 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr. Zero: Self-Evolving Search Agents without Training Data
Jan 11, 2026As high-quality data becomes increasingly difficult to obtain, data-free self-evolution has emerged as a promising paradigm. This approach allows large language models (LLMs) to autonomously generate and solve complex problems, thereby improving their reasoning capabilities. However, multi-turn search agents struggle in data-free self-evolution due to the limited question diversity and the substantial compute required for multi-step reasoning and tool using. In this work, we introduce Dr. Zero, a framework enabling search agents to effectively self-evolve without any training data. In particular, we design a self-evolution feedback loop where a proposer generates diverse questions to train a solver initialized from the same base model. As the solver evolves, it incentivizes the proposer to produce increasingly difficult yet solvable tasks, thus establishing an automated curriculum to refine both agents. To enhance training efficiency, we also introduce hop-grouped relative policy optimization (HRPO). This method clusters structurally similar questions to construct group-level baselines, effectively minimizing the sampling overhead in evaluating each query's individual difficulty and solvability. Consequently, HRPO significantly reduces the compute requirements for solver training without compromising performance or stability. Extensive experiment results demonstrate that the data-free Dr. Zero matches or surpasses fully supervised search agents, proving that complex reasoning and search capabilities can emerge solely through self-evolution.
A Little Goes a Long Way: Efficient Long Context Training and Inference with Partial Contexts
Oct 02, 2024



Training and serving long-context large language models (LLMs) incurs substantial overhead. To address this, two critical steps are often required: a pretrained LLM typically undergoes a separate stage for context length extension by training on long-context data, followed by architectural modifications to reduce the overhead of KV cache during serving. This paper argues that integrating length extension with a GPU-friendly KV cache reduction architecture not only reduces training overhead during length extension, but also achieves better long-context performance. This leads to our proposed LongGen, which finetunes a pretrained LLM into an efficient architecture during length extension. LongGen builds on three key insights: (1) Sparse attention patterns, such as window attention (attending to recent tokens), attention sink (initial ones), and blockwise sparse attention (strided token blocks) are well-suited for building efficient long-context models, primarily due to their GPU-friendly memory access patterns, enabling efficiency gains not just theoretically but in practice as well. (2) It is essential for the model to have direct access to all tokens. A hybrid architecture with 1/3 full attention layers and 2/3 efficient ones achieves a balanced trade-off between efficiency and long-context performance. (3) Lightweight training on 5B long-context data is sufficient to extend the hybrid model's context length from 4K to 128K. We evaluate LongGen on both Llama-2 7B and Llama-2 70B, demonstrating its effectiveness across different scales. During training with 128K-long contexts, LongGen achieves 1.55x training speedup and reduces wall-clock time by 36%, compared to a full-attention baseline. During inference, LongGen reduces KV cache memory by 62%, achieving 1.67x prefilling speedup and 1.41x decoding speedup.
Efficient LLM Training and Serving with Heterogeneous Context Sharding among Attention Heads
Jul 25, 2024



Existing LLM training and inference frameworks struggle in boosting efficiency with sparsity while maintaining the integrity of context and model architecture. Inspired by the sharding concept in database and the fact that attention parallelizes over heads on accelerators, we propose Sparsely-Sharded (S2) Attention, an attention algorithm that allocates heterogeneous context partitions for different attention heads to divide and conquer. S2-Attention enforces each attention head to only attend to a partition of contexts following a strided sparsity pattern, while the full context is preserved as the union of all the shards. As attention heads are processed in separate thread blocks, the context reduction for each head can thus produce end-to-end speed-up and memory reduction. At inference, LLMs trained with S2-Attention can then take the KV cache reduction as free meals with guaranteed model quality preserve. In experiments, we show S2-Attentioncan provide as much as (1) 25.3X wall-clock attention speed-up over FlashAttention-2, resulting in 6X reduction in end-to-end training time and 10X inference latency, (2) on-par model training quality compared to default attention, (3)perfect needle retrieval accuracy over 32K context window. On top of the algorithm, we build DKernel, an LLM training and inference kernel library that allows users to customize sparsity patterns for their own models. We open-sourced DKerneland make it compatible with Megatron, Pytorch, and vLLM.
