 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Novel Brain Morphology by Deforming Learned Templates
Mar 07, 2025Designing generative models for 3D structural brain MRI that synthesize morphologically-plausible and attribute-specific (e.g., age, sex, disease state) samples is an active area of research. Existing approaches based on frameworks like GANs or diffusion models synthesize the image directly, which may limit their ability to capture intricate morphological details. In this work, we propose a 3D brain MRI generation method based on state-of-the-art latent diffusion models (LDMs), called MorphLDM, that generates novel images by applying synthesized deformation fields to a learned template. Instead of using a reconstruction-based autoencoder (as in a typical LDM), our encoder outputs a latent embedding derived from both an image and a learned template that is itself the output of a template decoder; this latent is passed to a deformation field decoder, whose output is applied to the learned template. A registration loss is minimized between the original image and the deformed template with respect to the encoder and both decoders. Empirically, our approach outperforms generative baselines on metrics spanning image diversity, adherence with respect to input conditions, and voxel-based morphometry. Our code is available at https://github.com/alanqrwang/morphldm.
Decoding natural image stimuli from fMRI data with a surface-based convolutional network
Dec 05, 2022Due to the low signal-to-noise ratio and limited resolution of functional MRI data, and the high complexity of natural images, reconstructing a visual stimulus from human brain fMRI measurements is a challenging task. In this work, we propose a novel approach for this task, which we call Cortex2Image, to decode visual stimuli with high semantic fidelity and rich fine-grained detail. In particular, we train a surface-based convolutional network model that maps from brain response to semantic image features first (Cortex2Semantic). We then combine this model with a high-quality image generator (Instance-Conditioned GAN) to train another mapping from brain response to fine-grained image features using a variational approach (Cortex2Detail). Image reconstructions obtained by our proposed method achieve state-of-the-art semantic fidelity, while yielding good fine-grained similarity with the ground-truth stimulus. Our code is available at: https://github.com/zijin-gu/meshconv-decoding.git.
Personalized visual encoding model construction with small data
Feb 04, 2022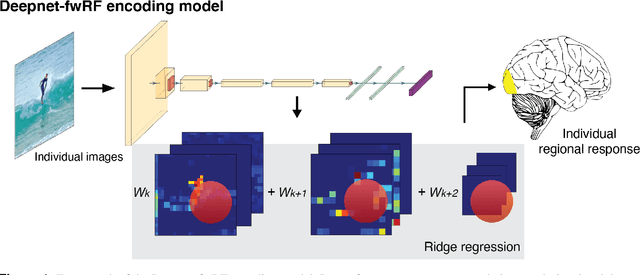
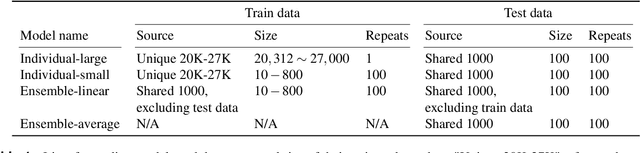
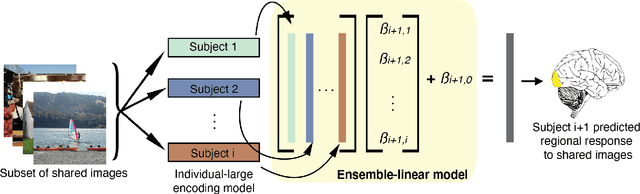
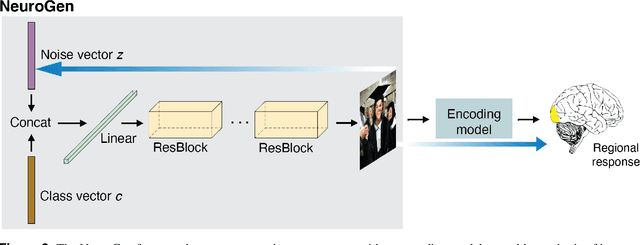
Encoding models that predict brain response patterns to stimuli are one way to capture this relationship between variability in bottom-up neural systems and individual's behavior or pathological state. However, they generally need a large amount of training data to achieve optimal accuracy. Here, we propose and test an alternative personalized ensemble encoding model approach to utilize existing encoding models, to create encoding models for novel individuals with relatively little stimuli-response data. We show that these personalized ensemble encoding models trained with small amounts of data for a specific individual, i.e. ~400 image-response pairs, achieve accuracy not different from models trained on ~24,000 image-response pairs for the same individual. Importantly, the personalized ensemble encoding models preserve patterns of inter-individual variability in the image-response relationship. Additionally, we use our personalized ensemble encoding model within the recently developed NeuroGen framework to generate optimal stimuli designed to maximize specific regions' activations for a specific individual. We show that the inter-individual differences in face area responses to images of dog vs human faces observed previously is replicated using NeuroGen with the ensemble encoding model. Finally, and most importantly, we show the proposed approach is robust against domain shift by validating on a prospectively collected set of image-response data in novel individuals with a different scanner and experimental setup. Our approach shows the potential to use previously collected, deeply sampled data to efficiently create accurate, personalized encoding models and, subsequently, personalized optimal synthetic images for new individuals scanned under different experimental conditions.
