 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Visual Anomaly Detection for Mobile Robots
Sep 22, 2022
We consider the task of detecting anomalies for autonomous mobile robots based on vision. We categorize relevant types of visual anomalies and discuss how they can be detected by unsupervised deep learning methods. We propose a novel dataset built specifically for this task, on which we test a state-of-the-art approach; we finally discuss deployment in a real scenario.
Sensing Anomalies as Potential Hazards: Datasets and Benchmarks
Oct 27, 2021

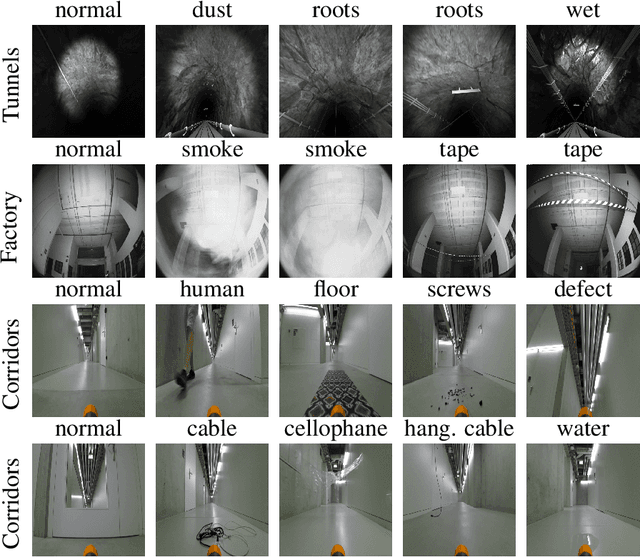
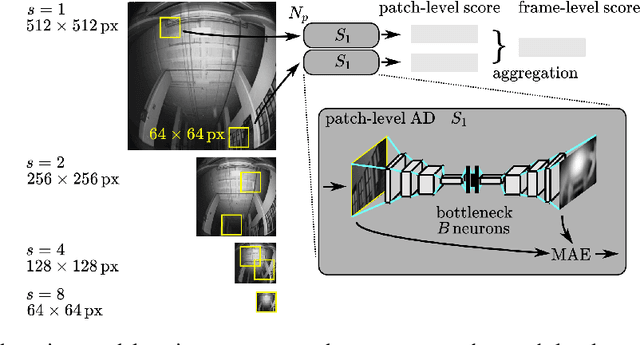
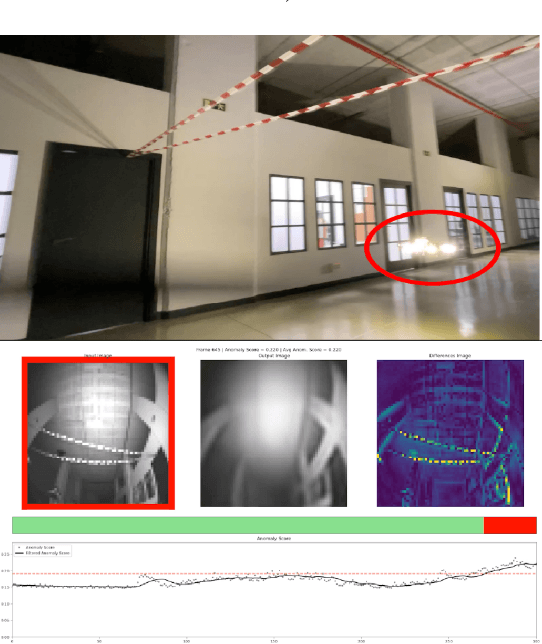
We consider the problem of detecting, in the visual sensing data stream of an autonomous mobile robot, semantic patterns that are unusual (i.e., anomalous) with respect to the robot's previous experience in similar environments. These anomalies might indicate unforeseen hazards and, in scenarios where failure is costly, can be used to trigger an avoidance behavior. We contribute three novel image-based datasets acquired in robot exploration scenarios, comprising a total of more than 200k labeled frames, spanning various types of anomalies. On these datasets, we study the performance of an anomaly detection approach based on autoencoders operating at different scales.
