 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSixth-Sense: Self-Supervised Learning of Spatial Awareness of Humans from a Planar Lidar
Feb 28, 2025Localizing humans is a key prerequisite for any service robot operating in proximity to people. In these scenarios, robots rely on a multitude of state-of-the-art detectors usually designed to operate with RGB-D cameras or expensive 3D LiDARs. However, most commercially available service robots are equipped with cameras with a narrow field of view, making them blind when a user is approaching from other directions, or inexpensive 1D LiDARs whose readings are difficult to interpret. To address these limitations, we propose a self-supervised approach to detect humans and estimate their 2D pose from 1D LiDAR data, using detections from an RGB-D camera as a supervision source. Our approach aims to provide service robots with spatial awareness of nearby humans. After training on 70 minutes of data autonomously collected in two environments, our model is capable of detecting humans omnidirectionally from 1D LiDAR data in a novel environment, with 71% precision and 80% recall, while retaining an average absolute error of 13 cm in distance and 44{\deg} in orientation.
Multi-LED Classification as Pretext For Robot Heading Estimation
Oct 06, 2024We propose a self-supervised approach for visual robot detection and heading estimation by learning to estimate the states (OFF or ON) of four independent robot-mounted LEDs. Experimental results show a median image-space position error of 14 px and relative heading MAE of 17 degrees, versus a supervised upperbound scoring 10 px and 8 degrees, respectively.
Learning to Estimate the Pose of a Peer Robot in a Camera Image by Predicting the States of its LEDs
Jul 15, 2024



We consider the problem of training a fully convolutional network to estimate the relative 6D pose of a robot given a camera image, when the robot is equipped with independent controllable LEDs placed in different parts of its body. The training data is composed by few (or zero) images labeled with a ground truth relative pose and many images labeled only with the true state (\textsc{on} or \textsc{off}) of each of the peer LEDs. The former data is expensive to acquire, requiring external infrastructure for tracking the two robots; the latter is cheap as it can be acquired by two unsupervised robots moving randomly and toggling their LEDs while sharing the true LED states via radio. Training with the latter dataset on estimating the LEDs' state of the peer robot (\emph{pretext task}) promotes learning the relative localization task (\emph{end task}). Experiments on real-world data acquired by two autonomous wheeled robots show that a model trained only on the pretext task successfully learns to localize a peer robot on the image plane; fine-tuning such model on the end task with few labeled images yields statistically significant improvements in 6D relative pose estimation with respect to baselines that do not use pretext-task pre-training, and alternative approaches. Estimating the state of multiple independent LEDs promotes learning to estimate relative heading. The approach works even when a large fraction of training images do not include the peer robot and generalizes well to unseen environments.
Self-Supervised Learning of Visual Robot Localization Using LED State Prediction as a Pretext Task
Feb 15, 2024