Temporal Feature Fusion with Sampling Pattern Optimization for Multi-echo Gradient Echo Acquisition and Image Reconstruction
Mar 10, 2021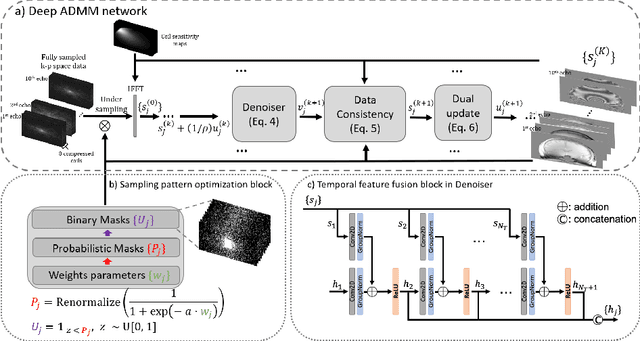

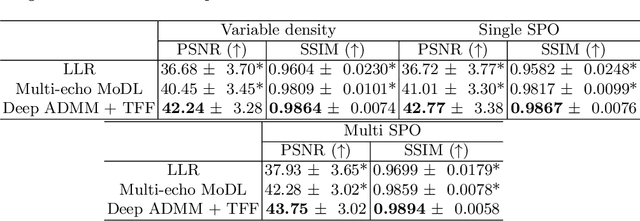
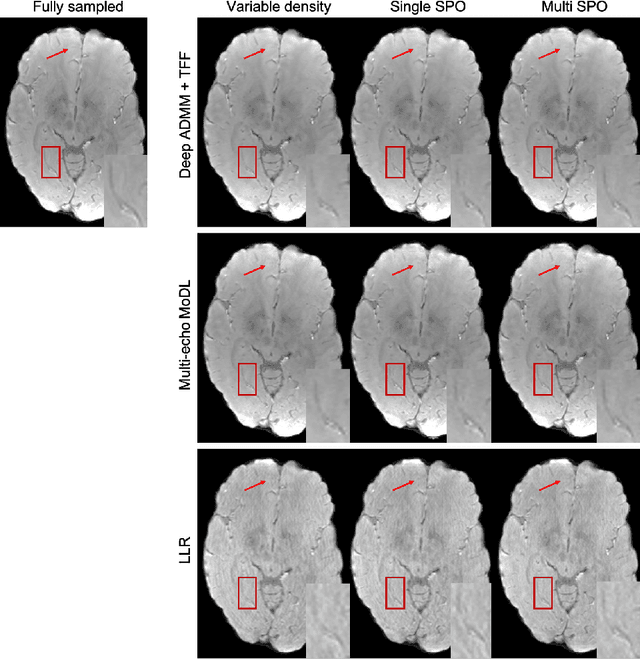
Quantitative imaging in MRI usually involves acquisition and reconstruction of a series of images at multi-echo time points, which possibly requires more scan time and specific reconstruction technique compared to conventional qualitative imaging. In this work, we focus on optimizing the acquisition and reconstruction process of multi-echo gradient echo pulse sequence for quantitative susceptibility mapping as one important quantitative imaging method in MRI. A multi-echo sampling pattern optimization block extended from LOUPE-ST is proposed to optimize the k-space sampling patterns along echoes. Besides, a recurrent temporal feature fusion block is proposed and inserted into a backbone deep ADMM network to capture the signal evolution along echo time during reconstruction. Experiments show that both blocks help improve multi-echo image reconstruction performance.
