 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Random Masking: A Dual-Stream Approach for Rotation-Invariant Point Cloud Masked Autoencoders
Sep 18, 2025Existing rotation-invariant point cloud masked autoencoders (MAE) rely on random masking strategies that overlook geometric structure and semantic coherence. Random masking treats patches independently, failing to capture spatial relationships consistent across orientations and overlooking semantic object parts that maintain identity regardless of rotation. We propose a dual-stream masking approach combining 3D Spatial Grid Masking and Progressive Semantic Masking to address these fundamental limitations. Grid masking creates structured patterns through coordinate sorting to capture geometric relationships that persist across different orientations, while semantic masking uses attention-driven clustering to discover semantically meaningful parts and maintain their coherence during masking. These complementary streams are orchestrated via curriculum learning with dynamic weighting, progressing from geometric understanding to semantic discovery. Designed as plug-and-play components, our strategies integrate into existing rotation-invariant frameworks without architectural changes, ensuring broad compatibility across different approaches. Comprehensive experiments on ModelNet40, ScanObjectNN, and OmniObject3D demonstrate consistent improvements across various rotation scenarios, showing substantial performance gains over the baseline rotation-invariant methods.
LLM-Enhanced Rapid-Reflex Async-Reflect Embodied Agent for Real-Time Decision-Making in Dynamically Changing Environments
Jun 08, 2025In the realm of embodied intelligence, the evolution of large language models (LLMs) has markedly enhanced agent decision making. Consequently, researchers have begun exploring agent performance in dynamically changing high-risk scenarios, i.e., fire, flood, and wind scenarios in the HAZARD benchmark. Under these extreme conditions, the delay in decision making emerges as a crucial yet insufficiently studied issue. We propose a Time Conversion Mechanism (TCM) that translates inference delays in decision-making into equivalent simulation frames, thus aligning cognitive and physical costs under a single FPS-based metric. By extending HAZARD with Respond Latency (RL) and Latency-to-Action Ratio (LAR), we deliver a fully latency-aware evaluation protocol. Moreover, we present the Rapid-Reflex Async-Reflect Agent (RRARA), which couples a lightweight LLM-guided feedback module with a rule-based agent to enable immediate reactive behaviors and asynchronous reflective refinements in situ. Experiments on HAZARD show that RRARA substantially outperforms existing baselines in latency-sensitive scenarios.
Through the Magnifying Glass: Adaptive Perception Magnification for Hallucination-Free VLM Decoding
Mar 13, 2025Existing vision-language models (VLMs) often suffer from visual hallucination, where the generated responses contain inaccuracies that are not grounded in the visual input. Efforts to address this issue without model finetuning primarily mitigate hallucination by reducing biases contrastively or amplifying the weights of visual embedding during decoding. However, these approaches improve visual perception at the cost of impairing the language reasoning capability. In this work, we propose the Perception Magnifier (PM), a novel visual decoding method that iteratively isolates relevant visual tokens based on attention and magnifies the corresponding regions, spurring the model to concentrate on fine-grained visual details during decoding. Specifically, by magnifying critical regions while preserving the structural and contextual information at each decoding step, PM allows the VLM to enhance its scrutiny of the visual input, hence producing more accurate and faithful responses. Extensive experimental results demonstrate that PM not only achieves superior hallucination mitigation but also enhances language generation while preserving strong reasoning capabilities.Code is available at https://github.com/ShunqiM/PM .
Controllable Contextualized Image Captioning: Directing the Visual Narrative through User-Defined Highlights
Jul 16, 2024Contextualized Image Captioning (CIC) evolves traditional image captioning into a more complex domain, necessitating the ability for multimodal reasoning. It aims to generate image captions given specific contextual information. This paper further introduces a novel domain of Controllable Contextualized Image Captioning (Ctrl-CIC). Unlike CIC, which solely relies on broad context, Ctrl-CIC accentuates a user-defined highlight, compelling the model to tailor captions that resonate with the highlighted aspects of the context. We present two approaches, Prompting-based Controller (P-Ctrl) and Recalibration-based Controller (R-Ctrl), to generate focused captions. P-Ctrl conditions the model generation on highlight by prepending captions with highlight-driven prefixes, whereas R-Ctrl tunes the model to selectively recalibrate the encoder embeddings for highlighted tokens. Additionally, we design a GPT-4V empowered evaluator to assess the quality of the controlled captions alongside standard assessment methods. Extensive experimental results demonstrate the efficient and effective controllability of our method, charting a new direction in achieving user-adaptive image captioning. Code is available at https://github.com/ShunqiM/Ctrl-CIC .
Towards Generalisable Audio Representations for Audio-Visual Navigation
Jun 01, 2022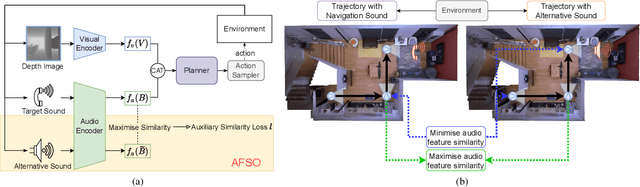
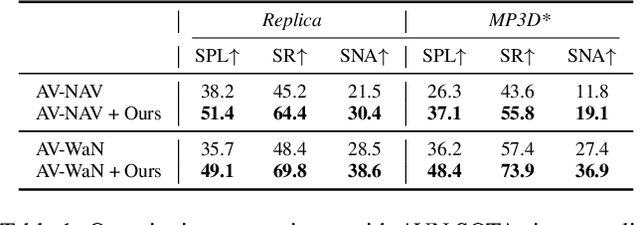
In audio-visual navigation (AVN), an intelligent agent needs to navigate to a constantly sound-making object in complex 3D environments based on its audio and visual perceptions. While existing methods attempt to improve the navigation performance with preciously designed path planning or intricate task settings, none has improved the model generalisation on unheard sounds with task settings unchanged. We thus propose a contrastive learning-based method to tackle this challenge by regularising the audio encoder, where the sound-agnostic goal-driven latent representations can be learnt from various audio signals of different classes. In addition, we consider two data augmentation strategies to enrich the training sounds. We demonstrate that our designs can be easily equipped to existing AVN frameworks to obtain an immediate performance gain (13.4%$\uparrow$ in SPL on Replica and 12.2%$\uparrow$ in SPL on MP3D). Our project is available at https://AV-GeN.github.io/.