 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiPhysio-HRC: Multimodal Physiological Signals Dataset for industrial Human-Robot Collaboration
Oct 01, 2025Human-robot collaboration (HRC) is a key focus of Industry 5.0, aiming to enhance worker productivity while ensuring well-being. The ability to perceive human psycho-physical states, such as stress and cognitive load, is crucial for adaptive and human-aware robotics. This paper introduces MultiPhysio-HRC, a multimodal dataset containing physiological, audio, and facial data collected during real-world HRC scenarios. The dataset includes electroencephalography (EEG), electrocardiography (ECG), electrodermal activity (EDA), respiration (RESP), electromyography (EMG), voice recordings, and facial action units. The dataset integrates controlled cognitive tasks, immersive virtual reality experiences, and industrial disassembly activities performed manually and with robotic assistance, to capture a holistic view of the participants' mental states. Rich ground truth annotations were obtained using validated psychological self-assessment questionnaires. Baseline models were evaluated for stress and cognitive load classification, demonstrating the dataset's potential for affective computing and human-aware robotics research. MultiPhysio-HRC is publicly available to support research in human-centered automation, workplace well-being, and intelligent robotic systems.
An Outlier Exposure Approach to Improve Visual Anomaly Detection Performance for Mobile Robots
Sep 20, 2022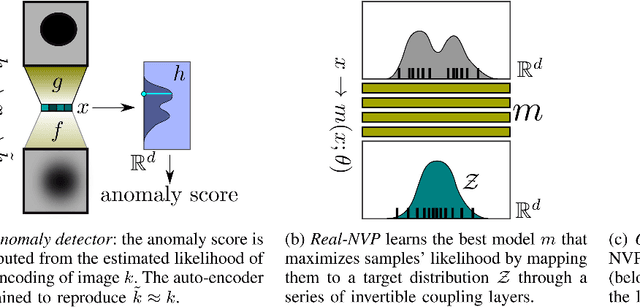


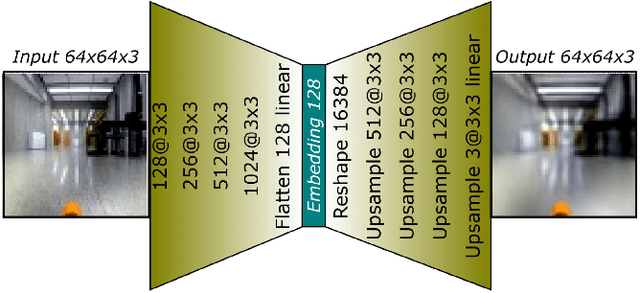
We consider the problem of building visual anomaly detection systems for mobile robots. Standard anomaly detection models are trained using large datasets composed only of non-anomalous data. However, in robotics applications, it is often the case that (potentially very few) examples of anomalies are available. We tackle the problem of exploiting these data to improve the performance of a Real-NVP anomaly detection model, by minimizing, jointly with the Real-NVP loss, an auxiliary outlier exposure margin loss. We perform quantitative experiments on a novel dataset (which we publish as supplementary material) designed for anomaly detection in an indoor patrolling scenario. On a disjoint test set, our approach outperforms alternatives and shows that exposing even a small number of anomalous frames yields significant performance improvements.
A New Constructive Heuristic driven by Machine Learning for the Traveling Salesman Problem
Aug 17, 2021
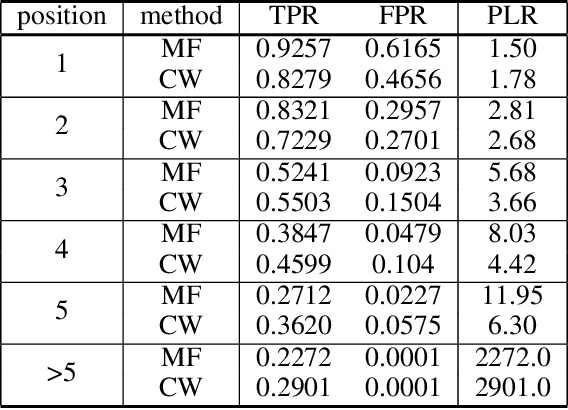

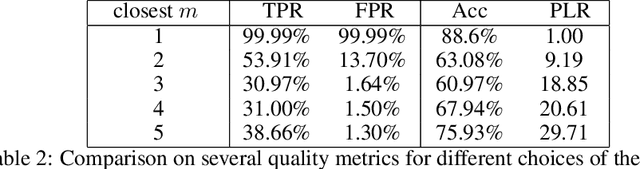
Recent systems applying Machine Learning (ML) to solve the Traveling Salesman Problem (TSP) exhibit issues when they try to scale up to real case scenarios with several hundred vertices. The use of Candidate Lists (CLs) has been brought up to cope with the issues. The procedure allows to restrict the search space during solution creation, consequently reducing the solver computational burden. So far, ML were engaged to create CLs and values on the edges of these CLs expressing ML preferences at solution insertion. Although promising, these systems do not clearly restrict what the ML learns and does to create solutions, bringing with them some generalization issues. Therefore, motivated by exploratory and statistical studies, in this work we instead use a machine learning model to confirm the addition in the solution just for high probable edges. CLs of the high probable edge are employed as input, and the ML is in charge of distinguishing cases where such edges are in the optimal solution from those where they are not. . This strategy enables a better generalization and creates an efficient balance between machine learning and searching techniques. Our ML-Constructive heuristic is trained on small instances. Then, it is able to produce solutions, without losing quality, to large problems as well. We compare our results with classic constructive heuristics, showing good performances for TSPLIB instances up to 1748 cities. Although our heuristic exhibits an expensive constant time operation, we proved that the computational complexity in worst-case scenario, for the solution construction after training, is $O(n^2 \log n^2)$, being $n$ the number of vertices in the TSP instance.
