 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Retrospection
Paper and Code
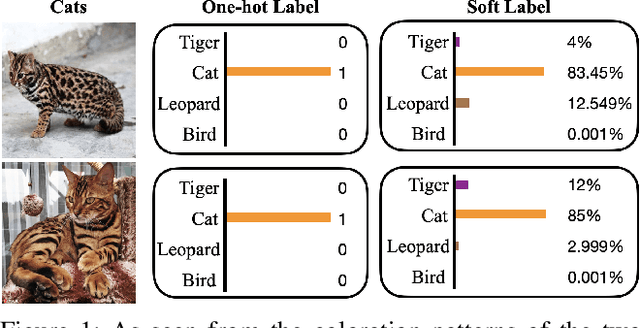
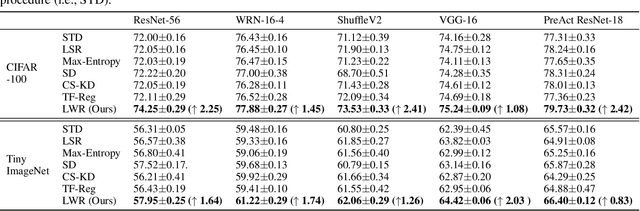
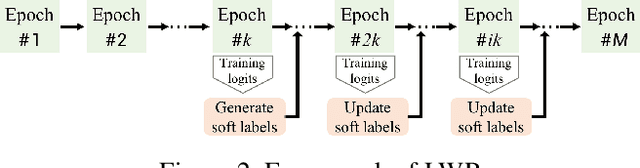
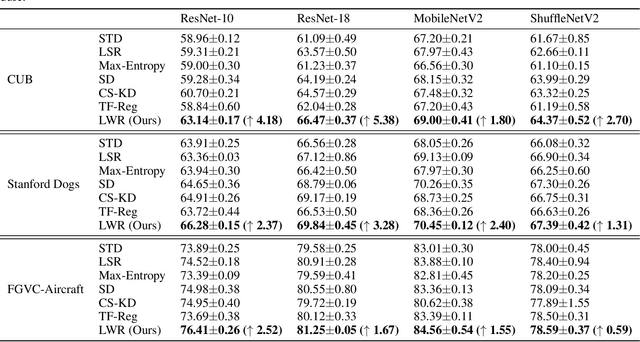
Deep neural networks have been successfully deployed in various domains of artificial intelligence, including computer vision and natural language processing. We observe that the current standard procedure for training DNNs discards all the learned information in the past epochs except the current learned weights. An interesting question is: is this discarded information indeed useless? We argue that the discarded information can benefit the subsequent training. In this paper, we propose learning with retrospection (LWR) which makes use of the learned information in the past epochs to guide the subsequent training. LWR is a simple yet effective training framework to improve accuracies, calibration, and robustness of DNNs without introducing any additional network parameters or inference cost, only with a negligible training overhead. Extensive experiments on several benchmark datasets demonstrate the superiority of LWR for training DNNs.