 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISPO: Enhancing Training Efficiency and Stability in Reinforcement Learning for Large Language Model Mathematical Reasoning
Feb 01, 2026Reinforcement learning with verifiable rewards has emerged as a promising paradigm for enhancing the reasoning capabilities of large language models particularly in mathematics. Current approaches in this domain present a clear trade-off: PPO-style methods (e.g., GRPO/DAPO) offer training stability but exhibit slow learning trajectories due to their trust-region constraints on policy updates, while REINFORCE-style approaches (e.g., CISPO) demonstrate improved learning efficiency but suffer from performance instability as they clip importance sampling weights while still permitting non-zero gradients outside the trust-region. To address these limitations, we introduce DISPO, a simple yet effective REINFORCE-style algorithm that decouples the up-clipping and down-clipping of importance sampling weights for correct and incorrect responses, yielding four controllable policy update regimes. Through targeted ablations, we uncover how each regime impacts training: for correct responses, weights >1 increase the average token entropy (i.e., exploration) while weights <1 decrease it (i.e., distillation) -- both beneficial but causing gradual performance degradation when excessive. For incorrect responses, overly restrictive clipping triggers sudden performance collapse through repetitive outputs (when weights >1) or vanishing response lengths (when weights <1). By separately tuning these four clipping parameters, DISPO maintains the exploration-distillation balance while preventing catastrophic failures, achieving 61.04% on AIME'24 (vs. 55.42% CISPO and 50.21% DAPO) with similar gains across various benchmarks and models.
POROver: Improving Safety and Reducing Overrefusal in Large Language Models with Overgeneration and Preference Optimization
Oct 16, 2024
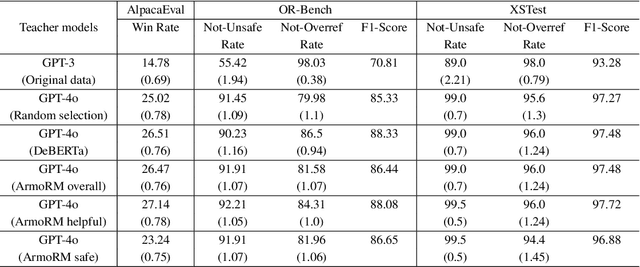
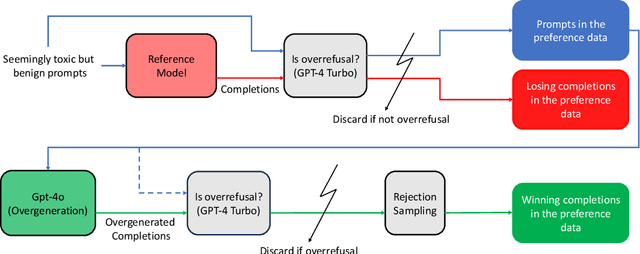

Balancing safety and usefulness in large language models has become a critical challenge in recent years. Models often exhibit unsafe behavior or adopt an overly cautious approach, leading to frequent overrefusal of benign prompts, which reduces their usefulness. Addressing these issues requires methods that maintain safety while avoiding overrefusal. In this work, we examine how the overgeneration of training data using advanced teacher models (e.g., GPT-4o), including responses to both general-purpose and toxic prompts, influences the safety and overrefusal balance of instruction-following language models. Additionally, we present POROver, a strategy to use preference optimization methods in order to reduce overrefusal, via employing a superior teacher model's completions. Our results show that overgenerating completions for general-purpose prompts significantly improves the balance between safety and usefulness. Specifically, the F1 score calculated between safety and usefulness increases from 70.8% to 88.3%. Moreover, overgeneration for toxic prompts substantially reduces overrefusal, decreasing it from 94.4% to 45.2%. Furthermore, preference optimization algorithms, when applied with carefully curated preference data, can effectively reduce a model's overrefusal from 45.2% to 15.0% while maintaining comparable safety levels. Our code and data are available at https://github.com/batuhankmkaraman/POROver.
Knockout: A simple way to handle missing inputs
Jun 03, 2024