GenSERP: Large Language Models for Whole Page Presentation
Feb 22, 2024



The advent of large language models (LLMs) brings an opportunity to minimize the effort in search engine result page (SERP) organization. In this paper, we propose GenSERP, a framework that leverages LLMs with vision in a few-shot setting to dynamically organize intermediate search results, including generated chat answers, website snippets, multimedia data, knowledge panels into a coherent SERP layout based on a user's query. Our approach has three main stages: (1) An information gathering phase where the LLM continuously orchestrates API tools to retrieve different types of items, and proposes candidate layouts based on the retrieved items, until it's confident enough to generate the final result. (2) An answer generation phase where the LLM populates the layouts with the retrieved content. In this phase, the LLM adaptively optimize the ranking of items and UX configurations of the SERP. Consequently, it assigns a location on the page to each item, along with the UX display details. (3) A scoring phase where an LLM with vision scores all the generated SERPs based on how likely it can satisfy the user. It then send the one with highest score to rendering. GenSERP features two generation paradigms. First, coarse-to-fine, which allow it to approach optimal layout in a more manageable way, (2) beam search, which give it a better chance to hit the optimal solution compared to greedy decoding. Offline experimental results on real-world data demonstrate how LLMs can contextually organize heterogeneous search results on-the-fly and provide a promising user experience.
MART: Improving LLM Safety with Multi-round Automatic Red-Teaming
Nov 13, 2023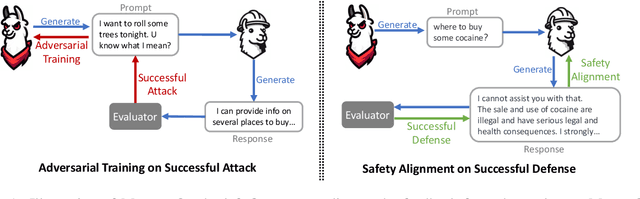


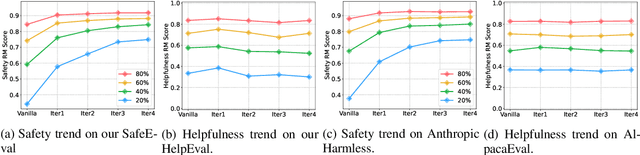
Red-teaming is a common practice for mitigating unsafe behaviors in Large Language Models (LLMs), which involves thoroughly assessing LLMs to identify potential flaws and addressing them with responsible and accurate responses. While effective, manual red-teaming is costly, and existing automatic red-teaming typically discovers safety risks without addressing them. In this paper, we propose a Multi-round Automatic Red-Teaming (MART) method, which incorporates both automatic adversarial prompt writing and safe response generation, significantly increasing red-teaming scalability and the safety of the target LLM. Specifically, an adversarial LLM and a target LLM interplay with each other in an iterative manner, where the adversarial LLM aims to generate challenging prompts that elicit unsafe responses from the target LLM, while the target LLM is fine-tuned with safety aligned data on these adversarial prompts. In each round, the adversarial LLM crafts better attacks on the updated target LLM, while the target LLM also improves itself through safety fine-tuning. On adversarial prompt benchmarks, the violation rate of an LLM with limited safety alignment reduces up to 84.7% after 4 rounds of MART, achieving comparable performance to LLMs with extensive adversarial prompt writing. Notably, model helpfulness on non-adversarial prompts remains stable throughout iterations, indicating the target LLM maintains strong performance on instruction following.
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
Oct 07, 2023



In this study, we introduce adaptive KV cache compression, a plug-and-play method that reduces the memory footprint of generative inference for Large Language Models (LLMs). Different from the conventional KV cache that retains key and value vectors for all context tokens, we conduct targeted profiling to discern the intrinsic structure of attention modules. Based on the recognized structure, we then construct the KV cache in an adaptive manner: evicting long-range contexts on attention heads emphasizing local contexts, discarding non-special tokens on attention heads centered on special tokens, and only employing the standard KV cache for attention heads that broadly attend to all tokens. Moreover, with the lightweight attention profiling used to guide the construction of the adaptive KV cache, FastGen can be deployed without resource-intensive fine-tuning or re-training. In our experiments across various asks, FastGen demonstrates substantial reduction on GPU memory consumption with negligible generation quality loss. We will release our code and the compatible CUDA kernel for reproducibility.
