 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Ground-aerial Transportation System for Pest Control Enabled by AI-based Autonomous Nano-UAVs
Feb 20, 2025Efficient crop production requires early detection of pest outbreaks and timely treatments; we consider a solution based on a fleet of multiple autonomous miniaturized unmanned aerial vehicles (nano-UAVs) to visually detect pests and a single slower heavy vehicle that visits the detected outbreaks to deliver treatments. To cope with the extreme limitations aboard nano-UAVs, e.g., low-resolution sensors and sub-100 mW computational power budget, we design, fine-tune, and optimize a tiny image-based convolutional neural network (CNN) for pest detection. Despite the small size of our CNN (i.e., 0.58 GOps/inference), on our dataset, it scores a mean average precision (mAP) of 0.79 in detecting harmful bugs, i.e., 14% lower mAP but 32x fewer operations than the best-performing CNN in the literature. Our CNN runs in real-time at 6.8 frame/s, requiring 33 mW on a GWT GAP9 System-on-Chip aboard a Crazyflie nano-UAV. Then, to cope with in-field unexpected obstacles, we leverage a global+local path planner based on the A* algorithm. The global path planner determines the best route for the nano-UAV to sweep the entire area, while the local one runs up to 50 Hz aboard our nano-UAV and prevents collision by adjusting the short-distance path. Finally, we demonstrate with in-simulator experiments that once a 25 nano-UAVs fleet has combed a 200x200 m vineyard, collected information can be used to plan the best path for the tractor, visiting all and only required hotspots. In this scenario, our efficient transportation system, compared to a traditional single-ground vehicle performing both inspection and treatment, can save up to 20 h working time.
Accelerating Image-based Pest Detection on a Heterogeneous Multi-core Microcontroller
Aug 29, 2024

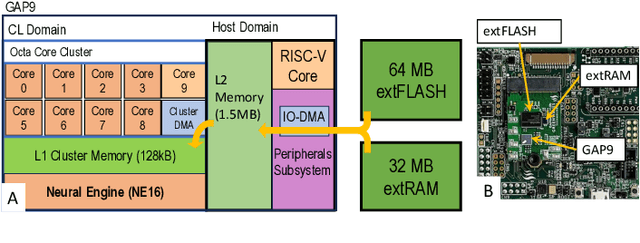

The codling moth pest poses a significant threat to global crop production, with potential losses of up to 80% in apple orchards. Special camera-based sensor nodes are deployed in the field to record and transmit images of trapped insects to monitor the presence of the pest. This paper investigates the embedding of computer vision algorithms in the sensor node using a novel State-of-the-Art Microcontroller Unit (MCU), the GreenWaves Technologies' GAP9 System-on-Chip, which combines 10 RISC-V general purposes cores with a convolution hardware accelerator. We compare the performance of a lightweight Viola-Jones detector algorithm with a Convolutional Neural Network (CNN), MobileNetV3-SSDLite, trained for the pest detection task. On two datasets that differentiate for the distance between the camera sensor and the pest targets, the CNN generalizes better than the other method and achieves a detection accuracy between 83% and 72%. Thanks to the GAP9's CNN accelerator, the CNN inference task takes only 147 ms to process a 320$\times$240 image. Compared to the GAP8 MCU, which only relies on general-purpose cores for processing, we achieved 9.5$\times$ faster inference speed. When running on a 1000 mAh battery at 3.7 V, the estimated lifetime is approximately 199 days, processing an image every 30 seconds. Our study demonstrates that the novel heterogeneous MCU can perform end-to-end CNN inference with an energy consumption of just 4.85 mJ, matching the efficiency of the simpler Viola-Jones algorithm and offering power consumption up to 15$\times$ lower than previous methods. Code at: https://github.com/Bomps4/TAFE_Pest_Detection
Fusing Multi-sensor Input with State Information on TinyML Brains for Autonomous Nano-drones
Apr 03, 2024


Autonomous nano-drones (~10 cm in diameter), thanks to their ultra-low power TinyML-based brains, are capable of coping with real-world environments. However, due to their simplified sensors and compute units, they are still far from the sense-and-act capabilities shown in their bigger counterparts. This system paper presents a novel deep learning-based pipeline that fuses multi-sensorial input (i.e., low-resolution images and 8x8 depth map) with the robot's state information to tackle a human pose estimation task. Thanks to our design, the proposed system -- trained in simulation and tested on a real-world dataset -- improves a state-unaware State-of-the-Art baseline by increasing the R^2 regression metric up to 0.10 on the distance's prediction.
High-throughput Visual Nano-drone to Nano-drone Relative Localization using Onboard Fully Convolutional Networks
Feb 21, 2024

