 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyeMVP: OCT-Informed Fundus Representation Learning via Paired CFP--OCT Pretraining
Jun 13, 2026Color fundus photography (CFP) is the mainstay for large-scale retinal screening, yet its diagnostic capacity is constrained by the lack of depth-resolved structural information. Optical coherence tomography (OCT) provides cross-sectional retinal anatomy, but is less accessible in population-level screening. Here, we present EyeMVP, a cross-modal retinal foundation model that uses paired CFP--OCT pretraining to learn OCT-informed CFP representations. EyeMVP is pretrained on 674,893 strict same-eye same-day paired CFP--OCT image triples from 112,642 patients across eight hospitals in China. The model uses cross-modal masked reconstruction to enrich CFP representations with OCT-associated supervision, while requiring only CFP images at inference. To accommodate the non-aligned imaging geometry between en-face CFP and cross-sectional OCT, EyeMVP combines source-constrained cross-attention with CFP-derived structural masks. Across 16 downstream tasks, including classification, segmentation, few-shot adaptation, and cross-modal retrieval, EyeMVP outperforms representative retinal foundation models and shows consistent gains on tasks involving macular and optic nerve structure. For CFP-challenging macular diseases, EyeMVP achieves an AUROC of 0.948 for macular edema (vs.~0.852 for EyeCLIP) and 0.825 for myopic macular schisis. In an exploratory reader study, EyeMVP exceeds junior and intermediate ophthalmologist groups but does not reach senior ophthalmologist performance on macular edema, while showing numerically higher balanced accuracy than all reader groups on myopic macular schisis. These results suggest that pixel-level cross-modal reconstruction can enrich CFP representations with OCT-associated supervision, providing a practical route toward stronger CFP-based retinal analysis in screening settings.
UniX: Unifying Autoregression and Diffusion for Chest X-Ray Understanding and Generation
Jan 16, 2026Despite recent progress, medical foundation models still struggle to unify visual understanding and generation, as these tasks have inherently conflicting goals: semantic abstraction versus pixel-level reconstruction. Existing approaches, typically based on parameter-shared autoregressive architectures, frequently lead to compromised performance in one or both tasks. To address this, we present UniX, a next-generation unified medical foundation model for chest X-ray understanding and generation. UniX decouples the two tasks into an autoregressive branch for understanding and a diffusion branch for high-fidelity generation. Crucially, a cross-modal self-attention mechanism is introduced to dynamically guide the generation process with understanding features. Coupled with a rigorous data cleaning pipeline and a multi-stage training strategy, this architecture enables synergistic collaboration between tasks while leveraging the strengths of diffusion models for superior generation. On two representative benchmarks, UniX achieves a 46.1% improvement in understanding performance (Micro-F1) and a 24.2% gain in generation quality (FD-RadDino), using only a quarter of the parameters of LLM-CXR. By achieving performance on par with task-specific models, our work establishes a scalable paradigm for synergistic medical image understanding and generation. Codes and models are available at https://github.com/ZrH42/UniX.