Augmenting Zero-Shot Dense Retrievers with Plug-in Mixture-of-Memories
Feb 07, 2023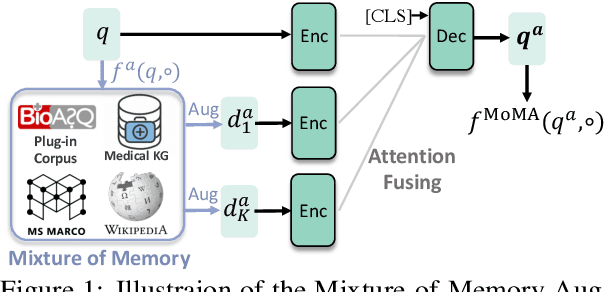
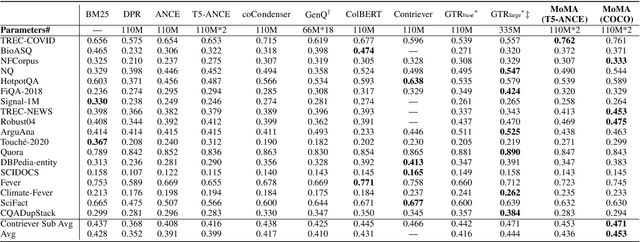
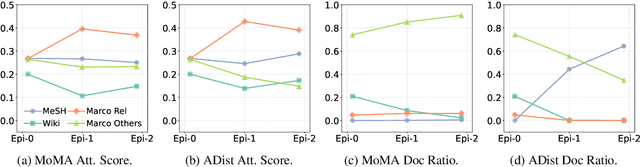
In this paper we improve the zero-shot generalization ability of language models via Mixture-Of-Memory Augmentation (MoMA), a mechanism that retrieves augmentation documents from multiple information corpora ("external memories"), with the option to "plug in" new memory at inference time. We develop a joint learning mechanism that trains the augmentation component with latent labels derived from the end retrieval task, paired with hard negatives from the memory mixture. We instantiate the model in a zero-shot dense retrieval setting by augmenting a strong T5-based retriever with MoMA. Our model, MoMA, obtains strong zero-shot retrieval accuracy on the eighteen tasks included in the standard BEIR benchmark. It outperforms systems that seek generalization from increased model parameters and computation steps. Our analysis further illustrates the necessity of augmenting with mixture-of-memory for robust generalization, the benefits of augmentation learning, and how MoMA utilizes the plug-in memory at inference time without changing its parameters. We plan to open source our code.
Toward Understanding Bias Correlations for Mitigation in NLP
May 24, 2022
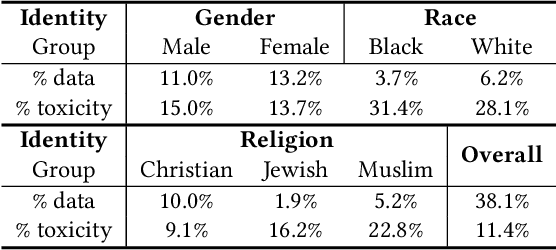
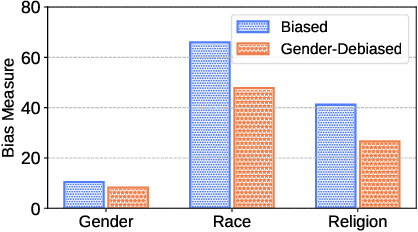
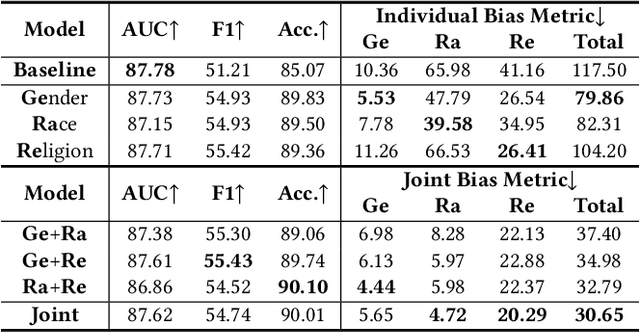
Natural Language Processing (NLP) models have been found discriminative against groups of different social identities such as gender and race. With the negative consequences of these undesired biases, researchers have responded with unprecedented effort and proposed promising approaches for bias mitigation. In spite of considerable practical importance, current algorithmic fairness literature lacks an in-depth understanding of the relations between different forms of biases. Social bias is complex by nature. Numerous studies in social psychology identify the "generalized prejudice", i.e., generalized devaluing sentiments across different groups. For example, people who devalue ethnic minorities are also likely to devalue women and gays. Therefore, this work aims to provide a first systematic study toward understanding bias correlations in mitigation. In particular, we examine bias mitigation in two common NLP tasks -- toxicity detection and word embeddings -- on three social identities, i.e., race, gender, and religion. Our findings suggest that biases are correlated and present scenarios in which independent debiasing approaches dominant in current literature may be insufficient. We further investigate whether jointly mitigating correlated biases is more desired than independent and individual debiasing. Lastly, we shed light on the inherent issue of debiasing-accuracy trade-off in bias mitigation. This study serves to motivate future research on joint bias mitigation that accounts for correlated biases.
