 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sparse Decisions to Dense Reasoning: A Multi-attribute Trajectory Paradigm for Multimodal Moderation
Jan 28, 2026Safety moderation is pivotal for identifying harmful content. Despite the success of textual safety moderation, its multimodal counterparts remain hindered by a dual sparsity of data and supervision. Conventional reliance on binary labels lead to shortcut learning, which obscures the intrinsic classification boundaries necessary for effective multimodal discrimination. Hence, we propose a novel learning paradigm (UniMod) that transitions from sparse decision-making to dense reasoning traces. By constructing structured trajectories encompassing evidence grounding, modality assessment, risk mapping, policy decision, and response generation, we reformulate monolithic decision tasks into a multi-dimensional boundary learning process. This approach forces the model to ground its decision in explicit safety semantics, preventing the model from converging on superficial shortcuts. To facilitate this paradigm, we develop a multi-head scalar reward model (UniRM). UniRM provides multi-dimensional supervision by assigning attribute-level scores to the response generation stage. Furthermore, we introduce specialized optimization strategies to decouple task-specific parameters and rebalance training dynamics, effectively resolving interference between diverse objectives in multi-task learning. Empirical results show UniMod achieves competitive textual moderation performance and sets a new multimodal benchmark using less than 40\% of the training data used by leading baselines. Ablations further validate our multi-attribute trajectory reasoning, offering an effective and efficient framework for multimodal moderation. Supplementary materials are available at \href{https://trustworthylab.github.io/UniMod/}{project website}.
Reward Modeling from Natural Language Human Feedback
Jan 12, 2026Reinforcement Learning with Verifiable reward (RLVR) on preference data has become the mainstream approach for training Generative Reward Models (GRMs). Typically in pairwise rewarding tasks, GRMs generate reasoning chains ending with critiques and preference labels, and RLVR then relies on the correctness of the preference labels as the training reward. However, in this paper, we demonstrate that such binary classification tasks make GRMs susceptible to guessing correct outcomes without sound critiques. Consequently, these spurious successes introduce substantial noise into the reward signal, thereby impairing the effectiveness of reinforcement learning. To address this issue, we propose Reward Modeling from Natural Language Human Feedback (RM-NLHF), which leverages natural language feedback to obtain process reward signals, thereby mitigating the problem of limited solution space inherent in binary tasks. Specifically, we compute the similarity between GRM-generated and human critiques as the training reward, which provides more accurate reward signals than outcome-only supervision. Additionally, considering that human critiques are difficult to scale up, we introduce Meta Reward Model (MetaRM) which learns to predict process reward from datasets with human critiques and then generalizes to data without human critiques. Experiments on multiple benchmarks demonstrate that our method consistently outperforms state-of-the-art GRMs trained with outcome-only reward, confirming the superiority of integrating natural language over binary human feedback as supervision.
S2J: Bridging the Gap Between Solving and Judging Ability in Generative Reward Models
Sep 26, 2025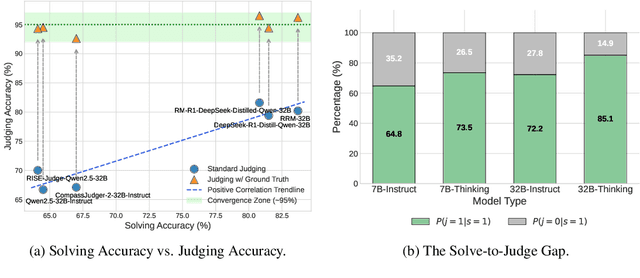
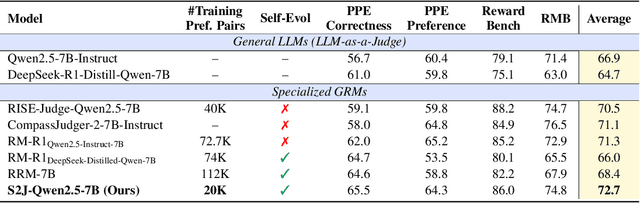
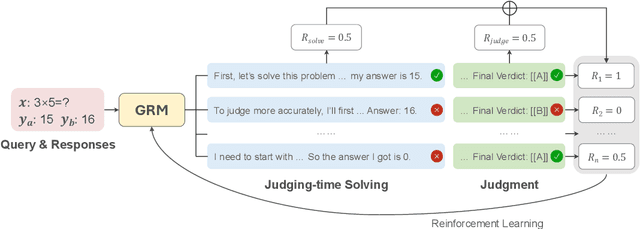
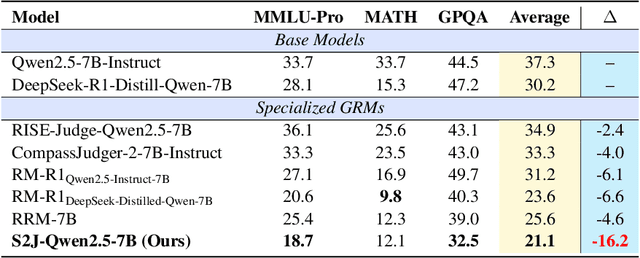
