 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of algorithms for mitosis detection in breast cancer histopathology images
Nov 21, 2014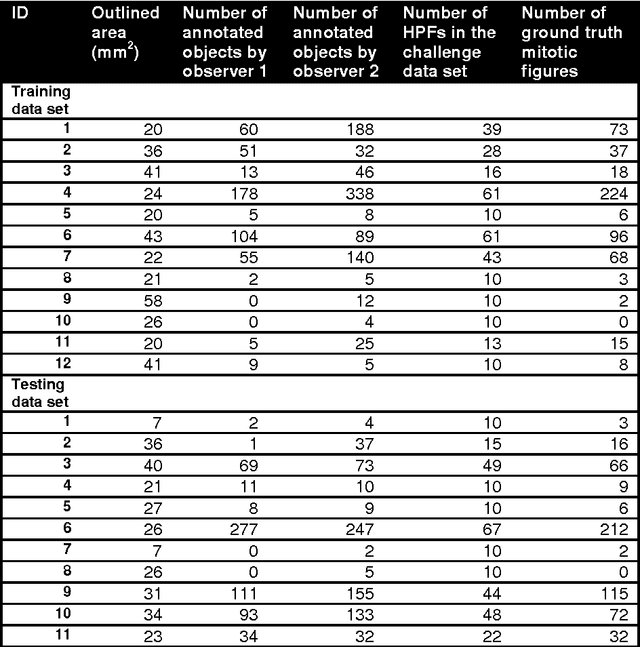

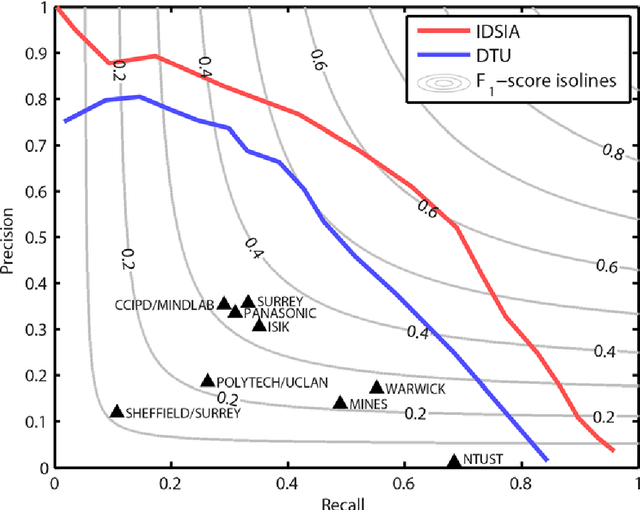
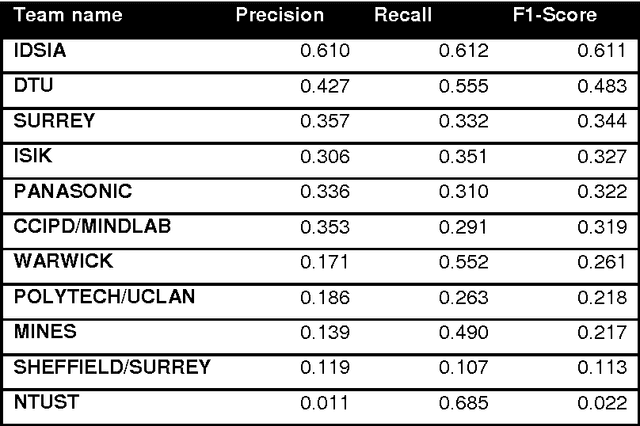
The proliferative activity of breast tumors, which is routinely estimated by counting of mitotic figures in hematoxylin and eosin stained histology sections, is considered to be one of the most important prognostic markers. However, mitosis counting is laborious, subjective and may suffer from low inter-observer agreement. With the wider acceptance of whole slide images in pathology labs, automatic image analysis has been proposed as a potential solution for these issues. In this paper, the results from the Assessment of Mitosis Detection Algorithms 2013 (AMIDA13) challenge are described. The challenge was based on a data set consisting of 12 training and 11 testing subjects, with more than one thousand annotated mitotic figures by multiple observers. Short descriptions and results from the evaluation of eleven methods are presented. The top performing method has an error rate that is comparable to the inter-observer agreement among pathologists.
Fast Image Scanning with Deep Max-Pooling Convolutional Neural Networks
Feb 07, 2013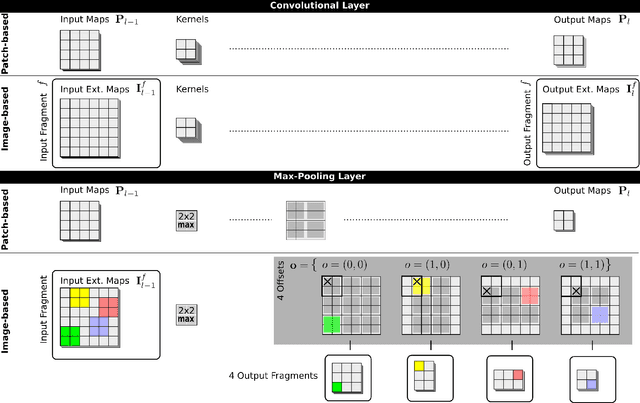