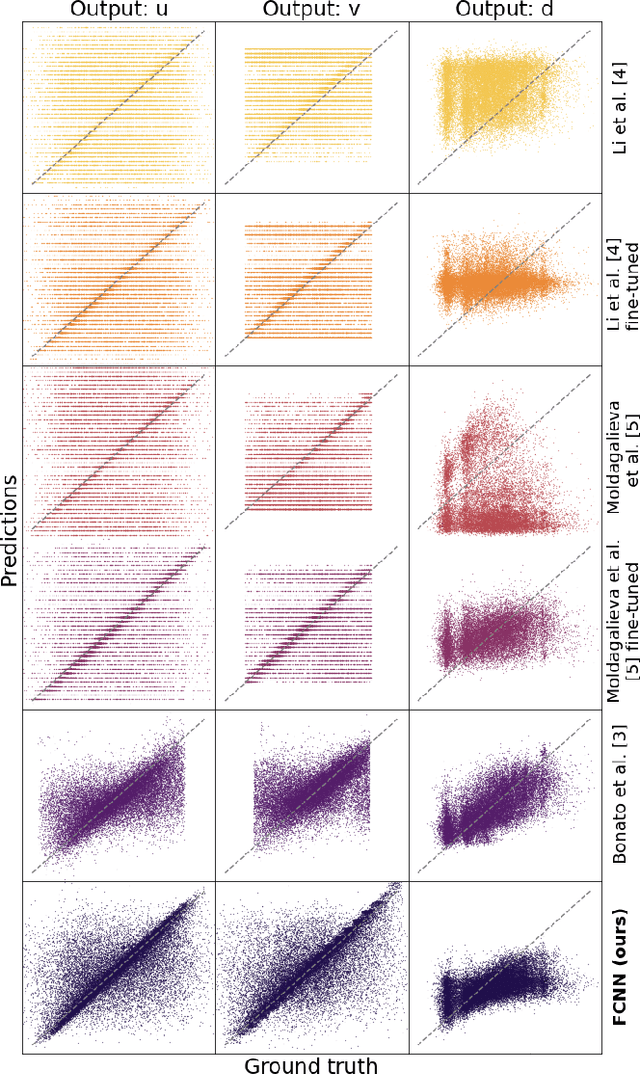

Relative drone-to-drone localization is a fundamental building block for any swarm operations. We address this task in the context of miniaturized nano-drones, i.e., 10cm in diameter, which show an ever-growing interest due to novel use cases enabled by their reduced form factor. The price for their versatility comes with limited onboard resources, i.e., sensors, processing units, and memory, which limits the complexity of the onboard algorithms. A traditional solution to overcome these limitations is represented by lightweight deep learning models directly deployed aboard nano-drones. This work tackles the challenging relative pose estimation between nano-drones using only a gray-scale low-resolution camera and an ultra-low-power System-on-Chip (SoC) hosted onboard. We present a vertically integrated system based on a novel vision-based fully convolutional neural network (FCNN), which runs at 39Hz within 101mW onboard a Crazyflie nano-drone extended with the GWT GAP8 SoC. We compare our FCNN against three State-of-the-Art (SoA) systems. Considering the best-performing SoA approach, our model results in an R-squared improvement from 32 to 47% on the horizontal image coordinate and from 18 to 55% on the vertical image coordinate, on a real-world dataset of 30k images. Finally, our in-field tests show a reduction of the average tracking error of 37% compared to a previous SoA work and an endurance performance up to the entire battery lifetime of 4 minutes.
Self-Supervised Learning of Visual Robot Localization Using LED State Prediction as a Pretext Task
Feb 15, 2024