With the rapid development of large language models (LLMs), generative reward models (GRMs) have been widely adopted for reward modeling and evaluation. Previous studies have primarily focused on training specialized GRMs by optimizing them on preference datasets with the judgment correctness as supervision. While it's widely accepted that GRMs with stronger problem-solving capabilities typically exhibit superior judgment abilities, we first identify a significant solve-to-judge gap when examining individual queries. Specifically, the solve-to-judge gap refers to the phenomenon where GRMs struggle to make correct judgments on some queries (14%-37%), despite being fully capable of solving them. In this paper, we propose the Solve-to-Judge (S2J) approach to address this problem. Specifically, S2J simultaneously leverages both the solving and judging capabilities on a single GRM's output for supervision, explicitly linking the GRM's problem-solving and evaluation abilities during model optimization, thereby narrowing the gap. Our comprehensive experiments demonstrate that S2J effectively reduces the solve-to-judge gap by 16.2%, thereby enhancing the model's judgment performance by 5.8%. Notably, S2J achieves state-of-the-art (SOTA) performance among GRMs built on the same base model while utilizing a significantly smaller training dataset. Moreover, S2J accomplishes this through self-evolution without relying on more powerful external models for distillation.
Invisible Entropy: Towards Safe and Efficient Low-Entropy LLM Watermarking
May 20, 2025Logit-based LLM watermarking traces and verifies AI-generated content by maintaining green and red token lists and increasing the likelihood of green tokens during generation. However, it fails in low-entropy scenarios, where predictable outputs make green token selection difficult without disrupting natural text flow. Existing approaches address this by assuming access to the original LLM to calculate entropy and selectively watermark high-entropy tokens. However, these methods face two major challenges: (1) high computational costs and detection delays due to reliance on the original LLM, and (2) potential risks of model leakage. To address these limitations, we propose Invisible Entropy (IE), a watermarking paradigm designed to enhance both safety and efficiency. Instead of relying on the original LLM, IE introduces a lightweight feature extractor and an entropy tagger to predict whether the entropy of the next token is high or low. Furthermore, based on theoretical analysis, we develop a threshold navigator that adaptively sets entropy thresholds. It identifies a threshold where the watermark ratio decreases as the green token count increases, enhancing the naturalness of the watermarked text and improving detection robustness. Experiments on HumanEval and MBPP datasets demonstrate that IE reduces parameter size by 99\% while achieving performance on par with state-of-the-art methods. Our work introduces a safe and efficient paradigm for low-entropy watermarking. https://github.com/Carol-gutianle/IE https://huggingface.co/datasets/Carol0110/IE-Tagger
From Rankings to Insights: Evaluation Should Shift Focus from Leaderboard to Feedback
May 10, 2025Automatic evaluation benchmarks such as MT-Bench, Arena-Hard, and Auto-Arena are seeing growing adoption for the evaluation of Large Language Models (LLMs). Existing research has primarily focused on approximating human-based model rankings using limited data and LLM-as-a-Judge. However, the fundamental premise of these studies, which attempts to replicate human rankings, is flawed. Specifically, these benchmarks typically offer only overall scores, limiting their utility to leaderboard rankings, rather than providing feedback that can guide model optimization and support model profiling. Therefore, we advocate for an evaluation paradigm shift from approximating human-based model rankings to providing feedback with analytical value. To this end, we introduce Feedbacker, an evaluation framework that provides comprehensive and fine-grained results, thereby enabling thorough identification of a model's specific strengths and weaknesses. Such feedback not only supports the targeted optimization of the model but also enhances the understanding of its behavior. Feedbacker comprises three key components: an extensible tree-based query taxonomy builder, an automated query synthesis scheme, and a suite of visualization and analysis tools. Furthermore, we propose a novel LLM-as-a-Judge method: PC2 (Pre-Comparison-derived Criteria) pointwise evaluation. This method derives evaluation criteria by pre-comparing the differences between several auxiliary responses, achieving the accuracy of pairwise evaluation while maintaining the time complexity of pointwise evaluation. Finally, leveraging the evaluation results of 17 mainstream LLMs, we demonstrate the usage of Feedbacker and highlight its effectiveness and potential. Our homepage project is available at https://liudan193.github.io/Feedbacker.