Training Lightweight CNNs for Human-Nanodrone Proximity Interaction from Small Datasets using Background Randomization
Oct 27, 2021


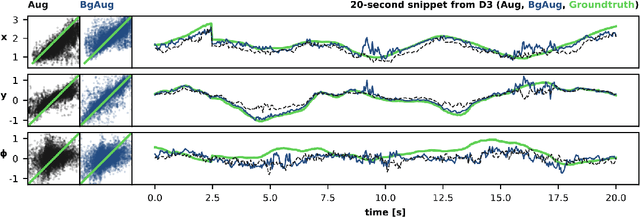
We consider the task of visually estimating the pose of a human from images acquired by a nearby nano-drone; in this context, we propose a data augmentation approach based on synthetic background substitution to learn a lightweight CNN model from a small real-world training set. Experimental results on data from two different labs proves that the approach improves generalization to unseen environments.
Vision-based Control of a Quadrotor in User Proximity: Mediated vs End-to-End Learning Approaches
Feb 25, 2019


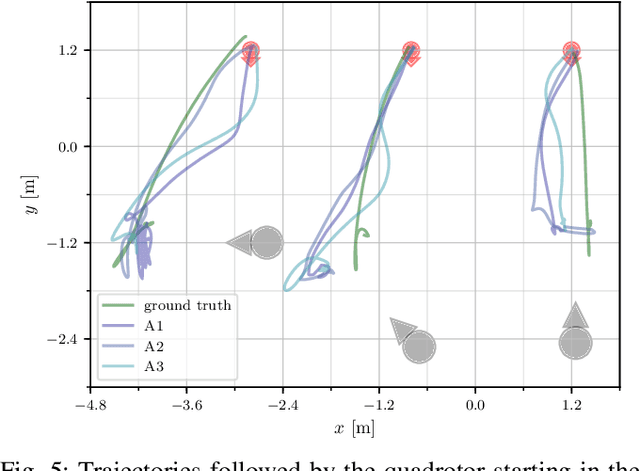
We consider the task of controlling a quadrotor to hover in front of a freely moving user, using input data from an onboard camera. On this specific task we compare two widespread learning paradigms: a mediated approach, which learns an high-level state from the input and then uses it for deriving control signals; and an end-to-end approach, which skips high-level state estimation altogether. We show that despite their fundamental difference, both approaches yield equivalent performance on this task. We finally qualitatively analyze the behavior of a quadrotor implementing such approaches.
Learning Ground Traversability from Simulations
Feb 18, 2019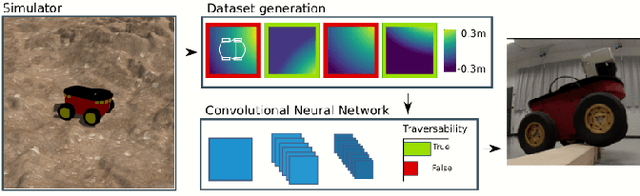

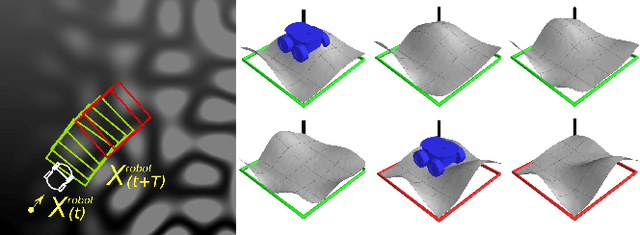

Mobile ground robots operating on unstructured terrain must predict which areas of the environment they are able to pass in order to plan feasible paths. We address traversability estimation as a heightmap classification problem: we build a convolutional neural network that, given an image representing the heightmap of a terrain patch, predicts whether the robot will be able to traverse such patch from left to right. The classifier is trained for a specific robot model (wheeled, tracked, legged, snake-like) using simulation data on procedurally generated training terrains; the trained classifier can be applied to unseen large heightmaps to yield oriented traversability maps, and then plan traversable paths. We extensively evaluate the approach in simulation on six real-world elevation datasets, and run a real-robot validation in one indoor and one outdoor environment.
