 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyDEVO: Deep Event-based Visual Odometry on Ultra-low-power Multi-core Microcontrollers
Apr 09, 2026A key task in embedded vision is visual odometry (VO), which estimates camera motion from visual sensors, and it is a core component in many embedded power-constrained systems, from autonomous robots to augmented and virtual reality wearable devices. The newest class of VO systems combines deep learning models with bio-inspired event-based cameras, which are robust to motion blur and lighting conditions. However, state-of-the-art (SoA) event-based VO algorithms require significant memory and computation. For example, the leading approach DEVO requires 733 MB of memory and 155 billion multiply-accumulate (MAC) operations per frame. We present TinyDEVO, an event-based VO deep learning model designed for resource-constrained microcontroller units (MCUs). We deploy TinyDEVO on an ultra-low-power (ULP) 9-core RISC-V-based MCU, achieving a throughput of approximately 1.2 frames per second with an average power consumption of only 86 mW. Thanks to our neural network architectural optimizations and hyperparameter tuning, TinyDEVO reduces the memory footprint by 11.5x (to 63.8 MB) and the number of operations per frame by 29.7x (to 5.2 billion MACs per frame) compared to DEVO, while maintaining an average trajectory error of 27 cm, i.e., only 19 cm higher than DEVO, on three state-of-the-art datasets. Our work demonstrates, for the first time, the feasibility of an event-based VO pipeline on ultra-low-power devices.
Tiny-DroNeRF: Tiny Neural Radiance Fields aboard Federated Learning-enabled Nano-drones
Mar 02, 2026Sub-30g nano-sized aerial robots can leverage their agility and form factor to autonomously explore cluttered and narrow environments, like in industrial inspection and search and rescue missions. However, the price for their tiny size is a strong limit in their resources, i.e., sub-100 mW microcontroller units (MCUs) delivering $\sim$100 GOps/s at best, and memory budgets well below 100 MB. Despite these strict constraints, we aim to enable complex vision-based tasks aboard nano-drones, such as dense 3D scene reconstruction: a key robotic task underlying fundamental capabilities like spatial awareness and motion planning. Top-performing 3D reconstruction methods leverage neural radiance fields (NeRF) models, which require GBs of memory and massive computation, usually delivered by high-end GPUs consuming 100s of Watts. Our work introduces Tiny-DroNeRF, a lightweight NeRF model, based on Instant-NGP, and optimized for running on a GAP9 ultra-low-power (ULP) MCU aboard our nano-drones. Then, we further empower our Tiny-DroNeRF by leveraging a collaborative federated learning scheme, which distributes the model training among multiple nano-drones. Our experimental results show a 96% reduction in Tiny-DroNeRF's memory footprint compared to Instant-NGP, with only a 5.7 dB drop in reconstruction accuracy. Finally, our federated learning scheme allows Tiny-DroNeRF to train with an amount of data otherwise impossible to keep in a single drone's memory, increasing the overall reconstruction accuracy. Ultimately, our work combines, for the first time, NeRF training on an ULP MCU with federated learning on nano-drones.
NanoCockpit: Performance-optimized Application Framework for AI-based Autonomous Nanorobotics
Jan 12, 2026Autonomous nano-drones, powered by vision-based tiny machine learning (TinyML) models, are a novel technology gaining momentum thanks to their broad applicability and pushing scientific advancement on resource-limited embedded systems. Their small form factor, i.e., a few 10s grams, severely limits their onboard computational resources to sub-\SI{100}{\milli\watt} microcontroller units (MCUs). The Bitcraze Crazyflie nano-drone is the \textit{de facto} standard, offering a rich set of programmable MCUs for low-level control, multi-core processing, and radio transmission. However, roboticists very often underutilize these onboard precious resources due to the absence of a simple yet efficient software layer capable of time-optimal pipelining of multi-buffer image acquisition, multi-core computation, intra-MCUs data exchange, and Wi-Fi streaming, leading to sub-optimal control performances. Our \textit{NanoCockpit} framework aims to fill this gap, increasing the throughput and minimizing the system's latency, while simplifying the developer experience through coroutine-based multi-tasking. In-field experiments on three real-world TinyML nanorobotics applications show our framework achieves ideal end-to-end latency, i.e. zero overhead due to serialized tasks, delivering quantifiable improvements in closed-loop control performance ($-$30\% mean position error, mission success rate increased from 40\% to 100\%).