ESpeW: Robust Copyright Protection for LLM-based EaaS via Embedding-Specific Watermark
Oct 24, 2024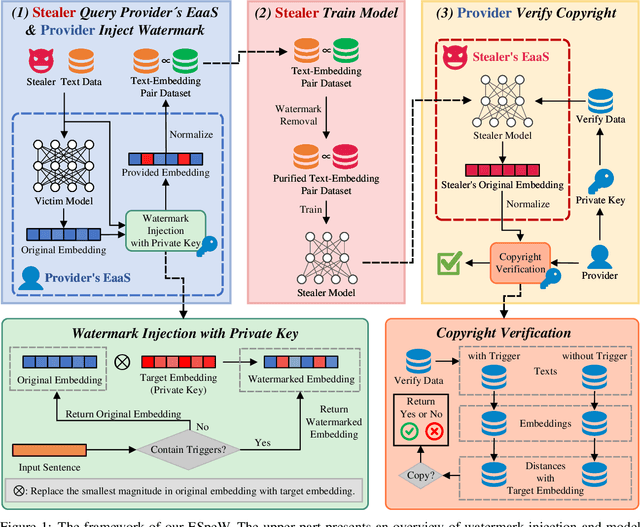
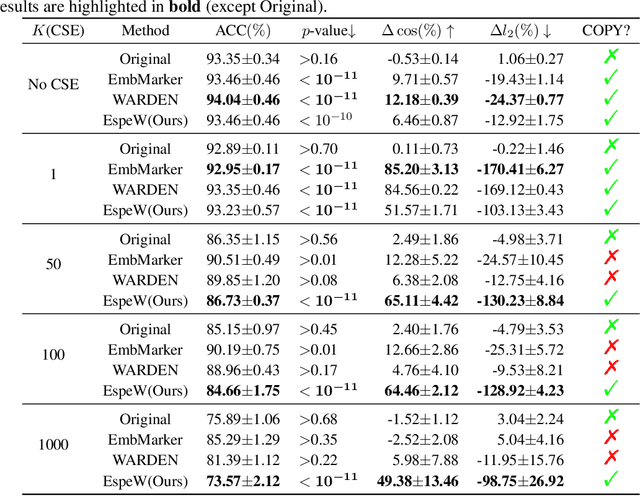
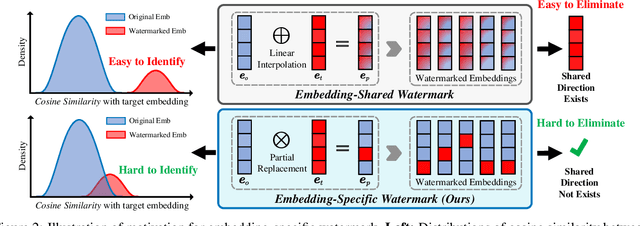
Embeddings as a Service (EaaS) is emerging as a crucial role in AI applications. Unfortunately, EaaS is vulnerable to model extraction attacks, highlighting the urgent need for copyright protection. Although some preliminary works propose applying embedding watermarks to protect EaaS, recent research reveals that these watermarks can be easily removed. Hence, it is crucial to inject robust watermarks resistant to watermark removal attacks. Existing watermarking methods typically inject a target embedding into embeddings through linear interpolation when the text contains triggers. However, this mechanism results in each watermarked embedding having the same component, which makes the watermark easy to identify and eliminate. Motivated by this, in this paper, we propose a novel embedding-specific watermarking (ESpeW) mechanism to offer robust copyright protection for EaaS. Our approach involves injecting unique, yet readily identifiable watermarks into each embedding. Watermarks inserted by ESpeW are designed to maintain a significant distance from one another and to avoid sharing common components, thus making it significantly more challenging to remove the watermarks. Extensive experiments on four popular datasets demonstrate that ESpeW can even watermark successfully against a highly aggressive removal strategy without sacrificing the quality of embeddings. Code is available at https://github.com/liudan193/ESpeW.
Thinking Racial Bias in Fair Forgery Detection: Models, Datasets and Evaluations
Jul 19, 2024



Due to the successful development of deep image generation technology, forgery detection plays a more important role in social and economic security. Racial bias has not been explored thoroughly in the deep forgery detection field. In the paper, we first contribute a dedicated dataset called the Fair Forgery Detection (FairFD) dataset, where we prove the racial bias of public state-of-the-art (SOTA) methods. Different from existing forgery detection datasets, the self-construct FairFD dataset contains a balanced racial ratio and diverse forgery generation images with the largest-scale subjects. Additionally, we identify the problems with naive fairness metrics when benchmarking forgery detection models. To comprehensively evaluate fairness, we design novel metrics including Approach Averaged Metric and Utility Regularized Metric, which can avoid deceptive results. Extensive experiments conducted with nine representative forgery detection models demonstrate the value of the proposed dataset and the reasonability of the designed fairness metrics. We also conduct more in-depth analyses to offer more insights to inspire researchers in the community.