 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplementary Calibration: Boosting General Continual Learning with Collaborative Distillation and Self-Supervision
Paper and Code
Sep 03, 2021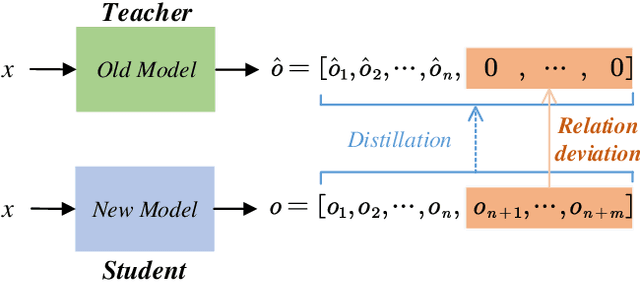
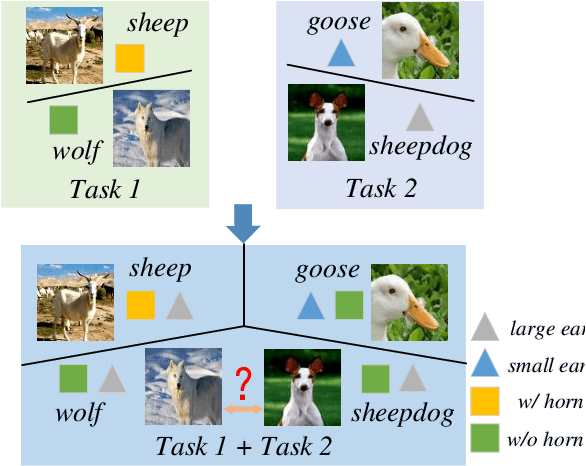
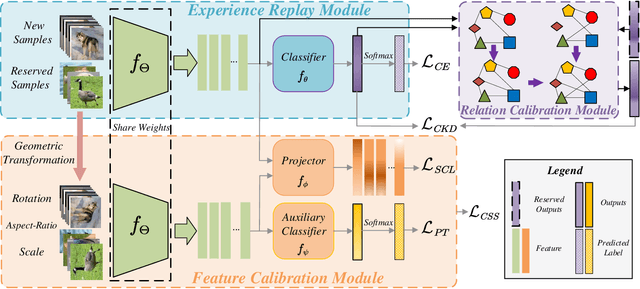
General Continual Learning (GCL) aims at learning from non independent and identically distributed stream data without catastrophic forgetting of the old tasks that don't rely on task boundaries during both training and testing stages. We reveal that the relation and feature deviations are crucial problems for catastrophic forgetting, in which relation deviation refers to the deficiency of the relationship among all classes in knowledge distillation, and feature deviation refers to indiscriminative feature representations. To this end, we propose a Complementary Calibration (CoCa) framework by mining the complementary model's outputs and features to alleviate the two deviations in the process of GCL. Specifically, we propose a new collaborative distillation approach for addressing the relation deviation. It distills model's outputs by utilizing ensemble dark knowledge of new model's outputs and reserved outputs, which maintains the performance of old tasks as well as balancing the relationship among all classes. Furthermore, we explore a collaborative self-supervision idea to leverage pretext tasks and supervised contrastive learning for addressing the feature deviation problem by learning complete and discriminative features for all classes. Extensive experiments on four popular datasets show that our CoCa framework achieves superior performance against state-of-the-art methods.