Ensembling Low Precision Models for Binary Biomedical Image Segmentation
Oct 16, 2020
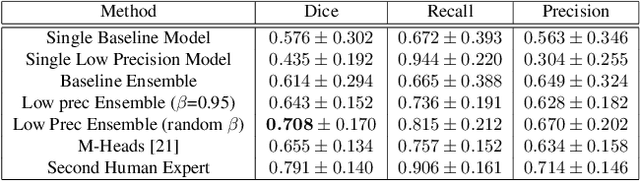


Segmentation of anatomical regions of interest such as vessels or small lesions in medical images is still a difficult problem that is often tackled with manual input by an expert. One of the major challenges for this task is that the appearance of foreground (positive) regions can be similar to background (negative) regions. As a result, many automatic segmentation algorithms tend to exhibit asymmetric errors, typically producing more false positives than false negatives. In this paper, we aim to leverage this asymmetry and train a diverse ensemble of models with very high recall, while sacrificing their precision. Our core idea is straightforward: A diverse ensemble of low precision and high recall models are likely to make different false positive errors (classifying background as foreground in different parts of the image), but the true positives will tend to be consistent. Thus, in aggregate the false positive errors will cancel out, yielding high performance for the ensemble. Our strategy is general and can be applied with any segmentation model. In three different applications (carotid artery segmentation in a neck CT angiography, myocardium segmentation in a cardiovascular MRI and multiple sclerosis lesion segmentation in a brain MRI), we show how the proposed approach can significantly boost the performance of a baseline segmentation method.
Extending LOUPE for K-space Under-sampling Pattern Optimization in Multi-coil MRI
Jul 28, 2020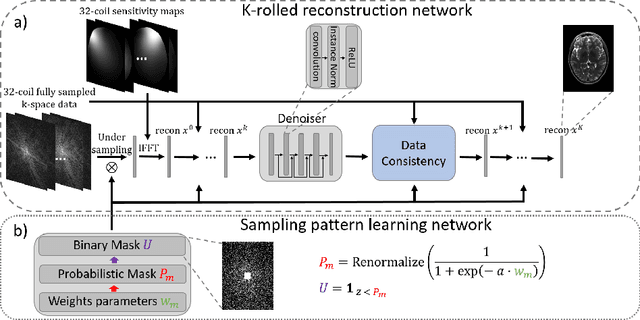
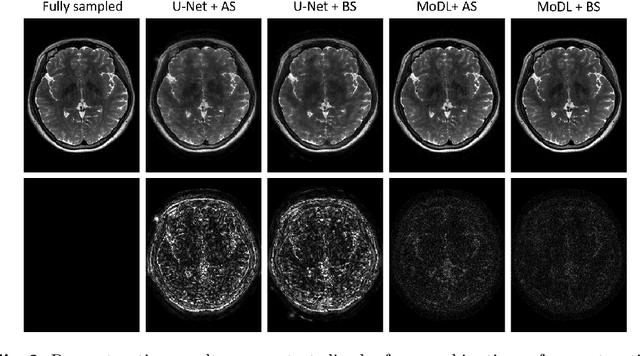


The previously established LOUPE (Learning-based Optimization of the Under-sampling Pattern) framework for optimizing the k-space sampling pattern in MRI was extended in three folds: firstly, fully sampled multi-coil k-space data from the scanner, rather than simulated k-space data from magnitude MR images in LOUPE, was retrospectively under-sampled to optimize the under-sampling pattern of in-vivo k-space data; secondly, binary stochastic k-space sampling, rather than approximate stochastic k-space sampling of LOUPE during training, was applied together with a straight-through (ST) estimator to estimate the gradient of the threshold operation in a neural network; thirdly, modified unrolled optimization network, rather than modified U-Net in LOUPE, was used as the reconstruction network in order to reconstruct multi-coil data properly and reduce the dependency on training data. Experimental results show that when dealing with the in-vivo k-space data, unrolled optimization network with binary under-sampling block and ST estimator had better reconstruction performance compared to the ones with either U-Net reconstruction network or approximate sampling pattern optimization network, and once trained, the learned optimal sampling pattern worked better than the hand-crafted variable density sampling pattern when deployed with other conventional reconstruction methods.