Machine Learning Constructives and Local Searches for the Travelling Salesman Problem
Aug 02, 2021

The ML-Constructive heuristic is a recently presented method and the first hybrid method capable of scaling up to real scale traveling salesman problems. It combines machine learning techniques and classic optimization techniques. In this paper we present improvements to the computational weight of the original deep learning model. In addition, as simpler models reduce the execution time, the possibility of adding a local-search phase is explored to further improve performance. Experimental results corroborate the quality of the proposed improvements.
Uncertainty-Aware Self-Supervised Learning of Spatial Perception Tasks
Mar 22, 2021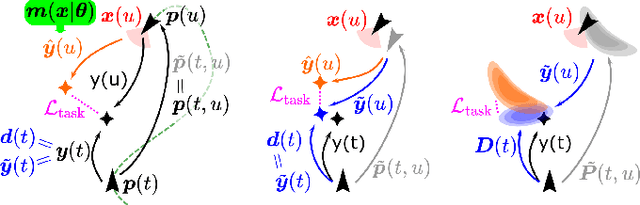
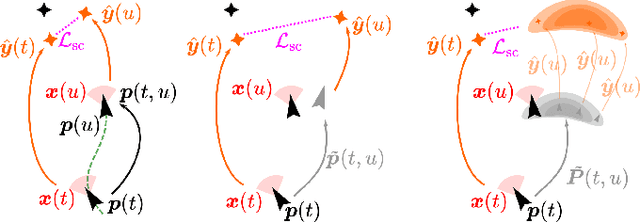
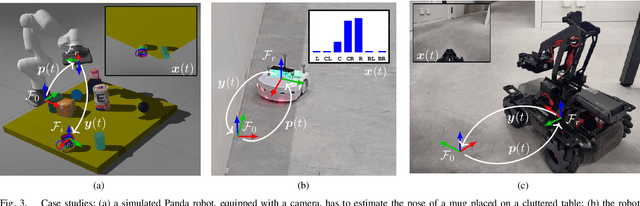

We propose a general self-supervised approach to learn neural models that solve spatial perception tasks, such as estimating the pose of an object relative to the robot, from onboard sensor readings. The model is learned from training episodes, by relying on: a continuous state estimate, possibly inaccurate and affected by odometry drift; and a detector, that sporadically provides supervision about the target pose. We demonstrate the general approach in three different concrete scenarios: a simulated robot arm that visually estimates the pose of an object of interest; a small differential drive robot using 7 infrared sensors to localize a nearby wall; an omnidirectional mobile robot that localizes itself in an environment from camera images. Quantitative results show that the approach works well in all three scenarios, and that explicitly accounting for uncertainty yields statistically significant performance improvements.