* Webpage: http://romarcg.xyz/traversability_estimation/
Learning Long-Range Perception Using Self-Supervision from Short-Range Sensors and Odometry
Jan 17, 2019
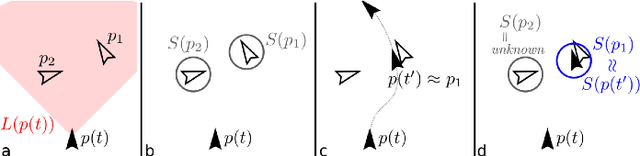
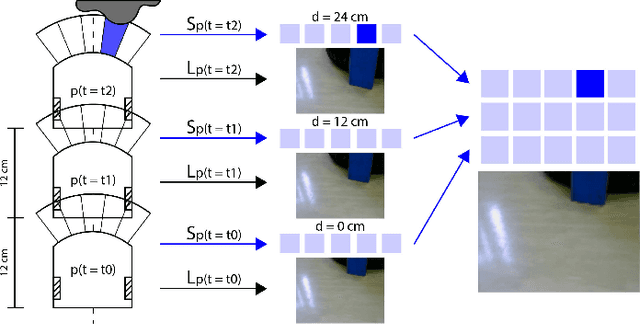
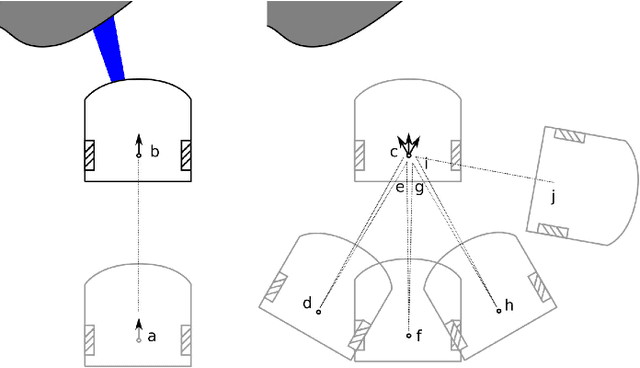
We introduce a general self-supervised approach to predict the future outputs of a short-range sensor (such as a proximity sensor) given the current outputs of a long-range sensor (such as a camera); we assume that the former is directly related to some piece of information to be perceived (such as the presence of an obstacle in a given position), whereas the latter is information-rich but hard to interpret directly. We instantiate and implement the approach on a small mobile robot to detect obstacles at various distances using the video stream of the robot's forward-pointing camera, by training a convolutional neural network on automatically-acquired datasets. We quantitatively evaluate the quality of the predictions on unseen scenarios, qualitatively evaluate robustness to different operating conditions, and demonstrate usage as the sole input of an obstacle-avoidance controller. We additionally instantiate the approach on a different simulated scenario with complementary characteristics, to exemplify the generality of our contribution.
Assessment of algorithms for mitosis detection in breast cancer histopathology images
Nov 21, 2014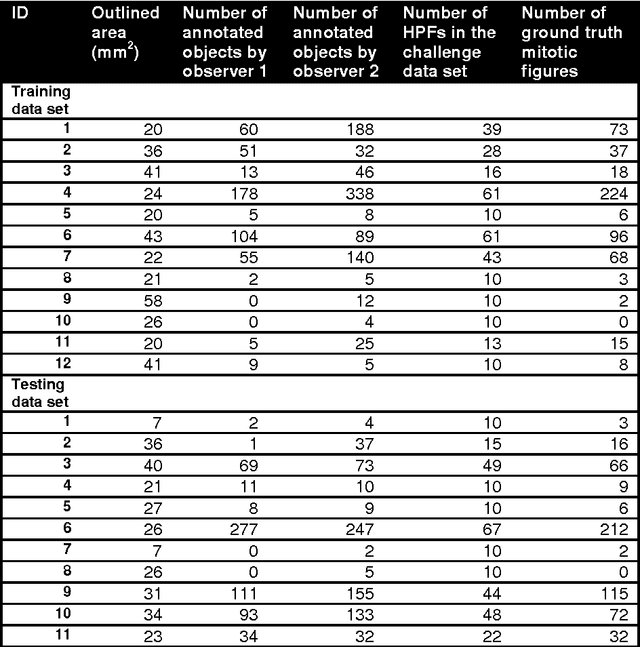

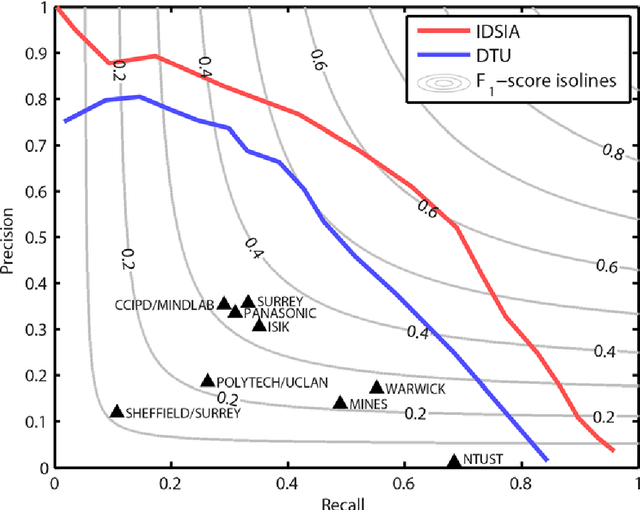
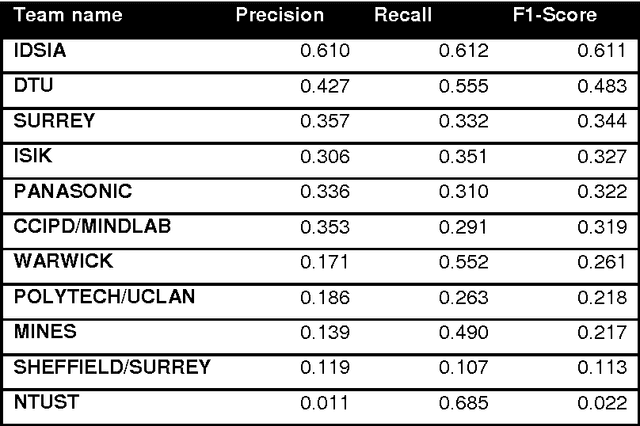
The proliferative activity of breast tumors, which is routinely estimated by counting of mitotic figures in hematoxylin and eosin stained histology sections, is considered to be one of the most important prognostic markers. However, mitosis counting is laborious, subjective and may suffer from low inter-observer