We propose a novel self-supervised approach for learning to visually localize robots equipped with controllable LEDs. We rely on a few training samples labeled with position ground truth and many training samples in which only the LED state is known, whose collection is cheap. We show that using LED state prediction as a pretext task significantly helps to learn the visual localization end task. The resulting model does not require knowledge of LED states during inference. We instantiate the approach to visual relative localization of nano-quadrotors: experimental results show that using our pretext task significantly improves localization accuracy (from 68.3% to 76.2%) and outperforms alternative strategies, such as a supervised baseline, model pre-training, and an autoencoding pretext task. We deploy our model aboard a 27-g Crazyflie nano-drone, running at 21 fps, in a position-tracking task of a peer nano-drone. Our approach, relying on position labels for only 300 images, yields a mean tracking error of 4.2 cm versus 11.9 cm of a supervised baseline model trained without our pretext task. Videos and code of the proposed approach are available at https://github.com/idsia-robotics/leds-as-pretext
Visual Servoing with Geometrically Interpretable Neural Perception
Oct 19, 2022
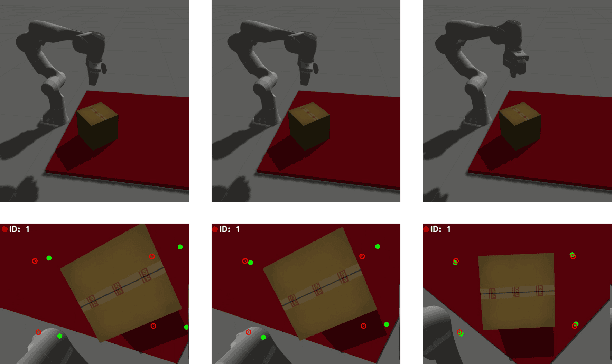
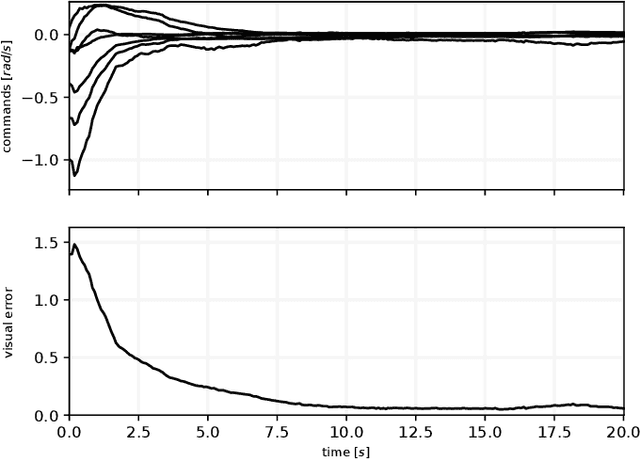
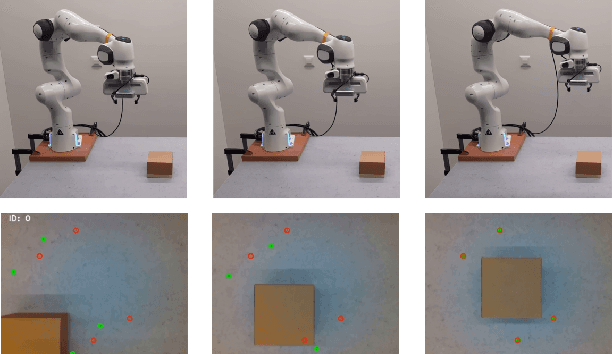
An increasing number of nonspecialist robotic users demand easy-to-use machines. In the context of visual servoing, the removal of explicit image processing is becoming a trend, allowing an easy application of this technique. This work presents a deep learning approach for solving the perception problem within the visual servoing scheme. An artificial neural network is trained using the supervision coming from the knowledge of the controller and the visual features motion model. In this way, it is possible to give a geometrical interpretation to the estimated visual features, which can be used in the analytical law of the visual servoing. The approach keeps perception and control decoupled, conferring flexibility and interpretability on the whole framework. Simulated and real experiments with a robotic manipulator validate our approach.
Vision-State Fusion: Improving Deep Neural Networks for Autonomous Robotics
Jun 13, 2022
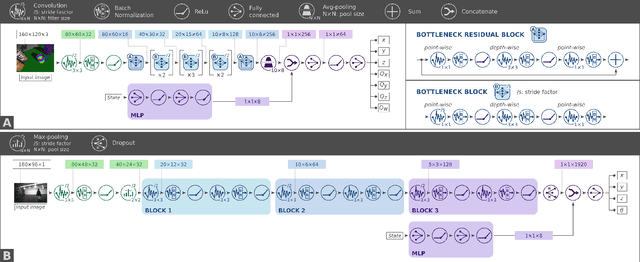
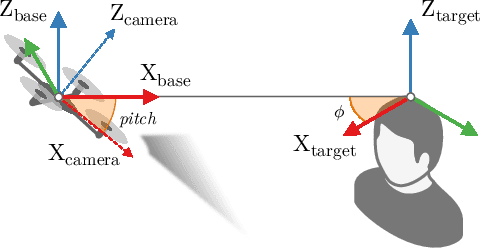
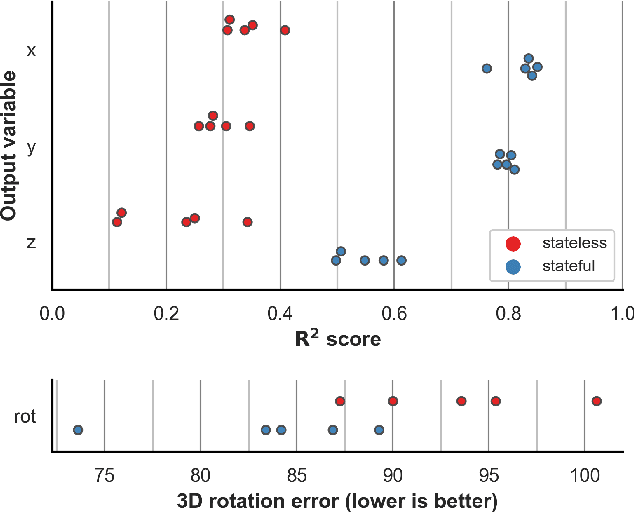
Vision-based perception tasks fulfill a paramount role in robotics, facilitating solutions to many challenging scenarios, such as acrobatics maneuvers of autonomous unmanned aerial vehicles (UAVs) and robot-assisted high precision surgery. Most control-oriented and egocentric perception problems are commonly solved by taking advantage of the robot state estimation as an auxiliary input, particularly when artificial intelligence comes into the picture. In this work, we propose to apply a similar approach for the first time - to the best of our knowledge - to allocentric perception tasks, where the target variables refer to an external subject. We prove how our general and intuitive methodology improves the regression performance of deep convolutional neural networks (CNNs) with ambiguous problems such as the allocentric 3D pose estimation. By analyzing three highly-different use cases, spanning from grasping with a robotic arm to following a human subject with a pocket-sized UAV, our results consistently improve the R2 metric up to +0.514 compared to their stateless baselines. Finally, we validate the in-field performance of a closed-loop autonomous pocket-sized UAV in the human pose estimation task. Our results show a significant reduction, i.e., 24% on average, on the mean absolute error of our stateful CNN.
