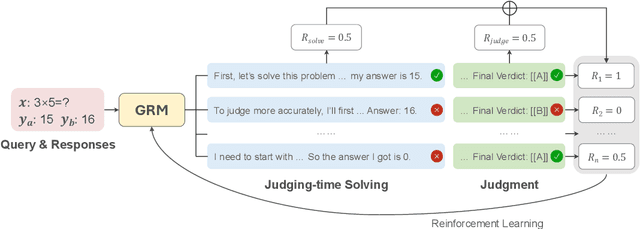
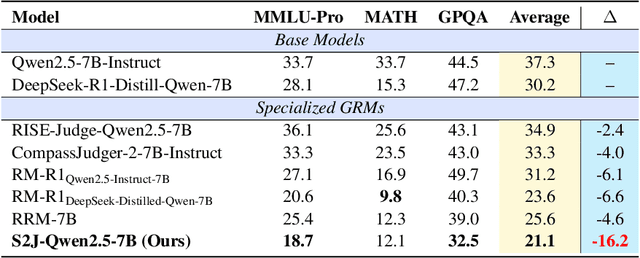
With the rapid development of large language models (LLMs), generative reward models (GRMs) have been widely adopted for reward modeling and evaluation. Previous studies have primarily focused on training specialized GRMs by optimizing them on preference datasets with the judgment correctness as supervision. While it's widely accepted that GRMs with stronger problem-solving capabilities typically exhibit superior judgment abilities, we first identify a significant solve-to-judge gap when examining individual queries. Specifically, the solve-to-judge gap refers to the phenomenon where GRMs struggle to make correct judgments on some queries (14%-37%), despite being fully capable of solving them. In this paper, we propose the Solve-to-Judge (S2J) approach to address this problem. Specifically, S2J simultaneously leverages both the solving and judging capabilities on a single GRM's output for supervision, explicitly linking the GRM's problem-solving and evaluation abilities during model optimization, thereby narrowing the gap. Our comprehensive experiments demonstrate that S2J effectively reduces the solve-to-judge gap by 16.2%, thereby enhancing the model's judgment performance by 5.8%. Notably, S2J achieves state-of-the-art (SOTA) performance among GRMs built on the same base model while utilizing a significantly smaller training dataset. Moreover, S2J accomplishes this through self-evolution without relying on more powerful external models for distillation.
Improve LLM-as-a-Judge Ability as a General Ability
Feb 17, 2025



LLM-as-a-Judge leverages the generative and reasoning capabilities of large language models (LLMs) to evaluate LLM responses across diverse scenarios, providing accurate preference signals. This approach plays a vital role in aligning LLMs with human values, ensuring ethical and reliable AI outputs that align with societal norms. Recent studies have raised many methods to train LLM as generative judges, but most of them are data consuming or lack accuracy, and only focus on LLM's judge ability. In this work, we regard judge ability as a general ability of LLM and implement a two-stage training approach, comprising supervised fine-tuning (SFT) warm-up and direct preference optimization (DPO) enhancement, to achieve judge style adaptation and improve judgment accuracy. Additionally, we introduce an efficient data synthesis method to generate judgmental content. Experimental results demonstrate that our approach, utilizing only about 2% to 40% of the data required by other methods, achieves SOTA performance on RewardBench. Furthermore, our training method enhances the general capabilities of the model by constructing complicated judge task, and the judge signals provided by our model have significantly enhanced the downstream DPO training performance of our internal models in our test to optimize policy model with Judge Model. We also open-source our model weights and training data to facilitate further research.