Fully Onboard AI-powered Human-Drone Pose Estimation on Ultra-low Power Autonomous Flying Nano-UAVs
Mar 19, 2021
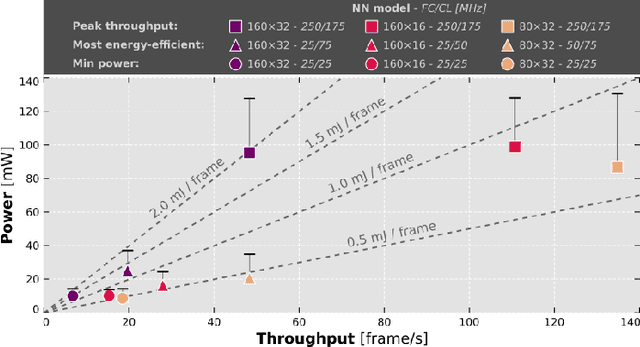
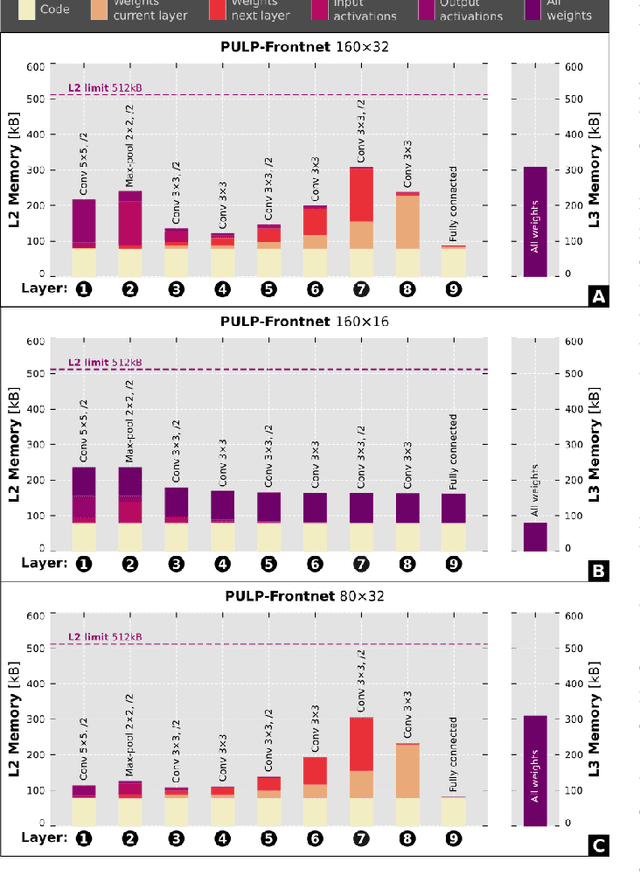
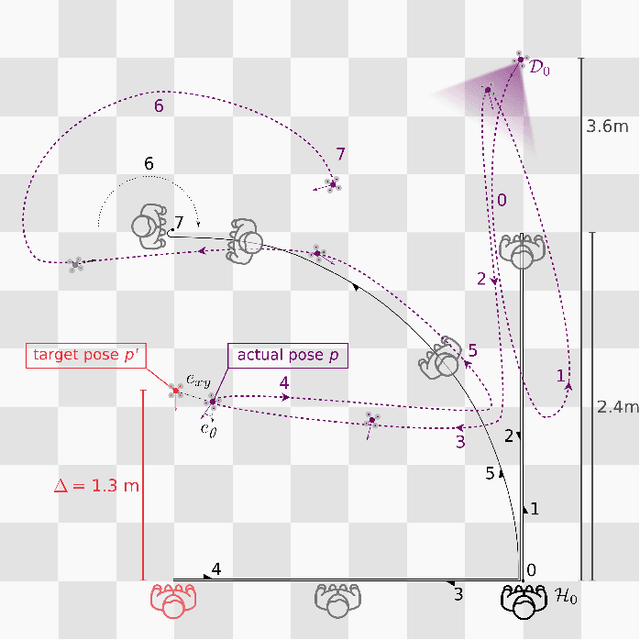
Artificial intelligence-powered pocket-sized air robots have the potential to revolutionize the Internet-of-Things ecosystem, acting as autonomous, unobtrusive, and ubiquitous smart sensors. With a few cm$^{2}$ form-factor, nano-sized unmanned aerial vehicles (UAVs) are the natural befit for indoor human-drone interaction missions, as the pose estimation task we address in this work. However, this scenario is challenged by the nano-UAVs' limited payload and computational power that severely relegates the onboard brain to the sub-100 mW microcontroller unit-class. Our work stands at the intersection of the novel parallel ultra-low-power (PULP) architectural paradigm and our general development methodology for deep neural network (DNN) visual pipelines, i.e., covering from perception to control. Addressing the DNN model design, from training and dataset augmentation to 8-bit quantization and deployment, we demonstrate how a PULP-based processor, aboard a nano-UAV, is sufficient for the real-time execution (up to 135 frame/s) of our novel DNN, called PULP-Frontnet. We showcase how, scaling our model's memory and computational requirement, we can significantly improve the onboard inference (top energy efficiency of 0.43 mJ/frame) with no compromise in the quality-of-result vs. a resource-unconstrained baseline (i.e., full-precision DNN). Field experiments demonstrate a closed-loop top-notch autonomous navigation capability, with a heavily resource-constrained 27-gram Crazyflie 2.1 nano-quadrotor. Compared against the control performance achieved using an ideal sensing setup, onboard relative pose inference yields excellent drone behavior in terms of median absolute errors, such as positional (onboard: 41 cm, ideal: 26 cm) and angular (onboard: 3.7$^{\circ}$, ideal: 4.1$^{\circ}$).
Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition
Mar 01, 2010Good old on-line back-propagation for plain multi-layer perceptrons yields a very low 0.35% error rate on the famous MNIST handwritten digits benchmark. All we need to achieve this best result so far are many hidden layers, many neurons per layer, numerous deformed training images, and graphics cards to greatly speed up learning.
* 14 pages, 2 figures, 4 listings