 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Visual Anomaly Detection for Mobile Robots
Sep 22, 2022
We consider the task of detecting anomalies for autonomous mobile robots based on vision. We categorize relevant types of visual anomalies and discuss how they can be detected by unsupervised deep learning methods. We propose a novel dataset built specifically for this task, on which we test a state-of-the-art approach; we finally discuss deployment in a real scenario.
An Outlier Exposure Approach to Improve Visual Anomaly Detection Performance for Mobile Robots
Sep 20, 2022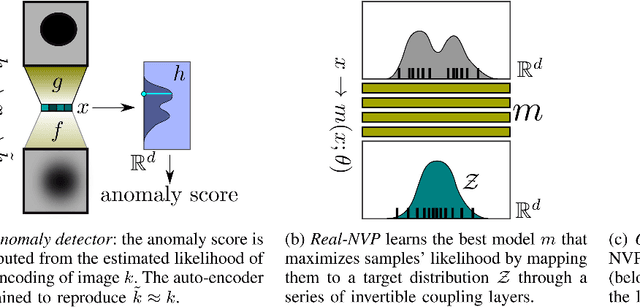


We consider the problem of building visual anomaly detection systems for mobile robots. Standard anomaly detection models are trained using large datasets composed only of non-anomalous data. However, in robotics applications, it is often the case that (potentially very few) examples of anomalies are available. We tackle the problem of exploiting these data to improve the performance of a Real-NVP anomaly detection model, by minimizing, jointly with the Real-NVP loss, an auxiliary outlier exposure margin loss. We perform quantitative experiments on a novel dataset (which we publish as supplementary material) designed for anomaly detection in an indoor patrolling scenario. On a disjoint test set, our approach outperforms alternatives and shows that exposing even a small number of anomalous frames yields significant performance improvements.
Sensing Anomalies as Potential Hazards: Datasets and Benchmarks
Oct 27, 2021

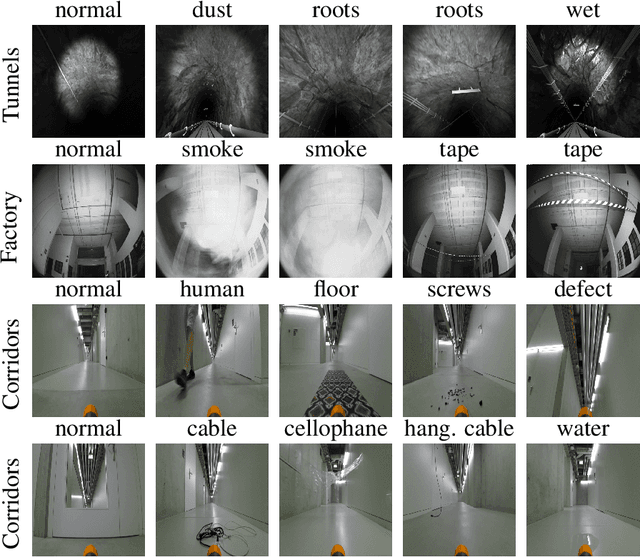
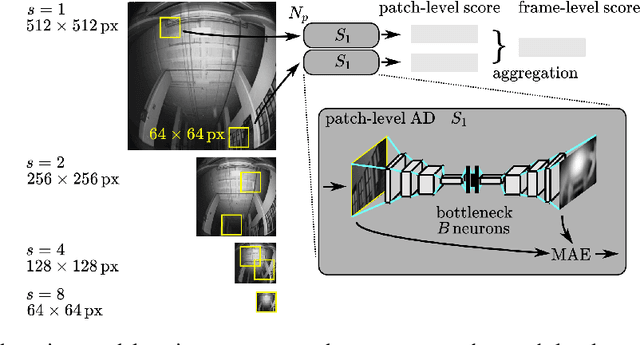
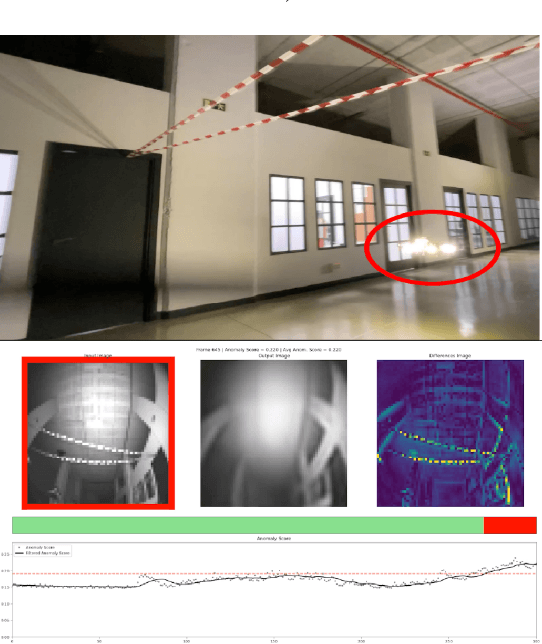
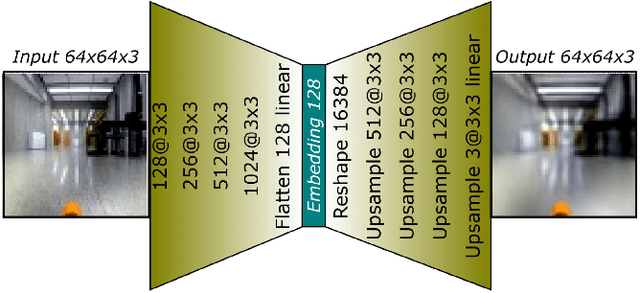
We consider the problem of detecting, in the visual sensing data stream of an autonomous mobile robot, semantic patterns that are unusual (i.e., anomalous) with respect to the robot's previous experience in similar environments. These anomalies might indicate unforeseen hazards and, in scenarios where failure is costly, can be used to trigger an avoidance behavior. We contribute three novel image-based datasets acquired in robot exploration scenarios, comprising a total of more than 200k labeled frames, spanning various types of anomalies. On these datasets, we study the performance of an anomaly detection approach based on autoencoders operating at different scales.
Training Lightweight CNNs for Human-Nanodrone Proximity Interaction from Small Datasets using Background Randomization
Oct 27, 2021


