 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High Energy-Efficiency Multi-core Neuromorphic Architecture for Deep SNN Training
Dec 10, 2024
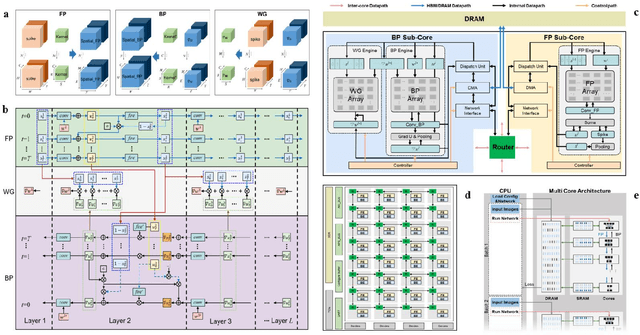
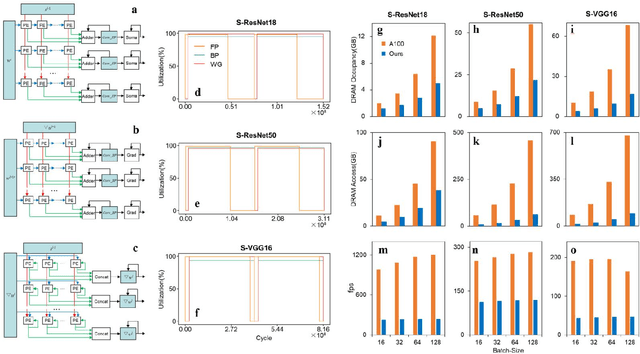
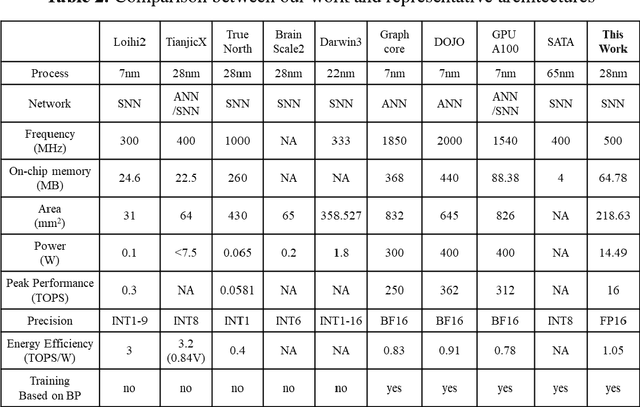
There is a growing necessity for edge training to adapt to dynamically changing environment. Neuromorphic computing represents a significant pathway for high-efficiency intelligent computation in energy-constrained edges, but existing neuromorphic architectures lack the ability of directly training spiking neural networks (SNNs) based on backpropagation. We develop a multi-core neuromorphic architecture with Feedforward-Propagation, Back-Propagation, and Weight-Gradient engines in each core, supporting high efficient parallel computing at both the engine and core levels. It combines various data flows and sparse computation optimization by fully leveraging the sparsity in SNN training, obtaining a high energy efficiency of 1.05TFLOPS/W@ FP16 @ 28nm, 55 ~ 85% reduction of DRAM access compared to A100 GPU in SNN trainings, and a 20-core deep SNN training and a 5-worker federated learning on FPGAs. Our study develops the first multi-core neuromorphic architecture supporting the direct SNN training, facilitating the neuromorphic computing in edge-learnable applications.
Core Placement Optimization of Many-core Brain-Inspired Near-Storage Systems for Spiking Neural Network Training
Nov 29, 2024With the increasing application scope of spiking neural networks (SNN), the complexity of SNN models has surged, leading to an exponential growth in demand for AI computility. As the new generation computing architecture of the neural networks, the efficiency and power consumption of distributed storage and parallel computing in the many-core near-memory computing system have attracted much attention. Among them, the mapping problem from logical cores to physical cores is one of the research hotspots. In order to improve the computing parallelism and system throughput of the many-core near-memory computing system, and to reduce power consumption, we propose a SNN training many-core deployment optimization method based on Off-policy Deterministic Actor-Critic. We utilize deep reinforcement learning as a nonlinear optimizer, treating the many-core topology as network graph features and using graph convolution to input the many-core structure into the policy network. We update the parameters of the policy network through near-end policy optimization to achieve deployment optimization of SNN models in the many-core near-memory computing architecture to reduce chip power consumption. To handle large-dimensional action spaces, we use continuous values matching the number of cores as the output of the policy network and then discretize them again to obtain new deployment schemes. Furthermore, to further balance inter-core computation latency and improve system throughput, we propose a model partitioning method with a balanced storage and computation strategy. Our method overcomes the problems such as uneven computation and storage loads between cores, and the formation of local communication hotspots, significantly reducing model training time, communication costs, and average flow load between cores in the many-core near-memory computing architecture.