Nonlinear System Identification Nano-drone Benchmark
Dec 16, 2025We introduce a benchmark for system identification based on 75k real-world samples from the Crazyflie 2.1 Brushless nano-quadrotor, a sub-50g aerial vehicle widely adopted in robotics research. The platform presents a challenging testbed due to its multi-input, multi-output nature, open-loop instability, and nonlinear dynamics under agile maneuvers. The dataset comprises four aggressive trajectories with synchronized 4-dimensional motor inputs and 13-dimensional output measurements. To enable fair comparison of identification methods, the benchmark includes a suite of multi-horizon prediction metrics for evaluating both one-step and multi-step error propagation. In addition to the data, we provide a detailed description of the platform and experimental setup, as well as baseline models highlighting the challenge of accurate prediction under real-world noise and actuation nonlinearities. All data, scripts, and reference implementations are released as open-source at https://github.com/idsia-robotics/nanodrone-sysid-benchmark to facilitate transparent comparison of algorithms and support research on agile, miniaturized aerial robotics.
A Map-free Deep Learning-based Framework for Gate-to-Gate Monocular Visual Navigation aboard Miniaturized Aerial Vehicles
Mar 07, 2025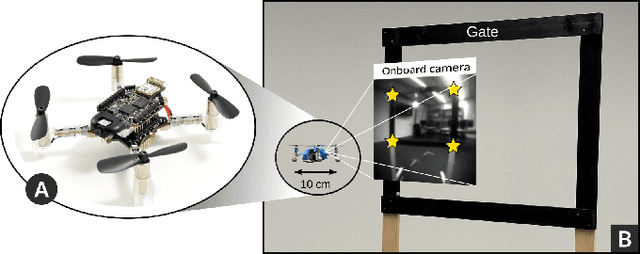


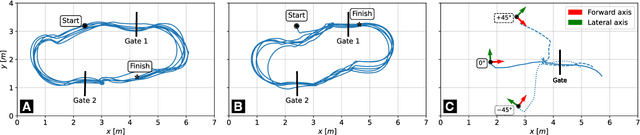
Palm-sized autonomous nano-drones, i.e., sub-50g in weight, recently entered the drone racing scenario, where they are tasked to avoid obstacles and navigate as fast as possible through gates. However, in contrast with their bigger counterparts, i.e., kg-scale drones, nano-drones expose three orders of magnitude less onboard memory and compute power, demanding more efficient and lightweight vision-based pipelines to win the race. This work presents a map-free vision-based (using only a monocular camera) autonomous nano-drone that combines a real-time deep learning gate detection front-end with a classic yet elegant and effective visual servoing control back-end, only relying on onboard resources. Starting from two state-of-the-art tiny deep learning models, we adapt them for our specific task, and after a mixed simulator-real-world training, we integrate and deploy them aboard our nano-drone. Our best-performing pipeline costs of only 24M multiply-accumulate operations per frame, resulting in a closed-loop control performance of 30 Hz, while achieving a gate detection root mean square error of 1.4 pixels, on our ~20k real-world image dataset. In-field experiments highlight the capability of our nano-drone to successfully navigate through 15 gates in 4 min, never crashing and covering a total travel distance of ~100m, with a peak flight speed of 1.9 m/s. Finally, to stress the generalization capability of our system, we also test it in a never-seen-before environment, where it navigates through gates for more than 4 min.
