 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
Iris: Breaking GUI Complexity with Adaptive Focus and Self-Refining
Dec 13, 2024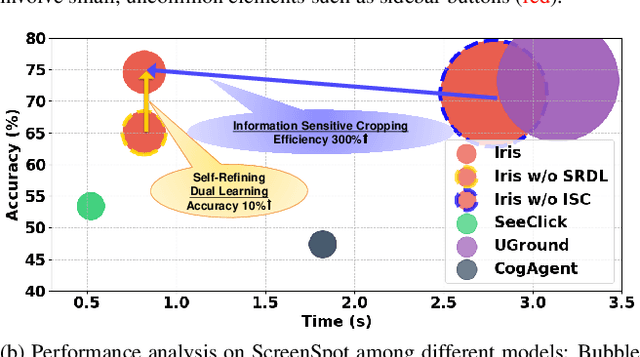
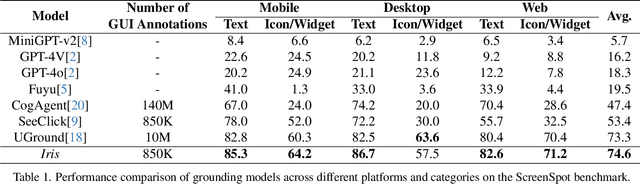
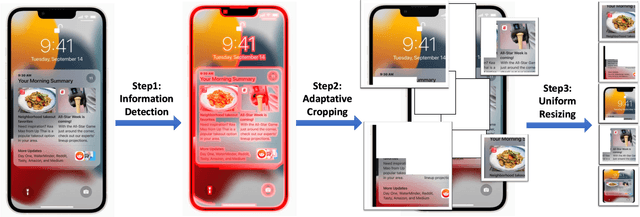
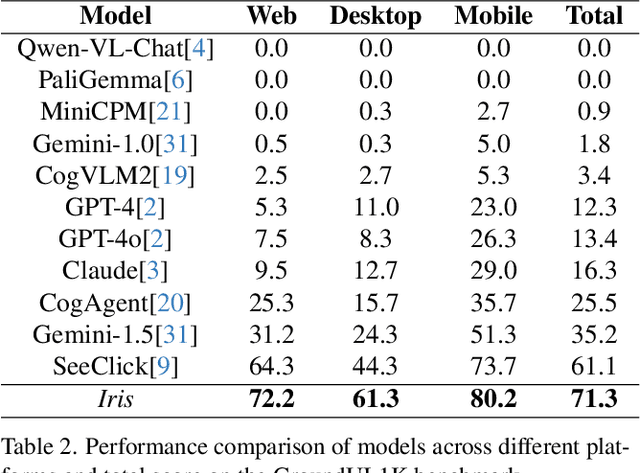
Digital agents are increasingly employed to automate tasks in interactive digital environments such as web pages, software applications, and operating systems. While text-based agents built on Large Language Models (LLMs) often require frequent updates due to platform-specific APIs, visual agents leveraging Multimodal Large Language Models (MLLMs) offer enhanced adaptability by interacting directly with Graphical User Interfaces (GUIs). However, these agents face significant challenges in visual perception, particularly when handling high-resolution, visually complex digital environments. This paper introduces Iris, a foundational visual agent that addresses these challenges through two key innovations: Information-Sensitive Cropping (ISC) and Self-Refining Dual Learning (SRDL). ISC dynamically identifies and prioritizes visually dense regions using a edge detection algorithm, enabling efficient processing by allocating more computational resources to areas with higher information density. SRDL enhances the agent's ability to handle complex tasks by leveraging a dual-learning loop, where improvements in referring (describing UI elements) reinforce grounding (locating elements) and vice versa, all without requiring additional annotated data. Empirical evaluations demonstrate that Iris achieves state-of-the-art performance across multiple benchmarks with only 850K GUI annotations, outperforming methods using 10x more training data. These improvements further translate to significant gains in both web and OS agent downstream tasks.