Synthetic Learning: Learn From Distributed Asynchronized Discriminator GAN Without Sharing Medical Image Data
Jun 14, 2020

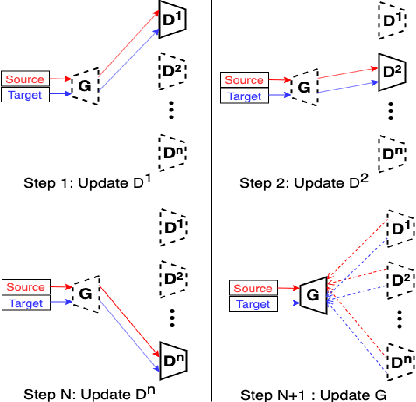

In this paper, we propose a data privacy-preserving and communication efficient distributed GAN learning framework named Distributed Asynchronized Discriminator GAN (AsynDGAN). Our proposed framework aims to train a central generator learns from distributed discriminator, and use the generated synthetic image solely to train the segmentation model.We validate the proposed framework on the application of health entities learning problem which is known to be privacy sensitive. Our experiments show that our approach: 1) could learn the real image's distribution from multiple datasets without sharing the patient's raw data. 2) is more efficient and requires lower bandwidth than other distributed deep learning methods. 3) achieves higher performance compared to the model trained by one real dataset, and almost the same performance compared to the model trained by all real datasets. 4) has provable guarantees that the generator could learn the distributed distribution in an all important fashion thus is unbiased.
3D Convolutional Neural Networks for Classification of Functional Connectomes
Jun 13, 2018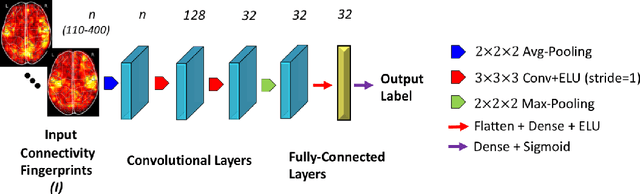
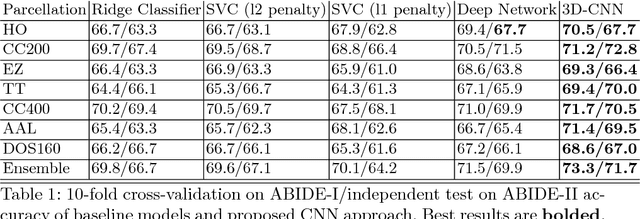
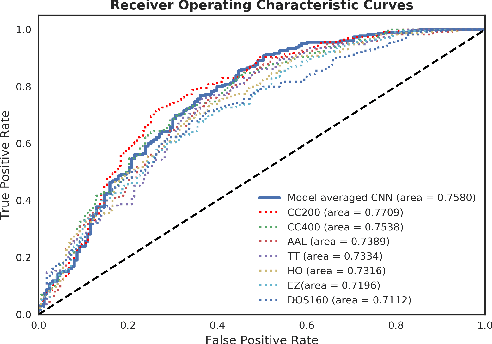
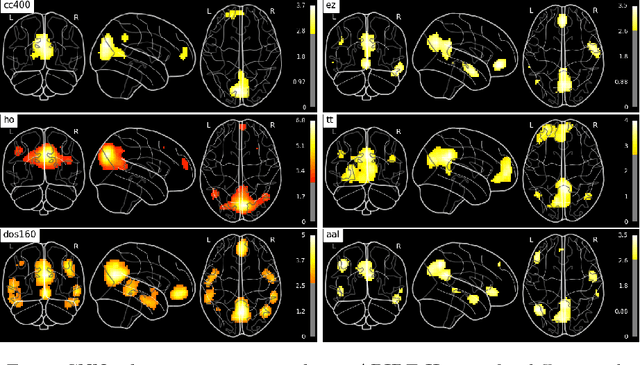
Resting-state functional MRI (rs-fMRI) scans hold the potential to serve as a diagnostic or prognostic tool for a wide variety of conditions, such as autism, Alzheimer's disease, and stroke. While a growing number of studies have demonstrated the promise of machine learning algorithms for rs-fMRI based clinical or behavioral prediction, most prior models have been limited in their capacity to exploit the richness of the data. For example, classification techniques applied to rs-fMRI often rely on region-based summary statistics and/or linear models. In this work, we propose a novel volumetric Convolutional Neural Network (CNN) framework that takes advantage of the full-resolution 3D spatial structure of rs-fMRI data and fits non-linear predictive models. We showcase our approach on a challenging large-scale dataset (ABIDE, with N > 2,000) and report state-of-the-art accuracy results on rs-fMRI-based discrimination of autism patients and healthy controls.