An Efficient Ground-aerial Transportation System for Pest Control Enabled by AI-based Autonomous Nano-UAVs
Feb 20, 2025Efficient crop production requires early detection of pest outbreaks and timely treatments; we consider a solution based on a fleet of multiple autonomous miniaturized unmanned aerial vehicles (nano-UAVs) to visually detect pests and a single slower heavy vehicle that visits the detected outbreaks to deliver treatments. To cope with the extreme limitations aboard nano-UAVs, e.g., low-resolution sensors and sub-100 mW computational power budget, we design, fine-tune, and optimize a tiny image-based convolutional neural network (CNN) for pest detection. Despite the small size of our CNN (i.e., 0.58 GOps/inference), on our dataset, it scores a mean average precision (mAP) of 0.79 in detecting harmful bugs, i.e., 14% lower mAP but 32x fewer operations than the best-performing CNN in the literature. Our CNN runs in real-time at 6.8 frame/s, requiring 33 mW on a GWT GAP9 System-on-Chip aboard a Crazyflie nano-UAV. Then, to cope with in-field unexpected obstacles, we leverage a global+local path planner based on the A* algorithm. The global path planner determines the best route for the nano-UAV to sweep the entire area, while the local one runs up to 50 Hz aboard our nano-UAV and prevents collision by adjusting the short-distance path. Finally, we demonstrate with in-simulator experiments that once a 25 nano-UAVs fleet has combed a 200x200 m vineyard, collected information can be used to plan the best path for the tractor, visiting all and only required hotspots. In this scenario, our efficient transportation system, compared to a traditional single-ground vehicle performing both inspection and treatment, can save up to 20 h working time.
Accelerating Image-based Pest Detection on a Heterogeneous Multi-core Microcontroller
Aug 29, 2024

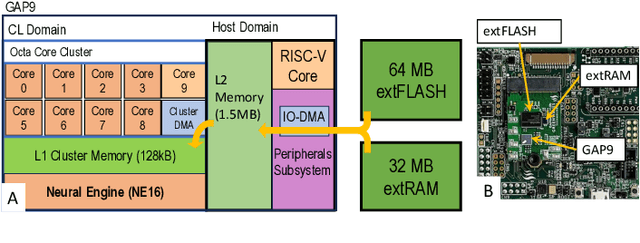

The codling moth pest poses a significant threat to global crop production, with potential losses of up to 80% in apple orchards. Special camera-based sensor nodes are deployed in the field to record and transmit images of trapped insects to monitor the presence of the pest. This paper investigates the embedding of computer vision algorithms in the sensor node using a novel State-of-the-Art Microcontroller Unit (MCU), the GreenWaves Technologies' GAP9 System-on-Chip, which combines 10 RISC-V general purposes cores with a convolution hardware accelerator. We compare the performance of a lightweight Viola-Jones detector algorithm with a Convolutional Neural Network (CNN), MobileNetV3-SSDLite, trained for the pest detection task. On two datasets that differentiate for the distance between the camera sensor and the pest targets, the CNN generalizes better than the other method and achieves a detection accuracy between 83% and 72%. Thanks to the GAP9's CNN accelerator, the CNN inference task takes only 147 ms to process a 320$\times$240 image. Compared to the GAP8 MCU, which only relies on general-purpose cores for processing, we achieved 9.5$\times$ faster inference speed. When running on a 1000 mAh battery at 3.7 V, the estimated lifetime is approximately 199 days, processing an image every 30 seconds. Our study demonstrates that the novel heterogeneous MCU can perform end-to-end CNN inference with an energy consumption of just 4.85 mJ, matching the efficiency of the simpler Viola-Jones algorithm and offering power consumption up to 15$\times$ lower than previous methods. Code at: https://github.com/Bomps4/TAFE_Pest_Detection
Training on the Fly: On-device Self-supervised Learning aboard Nano-drones within 20 mW
Aug 06, 2024