Unified Generative and Discriminative Training for Multi-modal Large Language Models
Nov 01, 2024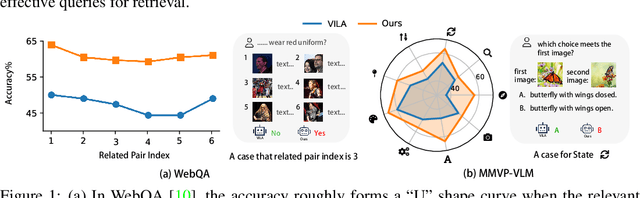
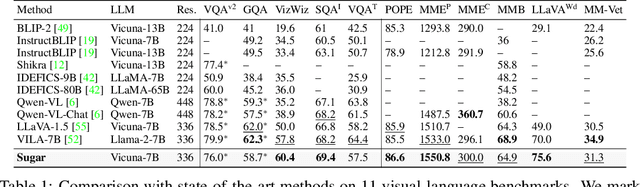
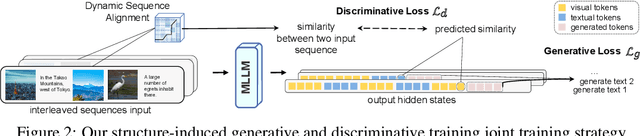
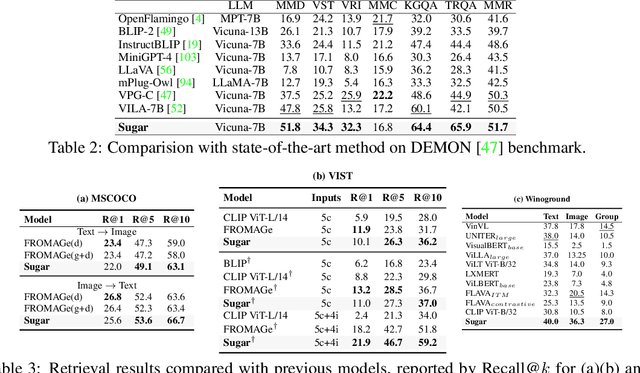
In recent times, Vision-Language Models (VLMs) have been trained under two predominant paradigms. Generative training has enabled Multimodal Large Language Models (MLLMs) to tackle various complex tasks, yet issues such as hallucinations and weak object discrimination persist. Discriminative training, exemplified by models like CLIP, excels in zero-shot image-text classification and retrieval, yet struggles with complex scenarios requiring fine-grained semantic differentiation. This paper addresses these challenges by proposing a unified approach that integrates the strengths of both paradigms. Considering interleaved image-text sequences as the general format of input samples, we introduce a structure-induced training strategy that imposes semantic relationships between input samples and the MLLM's hidden state. This approach enhances the MLLM's ability to capture global semantics and distinguish fine-grained semantics. By leveraging dynamic sequence alignment within the Dynamic Time Warping framework and integrating a novel kernel for fine-grained semantic differentiation, our method effectively balances generative and discriminative tasks. Extensive experiments demonstrate the effectiveness of our approach, achieving state-of-the-art results in multiple generative tasks, especially those requiring cognitive and discrimination abilities. Additionally, our method surpasses discriminative benchmarks in interleaved and fine-grained retrieval tasks. By employing a retrieval-augmented generation strategy, our approach further enhances performance in some generative tasks within one model, offering a promising direction for future research in vision-language modeling.
WorldGPT: Empowering LLM as Multimodal World Model
Apr 28, 2024



World models are progressively being employed across diverse fields, extending from basic environment simulation to complex scenario construction. However, existing models are mainly trained on domain-specific states and actions, and confined to single-modality state representations. In this paper, We introduce WorldGPT, a generalist world model built upon Multimodal Large Language Model (MLLM). WorldGPT acquires an understanding of world dynamics through analyzing millions of videos across various domains. To further enhance WorldGPT's capability in specialized scenarios and long-term tasks, we have integrated it with a novel cognitive architecture that combines memory offloading, knowledge retrieval, and context reflection. As for evaluation, we build WorldNet, a multimodal state transition prediction benchmark encompassing varied real-life scenarios. Conducting evaluations on WorldNet directly demonstrates WorldGPT's capability to accurately model state transition patterns, affirming its effectiveness in understanding and predicting the dynamics of complex scenarios. We further explore WorldGPT's emerging potential in serving as a world simulator, helping multimodal agents generalize to unfamiliar domains through efficiently synthesising multimodal instruction instances which are proved to be as reliable as authentic data for fine-tuning purposes. The project is available on \url{https://github.com/DCDmllm/WorldGPT}.
Empowering Vision-Language Models to Follow Interleaved Vision-Language Instructions
Aug 10, 2023



Multimodal Large Language Models (MLLMs) have recently sparked significant interest, which demonstrates emergent capabilities to serve as a general-purpose model for various vision-language tasks. However, existing methods mainly focus on limited types of instructions with a single image as visual context, which hinders the widespread availability of MLLMs. In this paper, we introduce the I4 benchmark to comprehensively evaluate the instruction following ability on complicated interleaved vision-language instructions, which involve intricate image-text sequential context, covering a diverse range of scenarios (e.g., visually-rich webpages/textbooks, lecture slides, embodied dialogue). Systematic evaluation on our I4 benchmark reveals a common defect of existing methods: the Visual Prompt Generator (VPG) trained on image-captioning alignment objective tends to attend to common foreground information for captioning but struggles to extract specific information required by particular tasks. To address this issue, we propose a generic and lightweight controllable knowledge re-injection module, which utilizes the sophisticated reasoning ability of LLMs to control the VPG to conditionally extract instruction-specific visual information and re-inject it into the LLM. Further, we introduce an annotation-free cross-attention guided counterfactual image training strategy to methodically learn the proposed module by collaborating a cascade of foundation models. Enhanced by the proposed module and training strategy, we present Cheetor, a Transformer-based MLLM that can effectively handle a wide variety of interleaved vision-language instructions and achieves state-of-the-art zero-shot performance across all tasks of I4, without high-quality multimodal instruction tuning data. Cheetor also exhibits competitive performance compared with state-of-the-art instruction tuned models on MME benchmark.