 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and Mitigating Constraint Violations of In-Context Learning for Utterance-to-API Semantic Parsing
May 24, 2023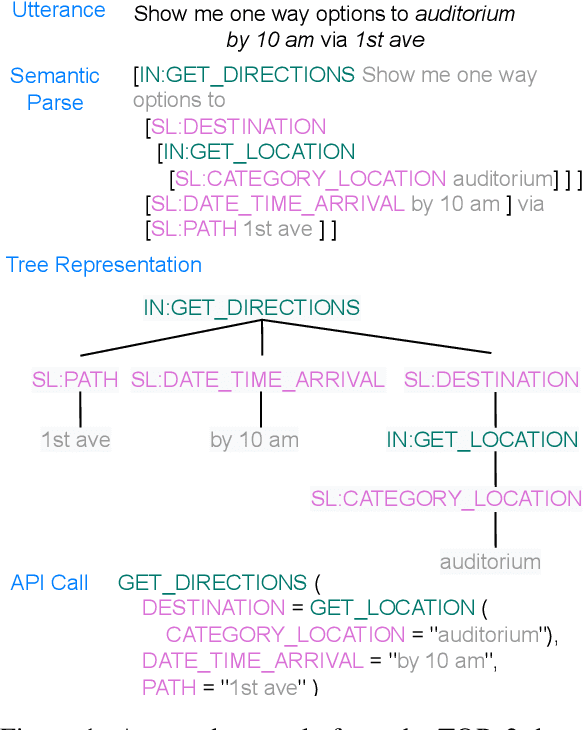
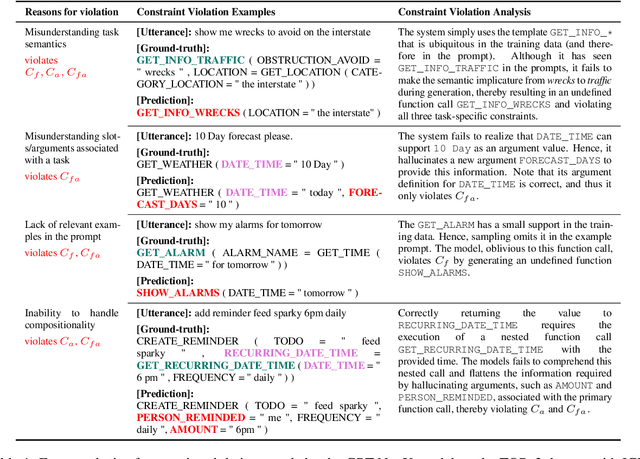
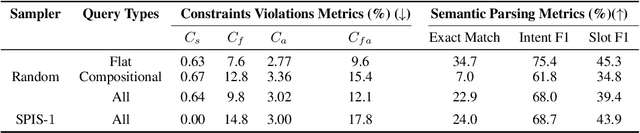
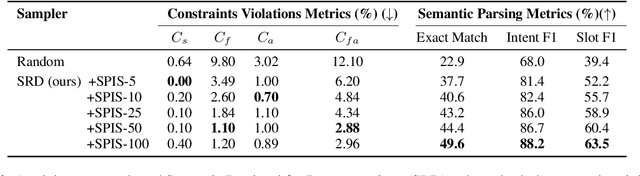
In executable task-oriented semantic parsing, the system aims to translate users' utterances in natural language to machine-interpretable programs (API calls) that can be executed according to pre-defined API specifications. With the popularity of Large Language Models (LLMs), in-context learning offers a strong baseline for such scenarios, especially in data-limited regimes. However, LLMs are known to hallucinate and therefore pose a formidable challenge in constraining generated content. Thus, it remains uncertain if LLMs can effectively perform task-oriented utterance-to-API generation where respecting API's structural and task-specific constraints is crucial. In this work, we seek to measure, analyze and mitigate such constraints violations. First, we identify the categories of various constraints in obtaining API-semantics from task-oriented utterances, and define fine-grained metrics that complement traditional ones. Second, we leverage these metrics to conduct a detailed error analysis of constraints violations seen in state-of-the-art LLMs, which motivates us to investigate two mitigation strategies: Semantic-Retrieval of Demonstrations (SRD) and API-aware Constrained Decoding (API-CD). Our experiments show that these strategies are effective at reducing constraints violations and improving the quality of the generated API calls, but require careful consideration given their implementation complexity and latency.
Does Neural Machine Translation Benefit from Larger Context?
