 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetrics also Disagree in the Low Scoring Range: Revisiting Summarization Evaluation Metrics
Nov 08, 2020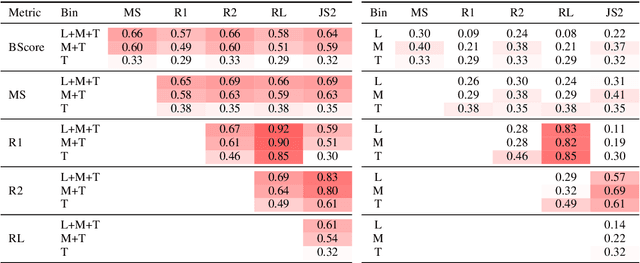

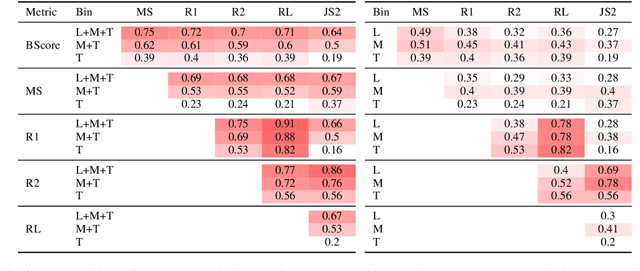

In text summarization, evaluating the efficacy of automatic metrics without human judgments has become recently popular. One exemplar work concludes that automatic metrics strongly disagree when ranking high-scoring summaries. In this paper, we revisit their experiments and find that their observations stem from the fact that metrics disagree in ranking summaries from any narrow scoring range. We hypothesize that this may be because summaries are similar to each other in a narrow scoring range and are thus, difficult to rank. Apart from the width of the scoring range of summaries, we analyze three other properties that impact inter-metric agreement - Ease of Summarization, Abstractiveness, and Coverage. To encourage reproducible research, we make all our analysis code and data publicly available.
Re-evaluating Evaluation in Text Summarization
Oct 14, 2020


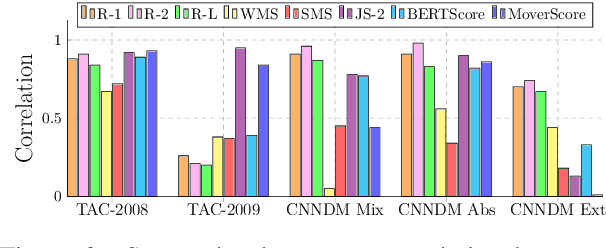
Automated evaluation metrics as a stand-in for manual evaluation are an essential part of the development of text-generation tasks such as text summarization. However, while the field has progressed, our standard metrics have not -- for nearly 20 years ROUGE has been the standard evaluation in most summarization papers. In this paper, we make an attempt to re-evaluate the evaluation method for text summarization: assessing the reliability of automatic metrics using top-scoring system outputs, both abstractive and extractive, on recently popular datasets for both system-level and summary-level evaluation settings. We find that conclusions about evaluation metrics on older datasets do not necessarily hold on modern datasets and systems.
Confidence-based Graph Convolutional Networks for Semi-Supervised Learning
Jan 24, 2019
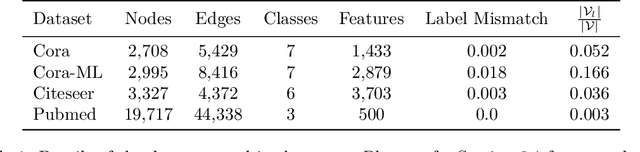


Predicting properties of nodes in a graph is an important problem with applications in a variety of domains. Graph-based Semi-Supervised Learning (SSL) methods aim to address this problem by labeling a small subset of the nodes as seeds and then utilizing the graph structure to predict label scores for the rest of the nodes in the graph. Recently, Graph Convolutional Networks (GCNs) have achieved impressive performance on the graph-based SSL task. In addition to label scores, it is also desirable to have confidence scores associated with them. Unfortunately, confidence estimation in the context of GCN has not been previously explored. We fill this important gap in this paper and propose ConfGCN, which estimates labels scores along with their confidences jointly in GCN-based setting. ConfGCN uses these estimated confidences to determine the influence of one node on another during neighborhood aggregation, thereby acquiring anisotropic capabilities. Through extensive analysis and experiments on standard benchmarks, we find that ConfGCN is able to outperform state-of-the-art baselines. We have made ConfGCN's source code available to encourage reproducible research.
Graph Convolutional Networks based Word Embeddings
Sep 12, 2018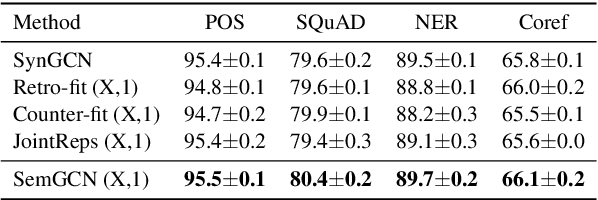
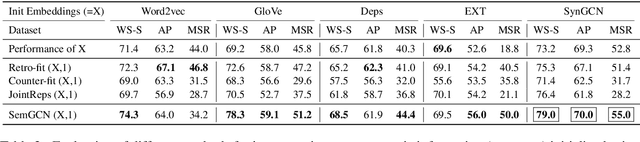
Recently, word embeddings have been widely adopted across several NLP applications. However, most word embedding methods solely rely on linear context and do not provide a framework for incorporating word relationships like hypernym, nmod in a principled manner. In this paper, we propose WordGCN, a Graph Convolution based word representation learning approach which provides a framework for exploiting multiple types of word relationships. WordGCN operates at sentence as well as corpus level and allows to incorporate dependency parse based context in an efficient manner without increasing the vocabulary size. To the best of our knowledge, this is the first approach which effectively incorporates word relationships via Graph Convolutional Networks for learning word representations. Through extensive experiments on various intrinsic and extrinsic tasks, we demonstrate WordGCN's effectiveness over existing word embedding approaches. We make WordGCN's source code available to encourage reproducible research.