Miniaturized cyber-physical systems (CPSes) powered by tiny machine learning (TinyML), such as nano-drones, are becoming an increasingly attractive technology. Their small form factor (i.e., ~10cm diameter) ensures vast applicability, ranging from the exploration of narrow disaster scenarios to safe human-robot interaction. Simple electronics make these CPSes inexpensive, but strongly limit the computational, memory, and sensing resources available on board. In real-world applications, these limitations are further exacerbated by domain shift. This fundamental machine learning problem implies that model perception performance drops when moving from the training domain to a different deployment one. To cope with and mitigate this general problem, we present a novel on-device fine-tuning approach that relies only on the limited ultra-low power resources available aboard nano-drones. Then, to overcome the lack of ground-truth training labels aboard our CPS, we also employ a self-supervised method based on ego-motion consistency. Albeit our work builds on top of a specific real-world vision-based human pose estimation task, it is widely applicable for many embedded TinyML use cases. Our 512-image on-device training procedure is fully deployed aboard an ultra-low power GWT GAP9 System-on-Chip and requires only 1MB of memory while consuming as low as 19mW or running in just 510ms (at 38mW). Finally, we demonstrate the benefits of our on-device learning approach by field-testing our closed-loop CPS, showing a reduction in horizontal position error of up to 26% vs. a non-fine-tuned state-of-the-art baseline. In the most challenging never-seen-before environment, our on-device learning procedure makes the difference between succeeding or failing the mission.
Distilling Tiny and Ultra-fast Deep Neural Networks for Autonomous Navigation on Nano-UAVs
Jul 17, 2024Nano-sized unmanned aerial vehicles (UAVs) are ideal candidates for flying Internet-of-Things smart sensors to collect information in narrow spaces. This requires ultra-fast navigation under very tight memory/computation constraints. The PULP-Dronet convolutional neural network (CNN) enables autonomous navigation running aboard a nano-UAV at 19 frame/s, at the cost of a large memory footprint of 320 kB -- and with drone control in complex scenarios hindered by the disjoint training of collision avoidance and steering capabilities. In this work, we distill a novel family of CNNs with better capabilities than PULP-Dronet, but memory footprint reduced by up to 168x (down to 2.9 kB), achieving an inference rate of up to 139 frame/s; we collect a new open-source unified collision/steering 66 k images dataset for more robust navigation; and we perform a thorough in-field analysis of both PULP-Dronet and our tiny CNNs running on a commercially available nano-UAV. Our tiniest CNN, called Tiny-PULP-Dronet v3, navigates with a 100% success rate a challenging and never-seen-before path, composed of a narrow obstacle-populated corridor and a 180{\deg} turn, at a maximum target speed of 0.5 m/s. In the same scenario, the SoA PULP-Dronet consistently fails despite having 168x more parameters.
Tiny-PULP-Dronets: Squeezing Neural Networks for Faster and Lighter Inference on Multi-Tasking Autonomous Nano-Drones
Jul 02, 2024



Pocket-sized autonomous nano-drones can revolutionize many robotic use cases, such as visual inspection in narrow, constrained spaces, and ensure safer human-robot interaction due to their tiny form factor and weight -- i.e., tens of grams. This compelling vision is challenged by the high level of intelligence needed aboard, which clashes against the limited computational and storage resources available on PULP (parallel-ultra-low-power) MCU class navigation and mission controllers that can be hosted aboard. This work moves from PULP-Dronet, a State-of-the-Art convolutional neural network for autonomous navigation on nano-drones. We introduce Tiny-PULP-Dronet: a novel methodology to squeeze by more than one order of magnitude model size (50x fewer parameters), and number of operations (27x less multiply-and-accumulate) required to run inference with similar flight performance as PULP-Dronet. This massive reduction paves the way towards affordable multi-tasking on nano-drones, a fundamental requirement for achieving high-level intelligence.