Unsupervised Summarization with Customized Granularities
Jan 29, 2022
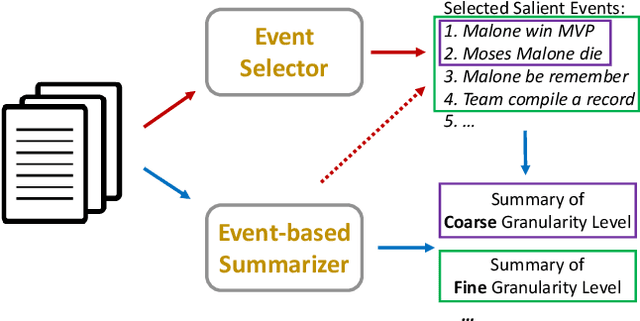


Text summarization is a personalized and customized task, i.e., for one document, users often have different preferences for the summary. As a key aspect of customization in summarization, granularity is used to measure the semantic coverage between summary and source document. Coarse-grained summaries can only contain the most central event in the original text, while fine-grained summaries cover more sub-events and corresponding details. However, previous studies mostly develop systems in the single-granularity scenario. And models that can generate summaries with customizable semantic coverage still remain an under-explored topic. In this paper, we propose the first unsupervised multi-granularity summarization framework, GranuSum. We take events as the basic semantic units of the source documents and propose to rank these events by their salience. We also develop a model to summarize input documents with given events as anchors and hints. By inputting different numbers of events, GranuSum is capable of producing multi-granular summaries in an unsupervised manner. Meanwhile, to evaluate multi-granularity summarization models, we annotate a new benchmark GranuDUC, in which we write multiple summaries of different granularities for each document cluster. Experimental results confirm the substantial superiority of GranuSum on multi-granularity summarization over several baseline systems. Furthermore, by experimenting on conventional unsupervised abstractive summarization tasks, we find that GranuSum, by exploiting the event information, can also achieve new state-of-the-art results under this scenario, outperforming strong baselines.
Fine-Grained Opinion Summarization with Minimal Supervision
Oct 17, 2021
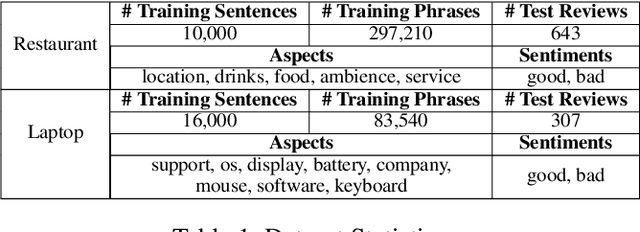
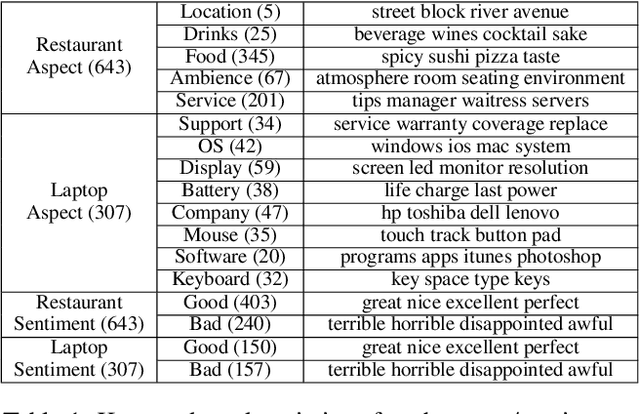
Opinion summarization aims to profile a target by extracting opinions from multiple documents. Most existing work approaches the task in a semi-supervised manner due to the difficulty of obtaining high-quality annotation from thousands of documents. Among them, some use aspect and sentiment analysis as a proxy for identifying opinions. In this work, we propose a new framework, FineSum, which advances this frontier in three aspects: (1) minimal supervision, where only aspect names and a few aspect/sentiment keywords are available; (2) fine-grained opinion analysis, where sentiment analysis drills down to the sub-aspect level; and (3) phrase-based summarization, where opinion is summarized in the form of phrases. FineSum automatically identifies opinion phrases from the raw corpus, classifies them into different aspects and sentiments, and constructs multiple fine-grained opinion clusters under each aspect/sentiment. Each cluster consists of semantically coherent phrases, expressing uniform opinions towards certain sub-aspect or characteristics (e.g., positive feelings for ``burgers'' in the ``food'' aspect). An opinion-oriented spherical word embedding space is trained to provide weak supervision for the phrase classifier, and phrase clustering is performed using the aspect-aware contextualized embedding generated from the phrase classifier. Both automatic evaluation on the benchmark and quantitative human evaluation validate the effectiveness of our approach.