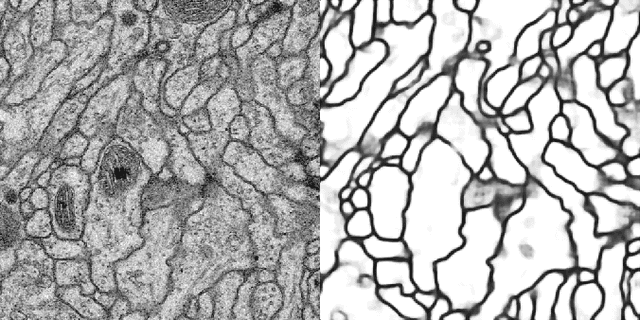
Deep Neural Networks now excel at image classification, detection and segmentation. When used to scan images by means of a sliding window, however, their high computational complexity can bring even the most powerful hardware to its knees. We show how dynamic programming can speedup the process by orders of magnitude, even when max-pooling layers are present.
* 11 pages, 2 figures, 3 tables, 21 references, submitted to ICIP 2013
Handwritten Digit Recognition with a Committee of Deep Neural Nets on GPUs
Mar 23, 2011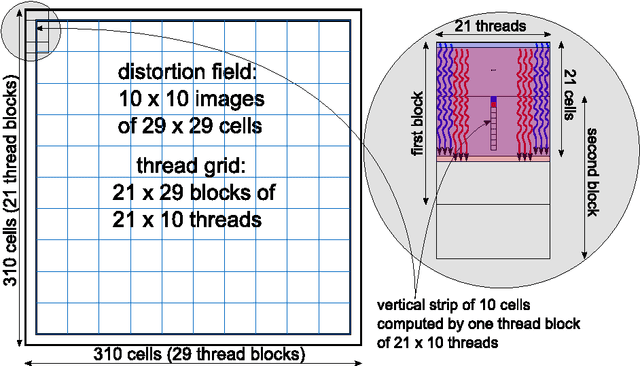
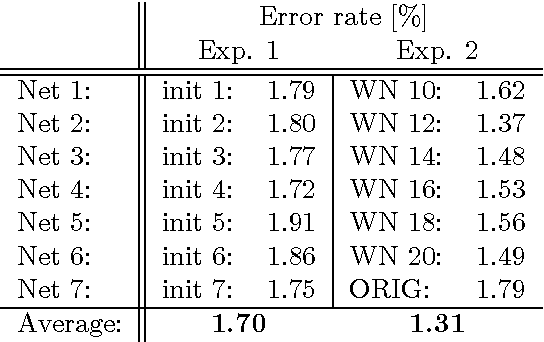
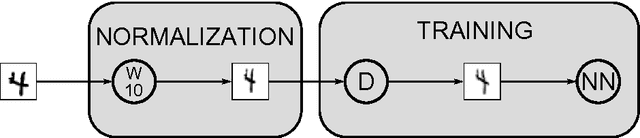
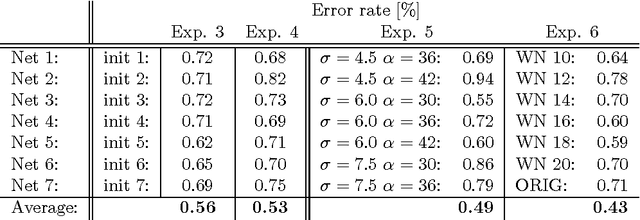
The competitive MNIST handwritten digit recognition benchmark has a long history of broken records since 1998. The most recent substantial improvement by others dates back 7 years (error rate 0.4%) . Recently we were able to significantly improve this result, using graphics cards to greatly speed up training of simple but deep MLPs, which achieved 0.35%, outperforming all the previous more complex methods. Here we report another substantial improvement: 0.31% obtained using a committee of MLPs.
High-Performance Neural Networks for Visual Object Classification
Feb 01, 2011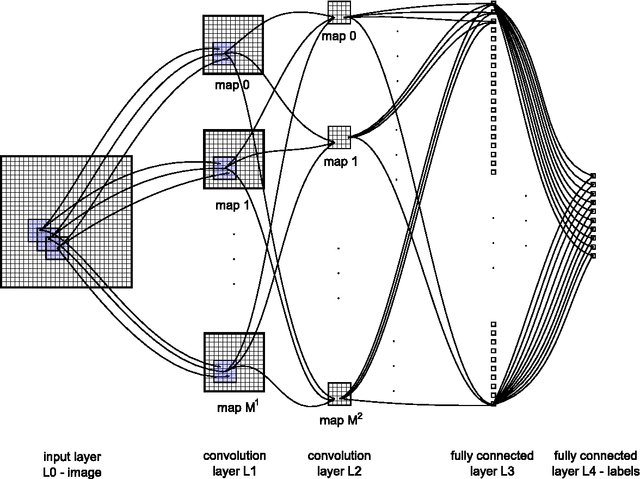


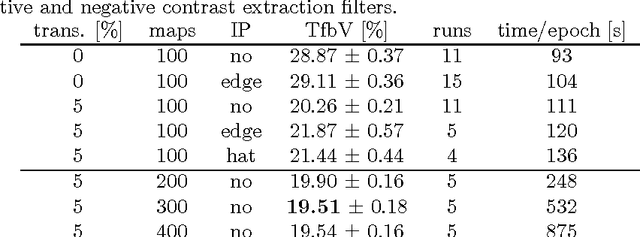
We present a fast, fully parameterizable GPU implementation of Convolutional Neural Network variants. Our feature extractors are neither carefully designed nor pre-wired, but rather learned in a supervised way. Our deep hierarchical architectures achieve the best published results on benchmarks for object classification (NORB, CIFAR10) and handwritten digit recognition (MNIST), with error rates of 2.53%, 19.51%, 0.35%, respectively. Deep nets trained by simple back-propagation perform better than more shallow ones. Learning is surprisingly rapid. NORB is completely trained within five epochs. Test error rates on MNIST drop to 2.42%, 0.97% and 0.48% after 1, 3 and 17 epochs, respectively.