agreement. With the wider acceptance of whole slide images in pathology labs, automatic image analysis has been proposed as a potential solution for these issues. In this paper, the results from the Assessment of Mitosis Detection Algorithms 2013 (AMIDA13) challenge are described. The challenge was based on a data set consisting of 12 training and 11 testing subjects, with more than one thousand annotated mitotic figures by multiple observers. Short descriptions and results from the evaluation of eleven methods are presented. The top performing method has an error rate that is comparable to the inter-observer agreement among pathologists.
Strategic Control of Proximity Relationships in Heterogeneous Search and Rescue Teams
Dec 17, 2013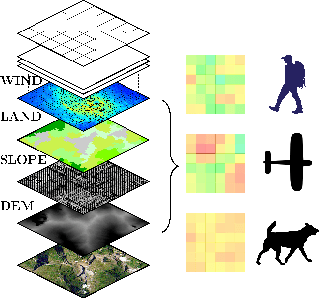
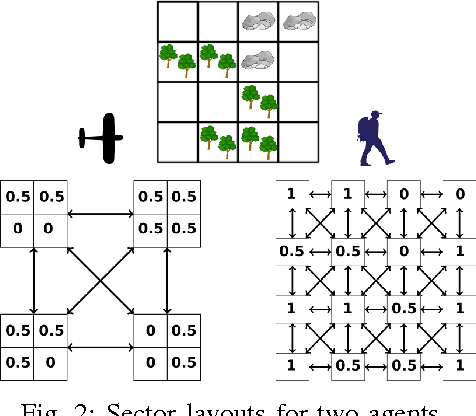
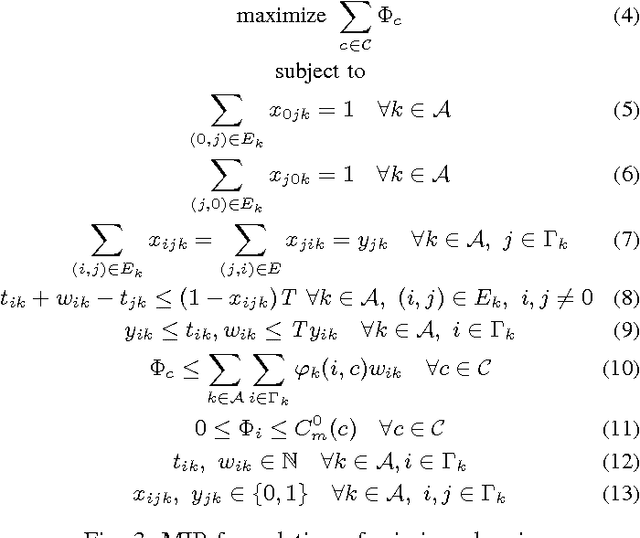
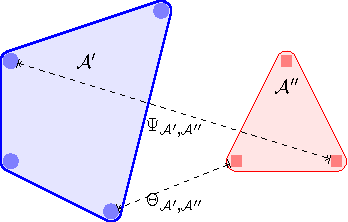
In the context of search and rescue, we consider the problem of mission planning for heterogeneous teams that can include human, robotic, and animal agents. The problem is tackled using a mixed integer mathematical programming formulation that jointly determines the path and the activity scheduling of each agent in the team. Based on the mathematical formulation, we propose the use of soft constraints and penalties that allow the flexible strategic control of spatio-temporal relations among the search trajectories of the agents. In this way, we can enable the mission planner to obtain solutions that maximize the area coverage and, at the same time, control the spatial proximity among the agents (e.g., to minimize mutual task interference, or to promote local cooperation and data sharing). Through simulation experiments, we show the application of the strategic framework considering a number of scenarios of interest for real-world search and rescue missions.
