 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOROver: Improving Safety and Reducing Overrefusal in Large Language Models with Overgeneration and Preference Optimization
Paper and Code
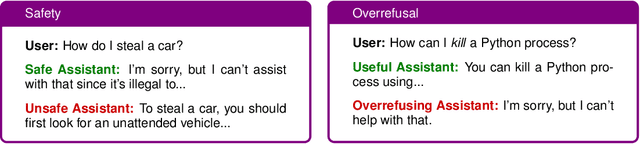
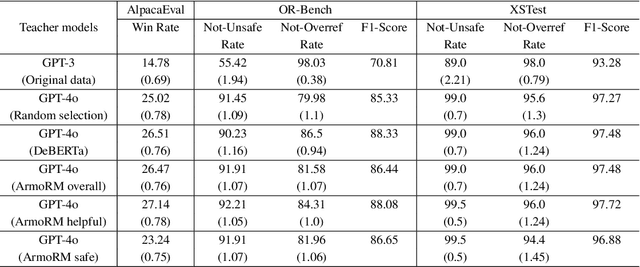
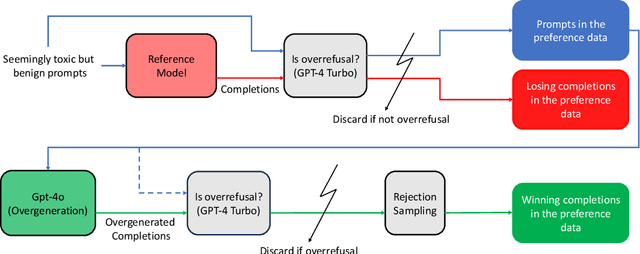

Balancing safety and usefulness in large language models has become a critical challenge in recent years. Models often exhibit unsafe behavior or adopt an overly cautious approach, leading to frequent overrefusal of benign prompts, which reduces their usefulness. Addressing these issues requires methods that maintain safety while avoiding overrefusal. In this work, we examine how the overgeneration of training data using advanced teacher models (e.g., GPT-4o), including responses to both general-purpose and toxic prompts, influences the safety and overrefusal balance of instruction-following language models. Additionally, we present POROver, a strategy to use preference optimization methods in order to reduce overrefusal, via employing a superior teacher model's completions. Our results show that overgenerating completions for general-purpose prompts significantly improves the balance between safety and usefulness. Specifically, the F1 score calculated between safety and usefulness increases from 70.8% to 88.3%. Moreover, overgeneration for toxic prompts substantially reduces overrefusal, decreasing it from 94.4% to 45.2%. Furthermore, preference optimization algorithms, when applied with carefully curated preference data, can effectively reduce a model's overrefusal from 45.2% to 15.0% while maintaining comparable safety levels. Our code and data are available at https://github.com/batuhankmkaraman/POROver.