 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustification of Multilingual Language Models to Real-world Noise with Robust Contrastive Pretraining
Paper and Code
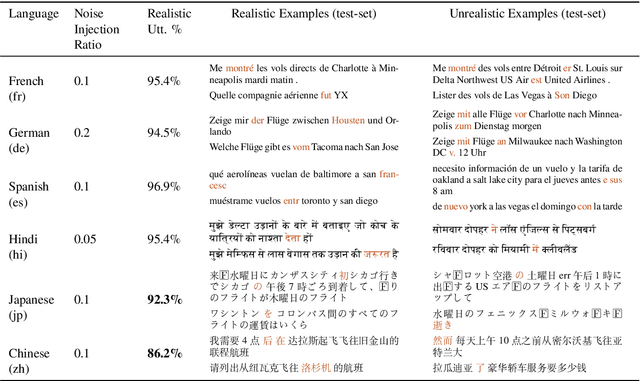
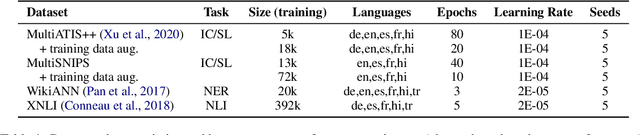
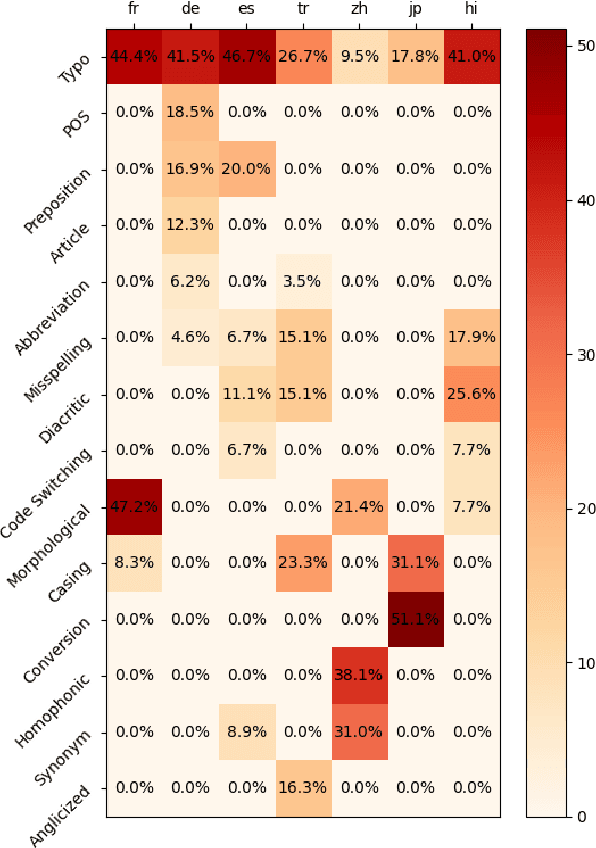
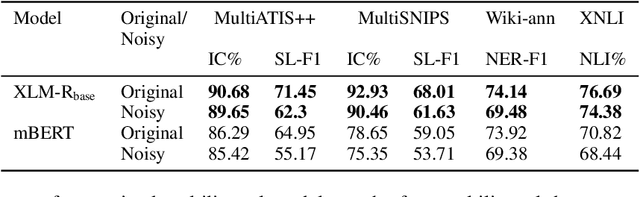
Advances in neural modeling have achieved state-of-the-art (SOTA) results on public natural language processing (NLP) benchmarks, at times surpassing human performance. However, there is a gap between public benchmarks and real-world applications where noise such as typos or grammatical mistakes is abundant, resulting in degraded performance. Unfortunately, works that assess the robustness of neural models on noisy data and suggest improvements are limited to the English language. Upon analyzing noise in different languages, we observe that noise types vary across languages and thus require their own investigation. Thus, to benchmark the performance of pretrained multilingual models, we construct noisy datasets covering five languages and four NLP tasks. We see a gap in performance between clean and noisy data. After investigating ways to boost the zero-shot cross-lingual robustness of multilingual pretrained models, we propose Robust Contrastive Pretraining (RCP). RCP combines data augmentation with a contrastive loss term at the pretraining stage and achieves large improvements on noisy (& original test data) across two sentence-level classification (+3.2%) and two sequence-labeling (+10 F1-score) multilingual tasks.