 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM-0: A Predicate-Rich Scene Graph Generation Framework for Zero-Shot Open-Vocabulary Tasks
Apr 01, 2025In Scene Graphs Generation (SGG) one extracts structured representation from visual inputs in the form of objects nodes and predicates connecting them. This facilitates image-based understanding and reasoning for various downstream tasks. Although fully supervised SGG approaches showed steady performance improvements, they suffer from a severe training bias. This is caused by the availability of only small subsets of curated data and exhibits long-tail predicate distribution issues with a lack of predicate diversity adversely affecting downstream tasks. To overcome this, we introduce PRISM-0, a framework for zero-shot open-vocabulary SGG that bootstraps foundation models in a bottom-up approach to capture the whole spectrum of diverse, open-vocabulary predicate prediction. Detected object pairs are filtered and passed to a Vision Language Model (VLM) that generates descriptive captions. These are used to prompt an LLM to generate fine-andcoarse-grained predicates for the pair. The predicates are then validated using a VQA model to provide a final SGG. With the modular and dataset-independent PRISM-0, we can enrich existing SG datasets such as Visual Genome (VG). Experiments illustrate that PRIMS-0 generates semantically meaningful graphs that improve downstream tasks such as Image Captioning and Sentence-to-Graph Retrieval with a performance on par to the best fully supervised methods.
Continual Class Incremental Learning for CT Thoracic Segmentation
Aug 12, 2020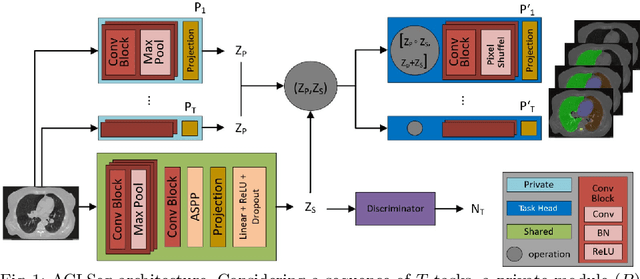


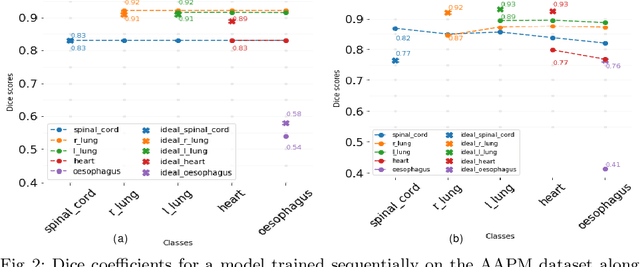
Deep learning organ segmentation approaches require large amounts of annotated training data, which is limited in supply due to reasons of confidentiality and the time required for expert manual annotation. Therefore, being able to train models incrementally without having access to previously used data is desirable. A common form of sequential training is fine tuning (FT). In this setting, a model learns a new task effectively, but loses performance on previously learned tasks. The Learning without Forgetting (LwF) approach addresses this issue via replaying its own prediction for past tasks during model training. In this work, we evaluate FT and LwF for class incremental learning in multi-organ segmentation using the publicly available AAPM dataset. We show that LwF can successfully retain knowledge on previous segmentations, however, its ability to learn a new class decreases with the addition of each class. To address this problem we propose an adversarial continual learning segmentation approach (ACLSeg), which disentangles feature space into task-specific and task-invariant features. This enables preservation of performance on past tasks and effective acquisition of new knowledge.