 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion MRI Transformer with a Diffusion Space Rotary Positional Embedding (D-RoPE)
Mar 26, 2026Diffusion Magnetic Resonance Imaging (dMRI) plays a critical role in studying microstructural changes in the brain. It is, therefore, widely used in clinical practice; yet progress in learning general-purpose representations from dMRI has been limited. A key challenge is that existing deep learning approaches are not well-suited to capture the unique properties of diffusion signals. Brain dMRI is normally composed of several brain volumes, each with different attenuation characteristics dependent on the direction and strength of the diffusion-sensitized gradients. Thus, there is a need to jointly model spatial, diffusion-weighting, and directional dependencies in dMRI. Furthermore, varying acquisition protocols (e.g., differing numbers of directions) further limit traditional models. To address these gaps, we introduce a diffusion space rotatory positional embedding (D-RoPE) plugged into our dMRI transformer to capture both the spatial structure and directional characteristics of diffusion data, enabling robust and transferable representations across diverse acquisition settings and an arbitrary number of diffusion directions. After self-supervised masked autoencoding pretraining, tests on several downstream tasks show that the learned representations and the pretrained model can provide competitive or superior performance compared to several baselines in these downstream tasks (even compared to a fully trained baseline); the finetuned features from our pretrained encoder resulted in a 6% higher accuracy in classifying mild cognitive impairment and a 0.05 increase in the correlation coefficient when predicting cognitive scores. Code is available at: github.com/gustavochau/D-RoPE.
A Tool Bottleneck Framework for Clinically-Informed and Interpretable Medical Image Understanding
Dec 24, 2025Recent tool-use frameworks powered by vision-language models (VLMs) improve image understanding by grounding model predictions with specialized tools. Broadly, these frameworks leverage VLMs and a pre-specified toolbox to decompose the prediction task into multiple tool calls (often deep learning models) which are composed to make a prediction. The dominant approach to composing tools is using text, via function calls embedded in VLM-generated code or natural language. However, these methods often perform poorly on medical image understanding, where salient information is encoded as spatially-localized features that are difficult to compose or fuse via text alone. To address this, we propose a tool-use framework for medical image understanding called the Tool Bottleneck Framework (TBF), which composes VLM-selected tools using a learned Tool Bottleneck Model (TBM). For a given image and task, TBF leverages an off-the-shelf medical VLM to select tools from a toolbox that each extract clinically-relevant features. Instead of text-based composition, these tools are composed by the TBM, which computes and fuses the tool outputs using a neural network before outputting the final prediction. We propose a simple and effective strategy for TBMs to make predictions with any arbitrary VLM tool selection. Overall, our framework not only improves tool-use in medical imaging contexts, but also yields more interpretable, clinically-grounded predictors. We evaluate TBF on tasks in histopathology and dermatology and find that these advantages enable our framework to perform on par with or better than deep learning-based classifiers, VLMs, and state-of-the-art tool-use frameworks, with particular gains in data-limited regimes. Our code is available at https://github.com/christinaliu2020/tool-bottleneck-framework.
RealKeyMorph: Keypoints in Real-world Coordinates for Resolution-agnostic Image Registration
Jun 12, 2025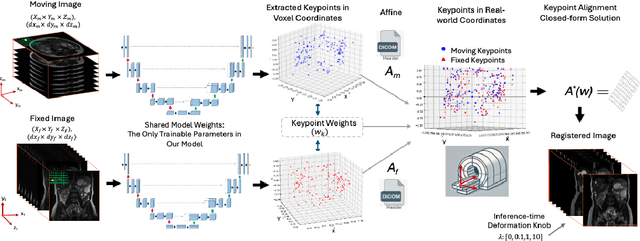