Fast Image Scanning with Deep Max-Pooling Convolutional Neural Networks
Feb 07, 2013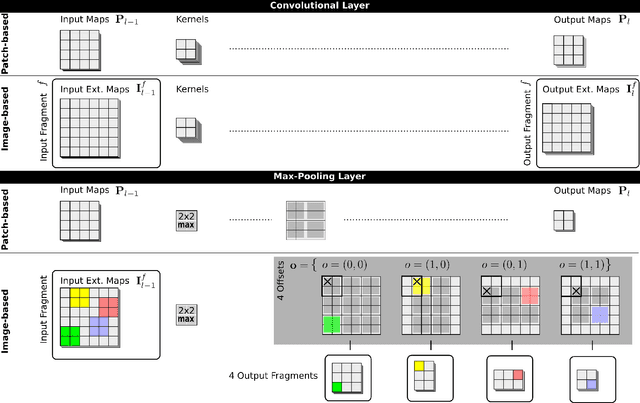


Deep Neural Networks now excel at image classification, detection and segmentation. When used to scan images by means of a sliding window, however, their high computational complexity can bring even the most powerful hardware to its knees. We show how dynamic programming can speedup the process by orders of magnitude, even when max-pooling layers are present.
* 11 pages, 2 figures, 3 tables, 21 references, submitted to ICIP 2013
Handwritten Digit Recognition with a Committee of Deep Neural Nets on GPUs
Mar 23, 2011
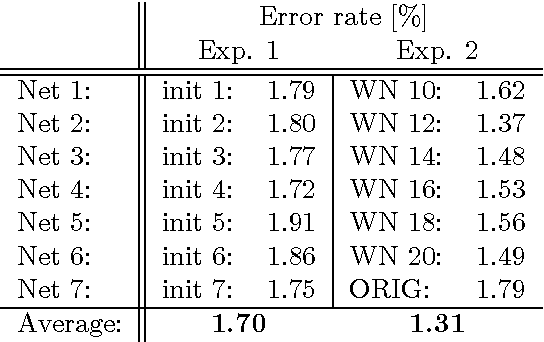
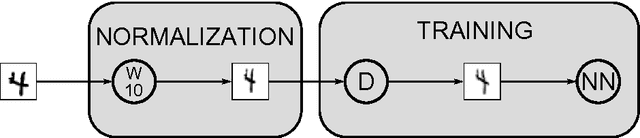
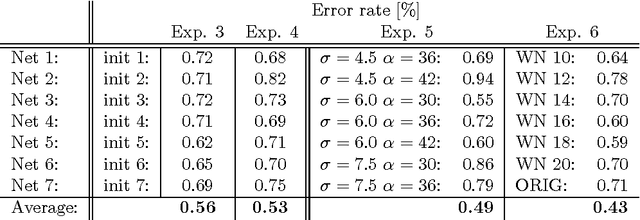
The competitive MNIST handwritten digit recognition benchmark has a long history of broken records since 1998. The most recent substantial improvement by others dates back 7 years (error rate 0.4%) . Recently we were able to significantly improve this result, using graphics cards to greatly speed up training of simple but deep MLPs, which achieved 0.35%, outperforming all the previous more complex methods. Here we report another substantial improvement: 0.31% obtained using a committee of MLPs.