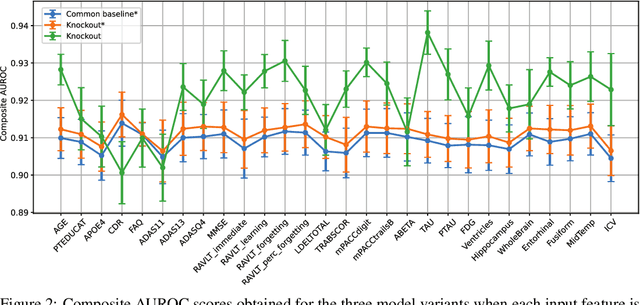

Deep learning models can extract predictive and actionable information from complex inputs. The richer the inputs, the better these models usually perform. However, models that leverage rich inputs (e.g., multi-modality) can be difficult to deploy widely, because some inputs may be missing at inference. Current popular solutions to this problem include marginalization, imputation, and training multiple models. Marginalization can obtain calibrated predictions but it is computationally costly and therefore only feasible for low dimensional inputs. Imputation may result in inaccurate predictions because it employs point estimates for missing variables and does not work well for high dimensional inputs (e.g., images). Training multiple models whereby each model takes different subsets of inputs can work well but requires knowing missing input patterns in advance. Furthermore, training and retaining multiple models can be costly. We propose an efficient way to learn both the conditional distribution using full inputs and the marginal distributions. Our method, Knockout, randomly replaces input features with appropriate placeholder values during training. We provide a theoretical justification of Knockout and show that it can be viewed as an implicit marginalization strategy. We evaluate Knockout in a wide range of simulations and real-world datasets and show that it can offer strong empirical performance.
Assessing the significance of longitudinal data in Alzheimer's Disease forecasting
May 27, 2024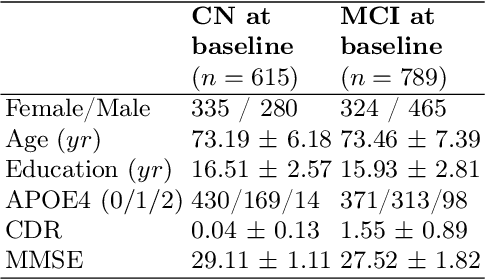

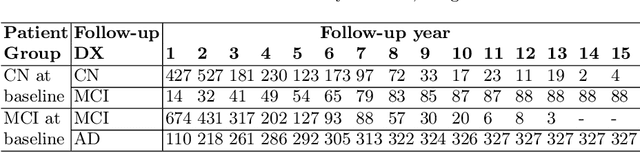

In this study, we employ a transformer encoder model to characterize the significance of longitudinal patient data for forecasting the progression of Alzheimer's Disease (AD). Our model, Longitudinal Forecasting Model for Alzheimer's Disease (LongForMAD), harnesses the comprehensive temporal information embedded in sequences of patient visits that incorporate multimodal data, providing a deeper understanding of disease progression than can be drawn from single-visit data alone. We present an empirical analysis across two patient groups-Cognitively Normal (CN) and Mild Cognitive Impairment (MCI)-over a span of five follow-up years. Our findings reveal that models incorporating more extended patient histories can outperform those relying solely on present information, suggesting a deeper historical context is critical in enhancing predictive accuracy for future AD progression. Our results support the incorporation of longitudinal data in clinical settings to enhance the early detection and monitoring of AD. Our code is available at \url{https://github.com/batuhankmkaraman/LongForMAD}.
Longitudinal Mammogram Risk Prediction
Apr 29, 2024


Breast cancer is one of the leading causes of mortality among women worldwide. Early detection and risk assessment play a crucial role in improving survival rates. Therefore, annual or biennial mammograms are often recommended for screening in high-risk groups. Mammograms are typically interpreted by expert radiologists based on the Breast Imaging Reporting and Data System (BI-RADS), which provides a uniform way to describe findings and categorizes them to indicate the level of concern for breast cancer. Recently, machine learning (ML) and computational approaches have been developed to automate and improve the interpretation of mammograms. However, both BI-RADS and the ML-based methods focus on the analysis of data from the present and sometimes the most recent prior visit. While it is clear that temporal changes in image features of the longitudinal scans should carry value for quantifying breast cancer risk, no prior work has conducted a systematic study of this. In this paper, we extend a state-of-the-art ML model to ingest an arbitrary number of longitudinal mammograms and predict future breast cancer risk. On a large-scale dataset, we demonstrate that our model, LoMaR, achieves state-of-the-art performance when presented with only the present mammogram. Furthermore, we use LoMaR to characterize the predictive value of prior visits. Our results show that longer histories (e.g., up to four prior annual mammograms) can significantly boost the accuracy of predicting future breast cancer risk, particularly beyond the short-term. Our code and model weights are available at https://github.com/batuhankmkaraman/LoMaR.
A Framework for Interpretability in Machine Learning for Medical Imaging
Oct 02, 2023

Interpretability for machine learning models in medical imaging (MLMI) is an important direction of research. However, there is a general sense of murkiness in what interpretability means. Why does the need for interpretability in MLMI arise? What goals does one actually seek to address when interpretability is needed? To answer these questions, we identify a need to formalize the goals and elements of interpretability in MLMI. By reasoning about real-world tasks and goals common in both medical image analysis and its intersection with machine learning, we identify four core elements of interpretability: localization, visual recognizability, physical attribution, and transparency. Overall, this paper formalizes interpretability needs in the context of medical imaging, and our applied perspective clarifies concrete MLMI-specific goals and considerations in order to guide method design and improve real-world usage. Our goal is to provide practical and didactic information for model designers and practitioners, inspire developers of models in the medical imaging field to reason more deeply about what interpretability is achieving, and suggest future directions of interpretability research.