A DeepSeek-Powered AI System for Automated Chest Radiograph Interpretation in Clinical Practice
Dec 23, 2025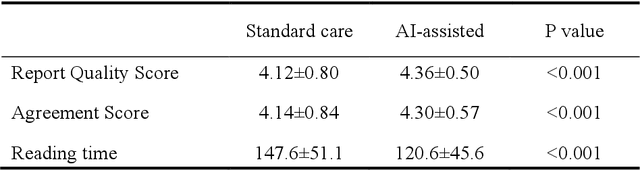
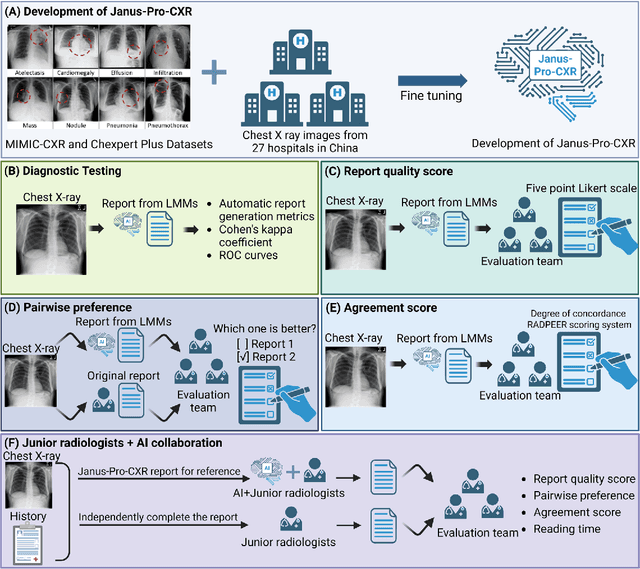
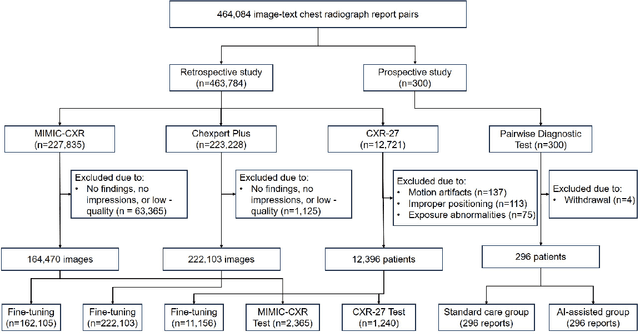
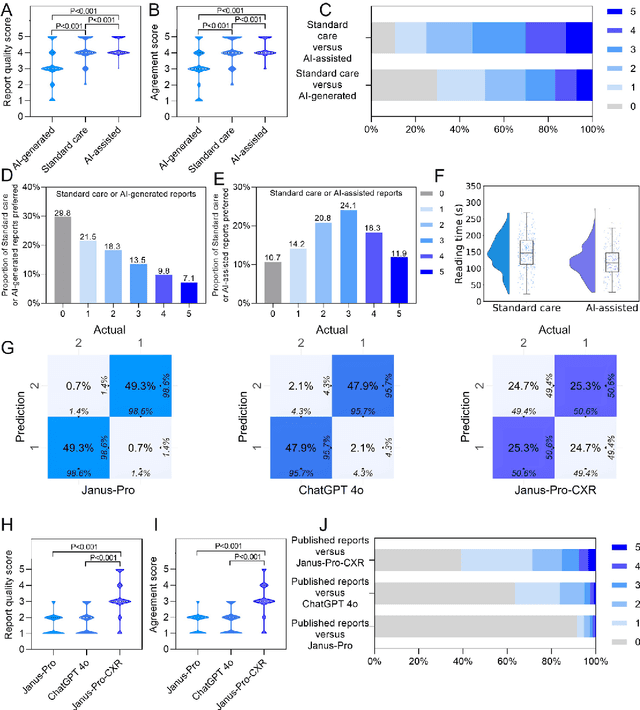
A global shortage of radiologists has been exacerbated by the significant volume of chest X-ray workloads, particularly in primary care. Although multimodal large language models show promise, existing evaluations predominantly rely on automated metrics or retrospective analyses, lacking rigorous prospective clinical validation. Janus-Pro-CXR (1B), a chest X-ray interpretation system based on DeepSeek Janus-Pro model, was developed and rigorously validated through a multicenter prospective trial (NCT07117266). Our system outperforms state-of-the-art X-ray report generation models in automated report generation, surpassing even larger-scale models including ChatGPT 4o (200B parameters), while demonstrating reliable detection of six clinically critical radiographic findings. Retrospective evaluation confirms significantly higher report accuracy than Janus-Pro and ChatGPT 4o. In prospective clinical deployment, AI assistance significantly improved report quality scores, reduced interpretation time by 18.3% (P < 0.001), and was preferred by a majority of experts in 54.3% of cases. Through lightweight architecture and domain-specific optimization, Janus-Pro-CXR improves diagnostic reliability and workflow efficiency, particularly in resource-constrained settings. The model architecture and implementation framework will be open-sourced to facilitate the clinical translation of AI-assisted radiology solutions.
Learning Camouflaged Object Detection from Noisy Pseudo Label
Jul 18, 2024Existing Camouflaged Object Detection (COD) methods rely heavily on large-scale pixel-annotated training sets, which are both time-consuming and labor-intensive. Although weakly supervised methods offer higher annotation efficiency, their performance is far behind due to the unclear visual demarcations between foreground and background in camouflaged images. In this paper, we explore the potential of using boxes as prompts in camouflaged scenes and introduce the first weakly semi-supervised COD method, aiming for budget-efficient and high-precision camouflaged object segmentation with an extremely limited number of fully labeled images. Critically, learning from such limited set inevitably generates pseudo labels with serious noisy pixels. To address this, we propose a noise correction loss that facilitates the model's learning of correct pixels in the early learning stage, and corrects the error risk gradients dominated by noisy pixels in the memorization stage, ultimately achieving accurate segmentation of camouflaged objects from noisy labels. When using only 20% of fully labeled data, our method shows superior performance over the state-of-the-art methods.