Apr 17, 2017
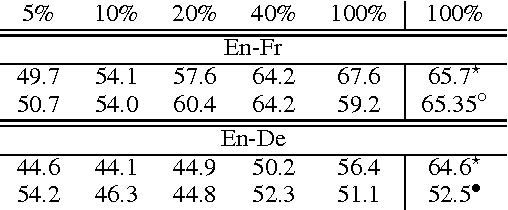

We propose a neural machine translation architecture that models the surrounding text in addition to the source sentence. These models lead to better performance, both in terms of general translation quality and pronoun prediction, when trained on small corpora, although this improvement largely disappears when trained with a larger corpus. We also discover that attention-based neural machine translation is well suited for pronoun prediction and compares favorably with other approaches that were specifically designed for this task.
Embedding Word Similarity with Neural Machine Translation
Apr 03, 2015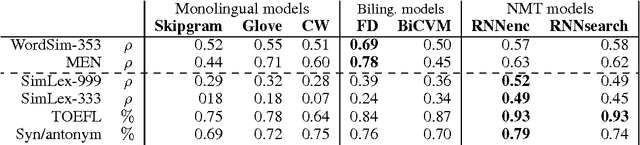
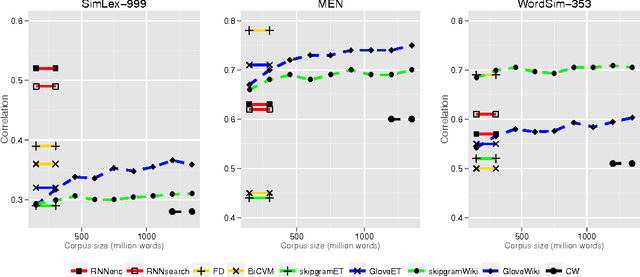
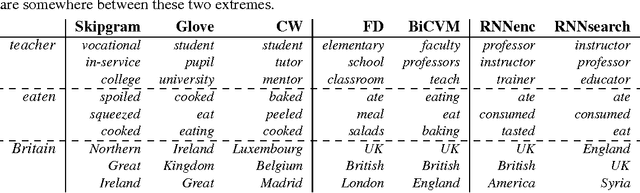
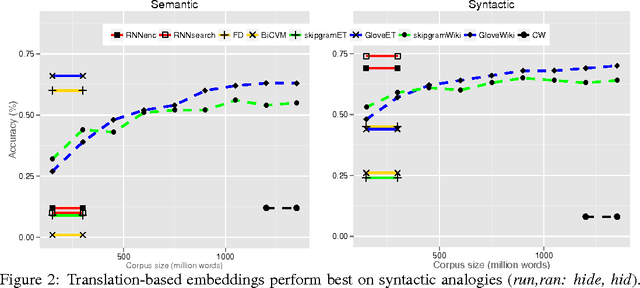
Neural language models learn word representations, or embeddings, that capture rich linguistic and conceptual information. Here we investigate the embeddings learned by neural machine translation models, a recently-developed class of neural language model. We show that embeddings from translation models outperform those learned by monolingual models at tasks that require knowledge of both conceptual similarity and lexical-syntactic role. We further show that these effects hold when translating from both English to French and English to German, and argue that the desirable properties of translation embeddings should emerge largely independently of the source and target languages. Finally, we apply a new method for training neural translation models with very large vocabularies, and show that this vocabulary expansion algorithm results in minimal degradation of embedding quality. Our embedding spaces can be queried in an online demo and downloaded from our web page. Overall, our analyses indicate that translation-based embeddings should be used in applications that require concepts to be organised according to similarity and/or lexical function, while monolingual embeddings are better suited to modelling (nonspecific) inter-word relatedness.
Not All Neural Embeddings are Born Equal
Nov 13, 2014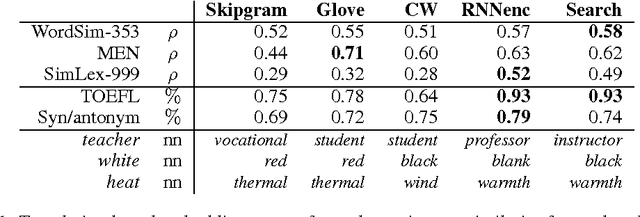
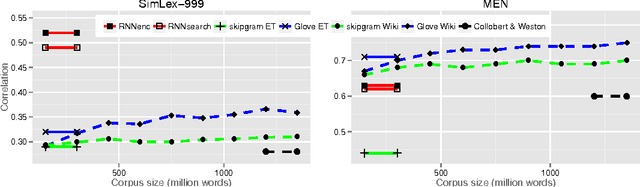

Neural language models learn word representations that capture rich linguistic and conceptual information. Here we investigate the embeddings learned by neural machine translation models. We show that translation-based embeddings outperform those learned by cutting-edge monolingual models at single-language tasks requiring knowledge of conceptual similarity and/or syntactic role. The findings suggest that, while monolingual models learn information about how concepts are related, neural-translation models better capture their true ontological status.