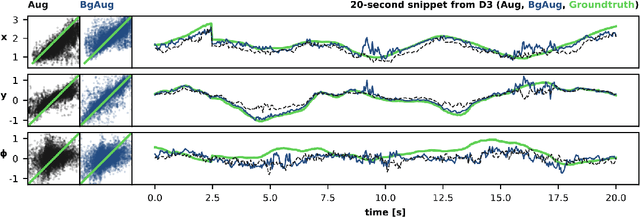
We consider the task of visually estimating the pose of a human from images acquired by a nearby nano-drone; in this context, we propose a data augmentation approach based on synthetic background substitution to learn a lightweight CNN model from a small real-world training set. Experimental results on data from two different labs proves that the approach improves generalization to unseen environments.
Semantic Segmentation on Swiss3DCities: A Benchmark Study on Aerial Photogrammetric 3D Pointcloud Dataset
Dec 23, 2020
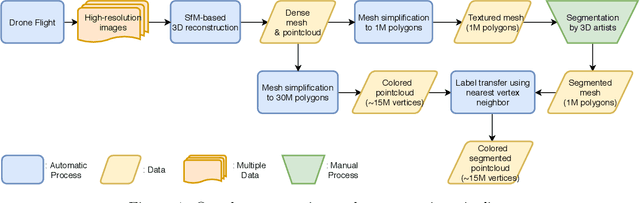
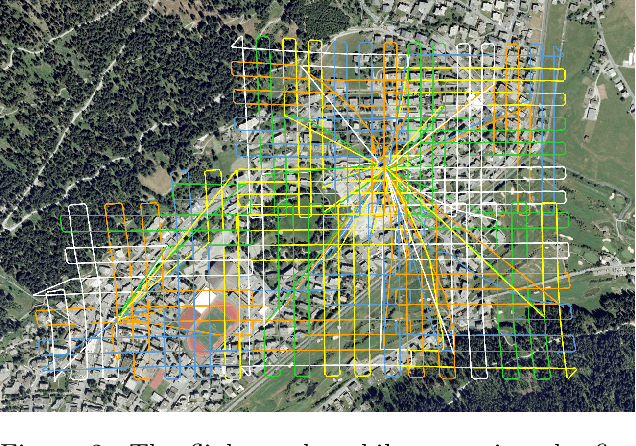

We introduce a new outdoor urban 3D pointcloud dataset, covering a total area of 2.7 $km^2$, sampled from three Swiss cities with different characteristics. The dataset is manually annotated for semantic segmentation with per-point labels, and is built using photogrammetry from images acquired by multirotors equipped with high-resolution cameras. In contrast to datasets acquired with ground LiDAR sensors, the resulting point clouds are uniformly dense and complete, and are useful to disparate applications, including autonomous driving, gaming and smart city planning. As a benchmark, we report quantitative results of PointNet++, an established point-based deep 3D semantic segmentation model; on this model, we additionally study the impact of using different cities for model generalization.
Vision-based Control of a Quadrotor in User Proximity: Mediated vs End-to-End Learning Approaches
Feb 25, 2019


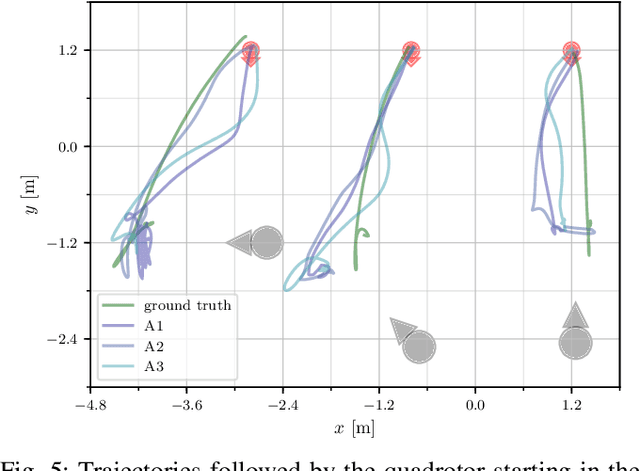
We consider the task of controlling a quadrotor to hover in front of a freely moving user, using input data from an onboard camera. On this specific task we compare two widespread learning paradigms: a mediated approach, which learns an high-level state from the input and then uses it for deriving control signals; and an end-to-end approach, which skips high-level state estimation altogether. We show that despite their fundamental difference, both approaches yield equivalent performance on this task. We finally qualitatively analyze the behavior of a quadrotor implementing such approaches.