Objects in Semantic Topology
Oct 06, 2021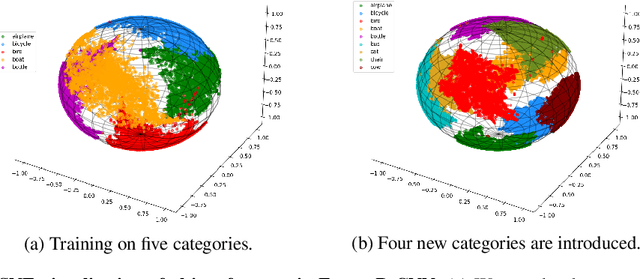
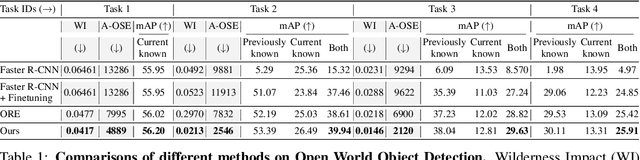
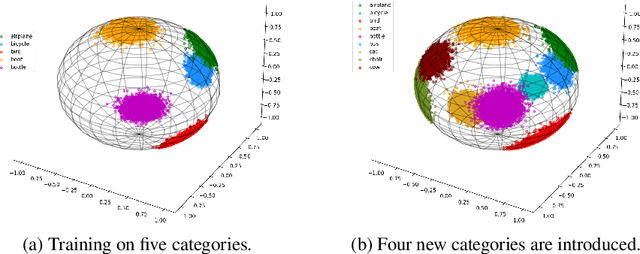
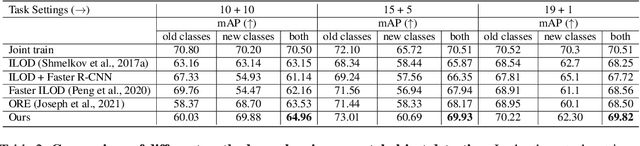
A more realistic object detection paradigm, Open-World Object Detection, has arisen increasing research interests in the community recently. A qualified open-world object detector can not only identify objects of known categories, but also discover unknown objects, and incrementally learn to categorize them when their annotations progressively arrive. Previous works rely on independent modules to recognize unknown categories and perform incremental learning, respectively. In this paper, we provide a unified perspective: Semantic Topology. During the life-long learning of an open-world object detector, all object instances from the same category are assigned to their corresponding pre-defined node in the semantic topology, including the `unknown' category. This constraint builds up discriminative feature representations and consistent relationships among objects, thus enabling the detector to distinguish unknown objects out of the known categories, as well as making learned features of known objects undistorted when learning new categories incrementally. Extensive experiments demonstrate that semantic topology, either randomly-generated or derived from a well-trained language model, could outperform the current state-of-the-art open-world object detectors by a large margin, e.g., the absolute open-set error is reduced from 7832 to 2546, exhibiting the inherent superiority of semantic topology on open-world object detection.
Learning Image-Specific Attributes by Hyperbolic Neighborhood Graph Propagation
May 25, 2019

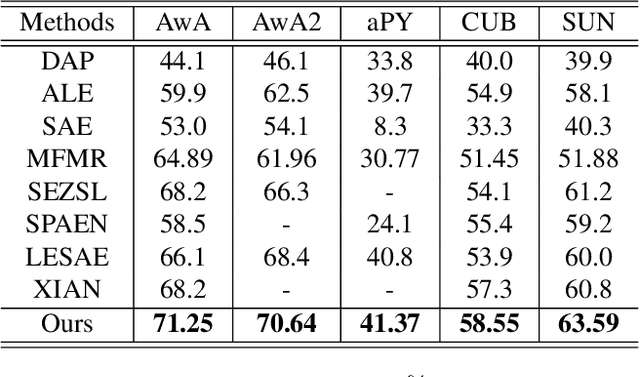
As a kind of semantic representation of visual object descriptions, attributes are widely used in various computer vision tasks. In most of existing attribute-based research, class-specific attributes (CSA), which are class-level annotations, are usually adopted due to its low annotation cost for each class instead of each individual image. However, class-specific attributes are usually noisy because of annotation errors and diversity of individual images. Therefore, it is desirable to obtain image-specific attributes (ISA), which are image-level annotations, from the original class-specific attributes. In this paper, we propose to learn image-specific attributes by graph-based attribute propagation. Considering the intrinsic property of hyperbolic geometry that its distance expands exponentially, hyperbolic neighborhood graph (HNG) is constructed to characterize the relationship between samples. Based on HNG, we define neighborhood consistency for each sample to identify inconsistent samples. Subsequently, inconsistent samples are refined based on their neighbors in HNG. Extensive experiments on five benchmark datasets demonstrate the significant superiority of the learned image-specific attributes over the original class-specific attributes in the zero-shot object classification task.