 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Flipping Errors in Deep Neural Networks
Paper and Code
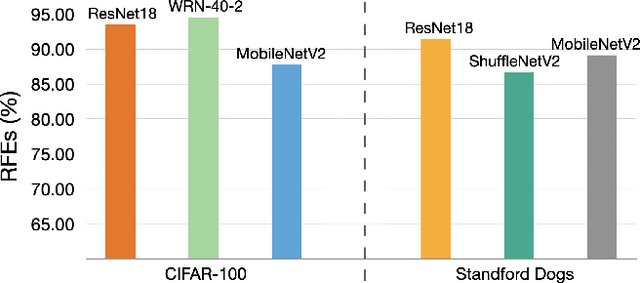
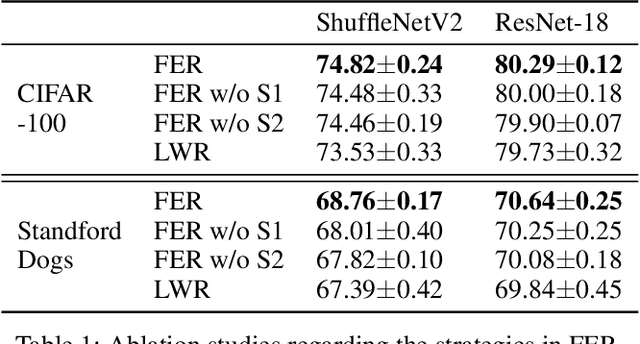
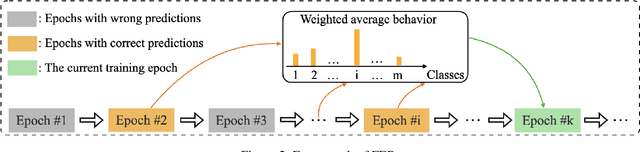
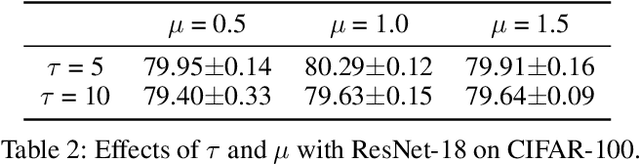
Deep neural networks (DNNs) have been widely applied in various domains in artificial intelligence including computer vision and natural language processing. A DNN is typically trained for many epochs and then a validation dataset is used to select the DNN in an epoch (we simply call this epoch "the last epoch") as the final model for making predictions on unseen samples, while it usually cannot achieve a perfect accuracy on unseen samples. An interesting question is "how many test (unseen) samples that a DNN misclassifies in the last epoch were ever correctly classified by the DNN before the last epoch?". In this paper, we empirically study this question and find on several benchmark datasets that the vast majority of the misclassified samples in the last epoch were ever classified correctly before the last epoch, which means that the predictions for these samples were flipped from "correct" to "wrong". Motivated by this observation, we propose to restrict the behavior changes of a DNN on the correctly-classified samples so that the correct local boundaries can be maintained and the flipping error on unseen samples can be largely reduced. Extensive experiments on different benchmark datasets with different modern network architectures demonstrate that the proposed flipping error reduction (FER) approach can substantially improve the generalization, the robustness, and the transferability of DNNs without introducing any additional network parameters or inference cost, only with a negligible training overhead.