Many real-world settings require registration of a pair of medical images that differ in spatial resolution, which may arise from differences in image acquisition parameters like pixel spacing, slice thickness, and field-of-view. However, all previous machine learning-based registration techniques resample images onto a fixed resolution. This is suboptimal because resampling can introduce artifacts due to interpolation. To address this, we present RealKeyMorph (RKM), a resolution-agnostic method for image registration. RKM is an extension of KeyMorph, a registration framework which works by training a network to learn corresponding keypoints for a given pair of images, after which a closed-form keypoint matching step is used to derive the transformation that aligns them. To avoid resampling and enable operating on the raw data, RKM outputs keypoints in real-world coordinates of the scanner. To do this, we leverage the affine matrix produced by the scanner (e.g., MRI machine) that encodes the mapping from voxel coordinates to real world coordinates. By transforming keypoints into real-world space and integrating this into the training process, RKM effectively enables the extracted keypoints to be resolution-agnostic. In our experiments, we demonstrate the advantages of RKM on the registration task for orthogonal 2D stacks of abdominal MRIs, as well as 3D volumes with varying resolutions in brain datasets.
Generating Novel Brain Morphology by Deforming Learned Templates
Mar 07, 2025Designing generative models for 3D structural brain MRI that synthesize morphologically-plausible and attribute-specific (e.g., age, sex, disease state) samples is an active area of research. Existing approaches based on frameworks like GANs or diffusion models synthesize the image directly, which may limit their ability to capture intricate morphological details. In this work, we propose a 3D brain MRI generation method based on state-of-the-art latent diffusion models (LDMs), called MorphLDM, that generates novel images by applying synthesized deformation fields to a learned template. Instead of using a reconstruction-based autoencoder (as in a typical LDM), our encoder outputs a latent embedding derived from both an image and a learned template that is itself the output of a template decoder; this latent is passed to a deformation field decoder, whose output is applied to the learned template. A registration loss is minimized between the original image and the deformed template with respect to the encoder and both decoders. Empirically, our approach outperforms generative baselines on metrics spanning image diversity, adherence with respect to input conditions, and voxel-based morphometry. Our code is available at https://github.com/alanqrwang/morphldm.
Adapting to Shifting Correlations with Unlabeled Data Calibration
Sep 09, 2024



Distribution shifts between sites can seriously degrade model performance since models are prone to exploiting unstable correlations. Thus, many methods try to find features that are stable across sites and discard unstable features. However, unstable features might have complementary information that, if used appropriately, could increase accuracy. More recent methods try to adapt to unstable features at the new sites to achieve higher accuracy. However, they make unrealistic assumptions or fail to scale to multiple confounding features. We propose Generalized Prevalence Adjustment (GPA for short), a flexible method that adjusts model predictions to the shifting correlations between prediction target and confounders to safely exploit unstable features. GPA can infer the interaction between target and confounders in new sites using unlabeled samples from those sites. We evaluate GPA on several real and synthetic datasets, and show that it outperforms competitive baselines.
Knockout: A simple way to handle missing inputs
Jun 03, 2024

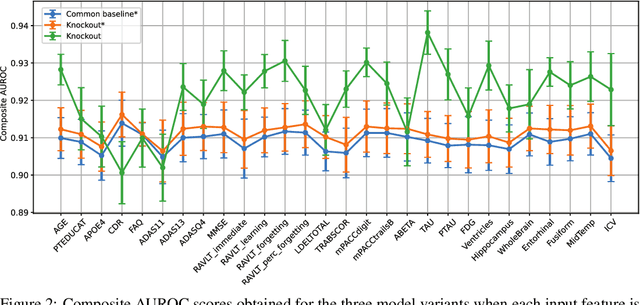

Deep learning models can extract predictive and actionable information from complex inputs. The richer the inputs, the better these models usually perform. However, models that leverage rich inputs (e.g., multi-modality) can be difficult to deploy widely, because some inputs may be missing at inference. Current popular solutions to this problem include marginalization, imputation, and training multiple models. Marginalization can obtain calibrated predictions but it is computationally costly and therefore only feasible for low dimensional inputs. Imputation may result in inaccurate predictions because it employs point estimates for missing variables and does not work well for high dimensional inputs (e.g., images). Training multiple models whereby each model takes different subsets of inputs can work well but requires knowing missing input patterns in advance. Furthermore, training and retaining multiple models can be costly. We propose an efficient way to learn both the conditional distribution using full inputs and the marginal distributions. Our method, Knockout, randomly replaces input features with appropriate placeholder values during training. We provide a theoretical justification of Knockout and show that it can be viewed as an implicit marginalization strategy. We evaluate Knockout in a wide range of simulations and real-world datasets and show that it can offer strong empirical performance.
BrainMorph: A Foundational Keypoint Model for Robust and Flexible Brain MRI Registration
May 22, 2024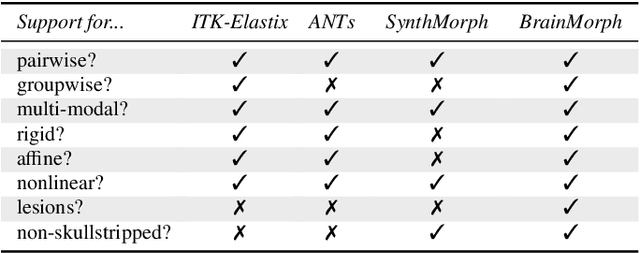



