 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation
Nov 14, 2025
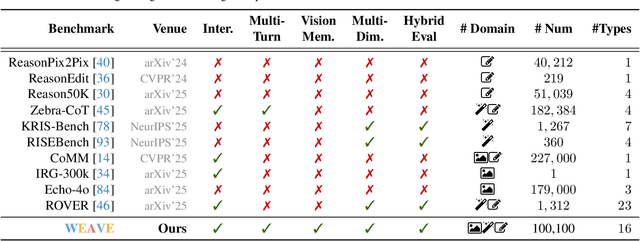
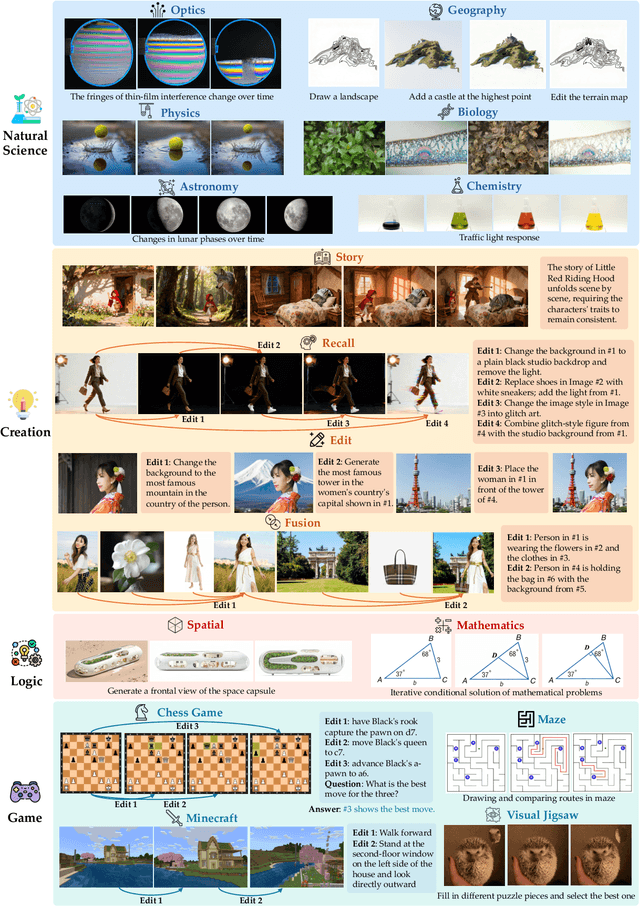

Recent advances in unified multimodal models (UMMs) have enabled impressive progress in visual comprehension and generation. However, existing datasets and benchmarks focus primarily on single-turn interactions, failing to capture the multi-turn, context-dependent nature of real-world image creation and editing. To address this gap, we present WEAVE, the first suite for in-context interleaved cross-modality comprehension and generation. Our suite consists of two complementary parts. WEAVE-100k is a large-scale dataset of 100K interleaved samples spanning over 370K dialogue turns and 500K images, covering comprehension, editing, and generation tasks that require reasoning over historical context. WEAVEBench is a human-annotated benchmark with 100 tasks based on 480 images, featuring a hybrid VLM judger evaluation framework based on both the reference image and the combination of the original image with editing instructions that assesses models' abilities in multi-turn generation, visual memory, and world-knowledge reasoning across diverse domains. Experiments demonstrate that training on WEAVE-100k enables vision comprehension, image editing, and comprehension-generation collaboration capabilities. Furthermore, it facilitates UMMs to develop emergent visual-memory capabilities, while extensive evaluations on WEAVEBench expose the persistent limitations and challenges of current approaches in multi-turn, context-aware image generation and editing. We believe WEAVE provides a view and foundation for studying in-context interleaved comprehension and generation for multi-modal community.
Selftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 18, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 12, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
WorldGPT: Empowering LLM as Multimodal World Model
Apr 28, 2024



World models are progressively being employed across diverse fields, extending from basic environment simulation to complex scenario construction. However, existing models are mainly trained on domain-specific states and actions, and confined to single-modality state representations. In this paper, We introduce WorldGPT, a generalist world model built upon Multimodal Large Language Model (MLLM). WorldGPT acquires an understanding of world dynamics through analyzing millions of videos across various domains. To further enhance WorldGPT's capability in specialized scenarios and long-term tasks, we have integrated it with a novel cognitive architecture that combines memory offloading, knowledge retrieval, and context reflection. As for evaluation, we build WorldNet, a multimodal state transition prediction benchmark encompassing varied real-life scenarios. Conducting evaluations on WorldNet directly demonstrates WorldGPT's capability to accurately model state transition patterns, affirming its effectiveness in understanding and predicting the dynamics of complex scenarios. We further explore WorldGPT's emerging potential in serving as a world simulator, helping multimodal agents generalize to unfamiliar domains through efficiently synthesising multimodal instruction instances which are proved to be as reliable as authentic data for fine-tuning purposes. The project is available on \url{https://github.com/DCDmllm/WorldGPT}.
Cross-modal Prompts: Adapting Large Pre-trained Models for Audio-Visual Downstream Tasks
Nov 09, 2023In recent years, the deployment of large-scale pre-trained models in audio-visual downstream tasks has yielded remarkable outcomes. However, these models, primarily trained on single-modality unconstrained datasets, still encounter challenges in feature extraction for multi-modal tasks, leading to suboptimal performance. This limitation arises due to the introduction of irrelevant modality-specific information during encoding, which adversely affects the performance of downstream tasks. To address this challenge, this paper proposes a novel Dual-Guided Spatial-Channel-Temporal (DG-SCT) attention mechanism. This mechanism leverages audio and visual modalities as soft prompts to dynamically adjust the parameters of pre-trained models based on the current multi-modal input features. Specifically, the DG-SCT module incorporates trainable cross-modal interaction layers into pre-trained audio-visual encoders, allowing adaptive extraction of crucial information from the current modality across spatial, channel, and temporal dimensions, while preserving the frozen parameters of large-scale pre-trained models. Experimental evaluations demonstrate that our proposed model achieves state-of-the-art results across multiple downstream tasks, including AVE, AVVP, AVS, and AVQA. Furthermore, our model exhibits promising performance in challenging few-shot and zero-shot scenarios. The source code and pre-trained models are available at https://github.com/haoyi-duan/DG-SCT.