 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetrics also Disagree in the Low Scoring Range: Revisiting Summarization Evaluation Metrics
Nov 08, 2020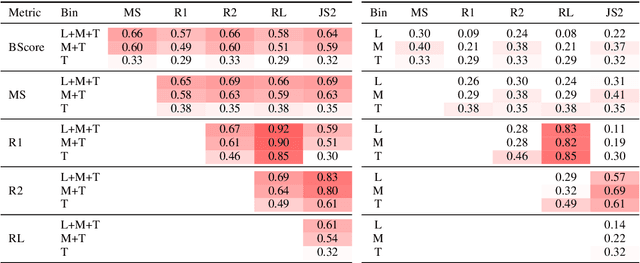

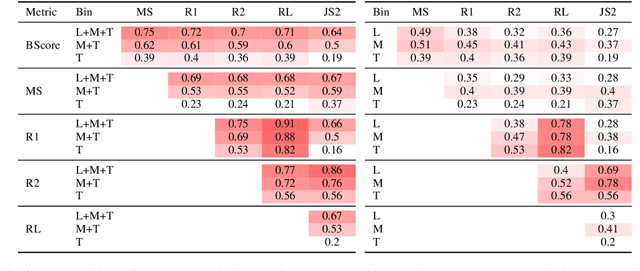

In text summarization, evaluating the efficacy of automatic metrics without human judgments has become recently popular. One exemplar work concludes that automatic metrics strongly disagree when ranking high-scoring summaries. In this paper, we revisit their experiments and find that their observations stem from the fact that metrics disagree in ranking summaries from any narrow scoring range. We hypothesize that this may be because summaries are similar to each other in a narrow scoring range and are thus, difficult to rank. Apart from the width of the scoring range of summaries, we analyze three other properties that impact inter-metric agreement - Ease of Summarization, Abstractiveness, and Coverage. To encourage reproducible research, we make all our analysis code and data publicly available.
Re-evaluating Evaluation in Text Summarization
Oct 14, 2020


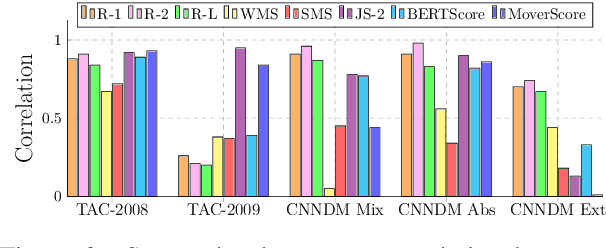
Automated evaluation metrics as a stand-in for manual evaluation are an essential part of the development of text-generation tasks such as text summarization. However, while the field has progressed, our standard metrics have not -- for nearly 20 years ROUGE has been the standard evaluation in most summarization papers. In this paper, we make an attempt to re-evaluate the evaluation method for text summarization: assessing the reliability of automatic metrics using top-scoring system outputs, both abstractive and extractive, on recently popular datasets for both system-level and summary-level evaluation settings. We find that conclusions about evaluation metrics on older datasets do not necessarily hold on modern datasets and systems.