We propose a novel self-supervised approach for learning to visually localize robots equipped with controllable LEDs. We rely on a few training samples labeled with position ground truth and many training samples in which only the LED state is known, whose collection is cheap. We show that using LED state prediction as a pretext task significantly helps to learn the visual localization end task. The resulting model does not require knowledge of LED states during inference. We instantiate the approach to visual relative localization of nano-quadrotors: experimental results show that using our pretext task significantly improves localization accuracy (from 68.3% to 76.2%) and outperforms alternative strategies, such as a supervised baseline, model pre-training, and an autoencoding pretext task. We deploy our model aboard a 27-g Crazyflie nano-drone, running at 21 fps, in a position-tracking task of a peer nano-drone. Our approach, relying on position labels for only 300 images, yields a mean tracking error of 4.2 cm versus 11.9 cm of a supervised baseline model trained without our pretext task. Videos and code of the proposed approach are available at https://github.com/idsia-robotics/leds-as-pretext
Adaptive Deep Learning for Efficient Visual Pose Estimation aboard Ultra-low-power Nano-drones
Jan 26, 2024



Sub-10cm diameter nano-drones are gaining momentum thanks to their applicability in scenarios prevented to bigger flying drones, such as in narrow environments and close to humans. However, their tiny form factor also brings their major drawback: ultra-constrained memory and processors for the onboard execution of their perception pipelines. Therefore, lightweight deep learning-based approaches are becoming increasingly popular, stressing how computational efficiency and energy-saving are paramount as they can make the difference between a fully working closed-loop system and a failing one. In this work, to maximize the exploitation of the ultra-limited resources aboard nano-drones, we present a novel adaptive deep learning-based mechanism for the efficient execution of a vision-based human pose estimation task. We leverage two State-of-the-Art (SoA) convolutional neural networks (CNNs) with different regression performance vs. computational costs trade-offs. By combining these CNNs with three novel adaptation strategies based on the output's temporal consistency and on auxiliary tasks to swap the CNN being executed proactively, we present six different systems. On a real-world dataset and the actual nano-drone hardware, our best-performing system, compared to executing only the bigger and most accurate SoA model, shows 28% latency reduction while keeping the same mean absolute error (MAE), 3% MAE reduction while being iso-latency, and the absolute peak performance, i.e., 6% better than SoA model.
Sim-to-Real Vision-depth Fusion CNNs for Robust Pose Estimation Aboard Autonomous Nano-quadcopter
Aug 03, 2023



Nano-quadcopters are versatile platforms attracting the interest of both academia and industry. Their tiny form factor, i.e., $\,$10 cm diameter, makes them particularly useful in narrow scenarios and harmless in human proximity. However, these advantages come at the price of ultra-constrained onboard computational and sensorial resources for autonomous operations. This work addresses the task of estimating human pose aboard nano-drones by fusing depth and images in a novel CNN exclusively trained in simulation yet capable of robust predictions in the real world. We extend a commercial off-the-shelf (COTS) Crazyflie nano-drone -- equipped with a 320$\times$240 px camera and an ultra-low-power System-on-Chip -- with a novel multi-zone (8$\times$8) depth sensor. We design and compare different deep-learning models that fuse depth and image inputs. Our models are trained exclusively on simulated data for both inputs, and transfer well to the real world: field testing shows an improvement of 58% and 51% of our depth+camera system w.r.t. a camera-only State-of-the-Art baseline on the horizontal and angular mean pose errors, respectively. Our prototype is based on COTS components, which facilitates reproducibility and adoption of this novel class of systems.
Deep Neural Network Architecture Search for Accurate Visual Pose Estimation aboard Nano-UAVs
Mar 03, 2023



Miniaturized autonomous unmanned aerial vehicles (UAVs) are an emerging and trending topic. With their form factor as big as the palm of one hand, they can reach spots otherwise inaccessible to bigger robots and safely operate in human surroundings. The simple electronics aboard such robots (sub-100mW) make them particularly cheap and attractive but pose significant challenges in enabling onboard sophisticated intelligence. In this work, we leverage a novel neural architecture search (NAS) technique to automatically identify several Pareto-optimal convolutional neural networks (CNNs) for a visual pose estimation task. Our work demonstrates how real-life and field-tested robotics applications can concretely leverage NAS technologies to automatically and efficiently optimize CNNs for the specific hardware constraints of small UAVs. We deploy several NAS-optimized CNNs and run them in closed-loop aboard a 27-g Crazyflie nano-UAV equipped with a parallel ultra-low power System-on-Chip. Our results improve the State-of-the-Art by reducing the in-field control error of 32% while achieving a real-time onboard inference-rate of ~10Hz@10mW and ~50Hz@90mW.