We present a keypoint-based foundation model for general purpose brain MRI registration, based on the recently-proposed KeyMorph framework. Our model, called BrainMorph, serves as a tool that supports multi-modal, pairwise, and scalable groupwise registration. BrainMorph is trained on a massive dataset of over 100,000 3D volumes, skull-stripped and non-skull-stripped, from nearly 16,000 unique healthy and diseased subjects. BrainMorph is robust to large misalignments, interpretable via interrogating automatically-extracted keypoints, and enables rapid and controllable generation of many plausible transformations with different alignment types and different degrees of nonlinearity at test-time. We demonstrate the superiority of BrainMorph in solving 3D rigid, affine, and nonlinear registration on a variety of multi-modal brain MRI scans of healthy and diseased subjects, in both the pairwise and groupwise setting. In particular, we show registration accuracy and speeds that surpass current state-of-the-art methods, especially in the context of large initial misalignments and large group settings. All code and models are available at https://github.com/alanqrwang/brainmorph.
Robust Learning via Conditional Prevalence Adjustment
Oct 24, 2023Healthcare data often come from multiple sites in which the correlations between confounding variables can vary widely. If deep learning models exploit these unstable correlations, they might fail catastrophically in unseen sites. Although many methods have been proposed to tackle unstable correlations, each has its limitations. For example, adversarial training forces models to completely ignore unstable correlations, but doing so may lead to poor predictive performance. Other methods (e.g. Invariant risk minimization [4]) try to learn domain-invariant representations that rely only on stable associations by assuming a causal data-generating process (input X causes class label Y ). Thus, they may be ineffective for anti-causal tasks (Y causes X), which are common in computer vision. We propose a method called CoPA (Conditional Prevalence-Adjustment) for anti-causal tasks. CoPA assumes that (1) generation mechanism is stable, i.e. label Y and confounding variable(s) Z generate X, and (2) the unstable conditional prevalence in each site E fully accounts for the unstable correlations between X and Y . Our crucial observation is that confounding variables are routinely recorded in healthcare settings and the prevalence can be readily estimated, for example, from a set of (Y, Z) samples (no need for corresponding samples of X). CoPA can work even if there is a single training site, a scenario which is often overlooked by existing methods. Our experiments on synthetic and real data show CoPA beating competitive baselines.
A Framework for Interpretability in Machine Learning for Medical Imaging
Oct 02, 2023

Interpretability for machine learning models in medical imaging (MLMI) is an important direction of research. However, there is a general sense of murkiness in what interpretability means. Why does the need for interpretability in MLMI arise? What goals does one actually seek to address when interpretability is needed? To answer these questions, we identify a need to formalize the goals and elements of interpretability in MLMI. By reasoning about real-world tasks and goals common in both medical image analysis and its intersection with machine learning, we identify four core elements of interpretability: localization, visual recognizability, physical attribution, and transparency. Overall, this paper formalizes interpretability needs in the context of medical imaging, and our applied perspective clarifies concrete MLMI-specific goals and considerations in order to guide method design and improve real-world usage. Our goal is to provide practical and didactic information for model designers and practitioners, inspire developers of models in the medical imaging field to reason more deeply about what interpretability is achieving, and suggest future directions of interpretability research.
Learning Invariant Representations with a Nonparametric Nadaraya-Watson Head
Sep 23, 2023Machine learning models will often fail when deployed in an environment with a data distribution that is different than the training distribution. When multiple environments are available during training, many methods exist that learn representations which are invariant across the different distributions, with the hope that these representations will be transportable to unseen domains. In this work, we present a nonparametric strategy for learning invariant representations based on the recently-proposed Nadaraya-Watson (NW) head. The NW head makes a prediction by comparing the learned representations of the query to the elements of a support set that consists of labeled data. We demonstrate that by manipulating the support set, one can encode different causal assumptions. In particular, restricting the support set to a single environment encourages the model to learn invariant features that do not depend on the environment. We present a causally-motivated setup for our modeling and training strategy and validate on three challenging real-world domain generalization tasks in computer vision.