Uncertainty-Aware Self-Supervised Learning of Spatial Perception Tasks
Mar 22, 2021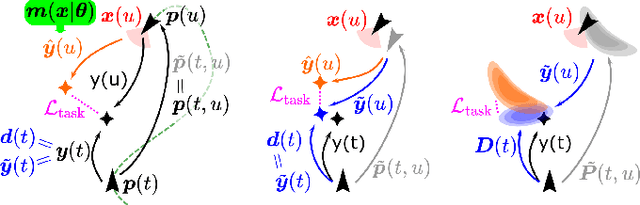
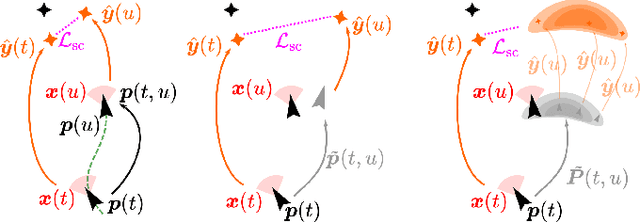
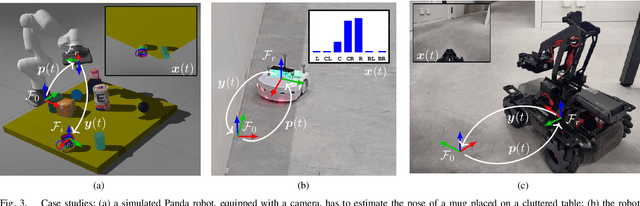

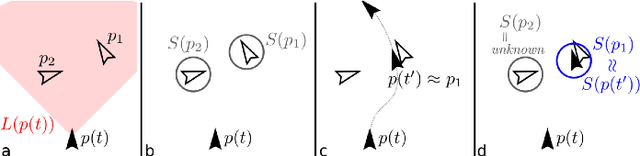
We propose a general self-supervised approach to learn neural models that solve spatial perception tasks, such as estimating the pose of an object relative to the robot, from onboard sensor readings. The model is learned from training episodes, by relying on: a continuous state estimate, possibly inaccurate and affected by odometry drift; and a detector, that sporadically provides supervision about the target pose. We demonstrate the general approach in three different concrete scenarios: a simulated robot arm that visually estimates the pose of an object of interest; a small differential drive robot using 7 infrared sensors to localize a nearby wall; an omnidirectional mobile robot that localizes itself in an environment from camera images. Quantitative results show that the approach works well in all three scenarios, and that explicitly accounting for uncertainty yields statistically significant performance improvements.
Learning Long-Range Perception Using Self-Supervision from Short-Range Sensors and Odometry
Jan 17, 2019
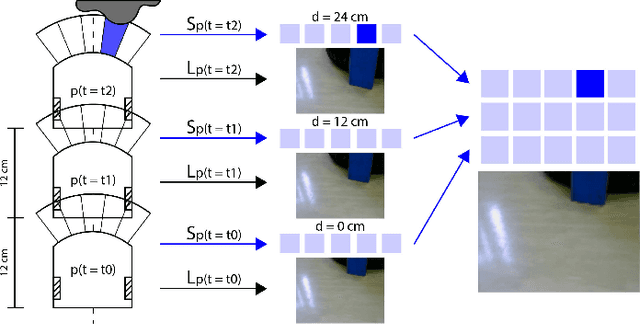
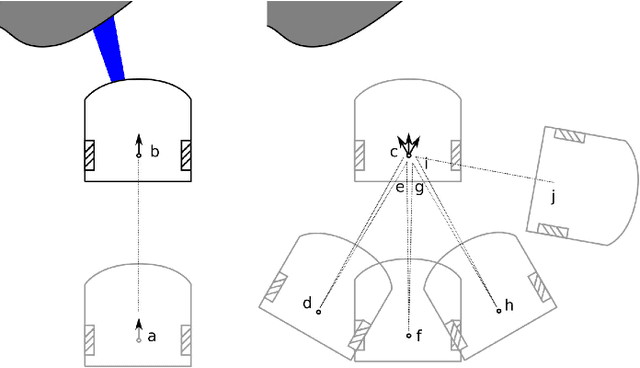
We introduce a general self-supervised approach to predict the future outputs of a short-range sensor (such as a proximity sensor) given the current outputs of a long-range sensor (such as a camera); we assume that the former is directly related to some piece of information to be perceived (such as the presence of an obstacle in a given position), whereas the latter is information-rich but hard to interpret directly. We instantiate and implement the approach on a small mobile robot to detect obstacles at various distances using the video stream of the robot's forward-pointing camera, by training a convolutional neural network on automatically-acquired datasets. We quantitatively evaluate the quality of the predictions on unseen scenarios, qualitatively evaluate robustness to different operating conditions, and demonstrate usage as the sole input of an obstacle-avoidance controller. We additionally instantiate the approach on a different simulated scenario with complementary characteristics, to exemplify the generality of our contribution.