 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Recognition with Multi-Scale Pyramidal Pooling Networks
Jul 07, 2012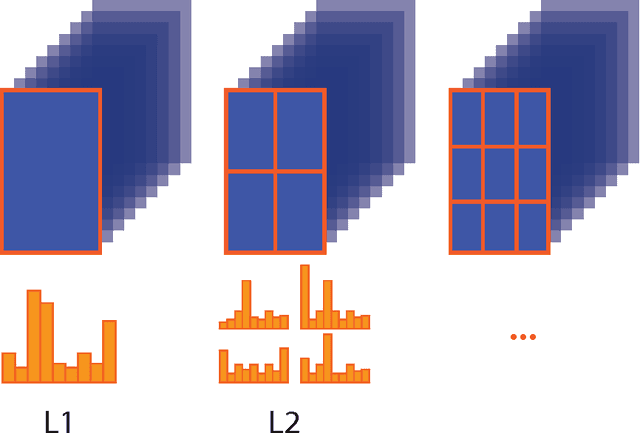

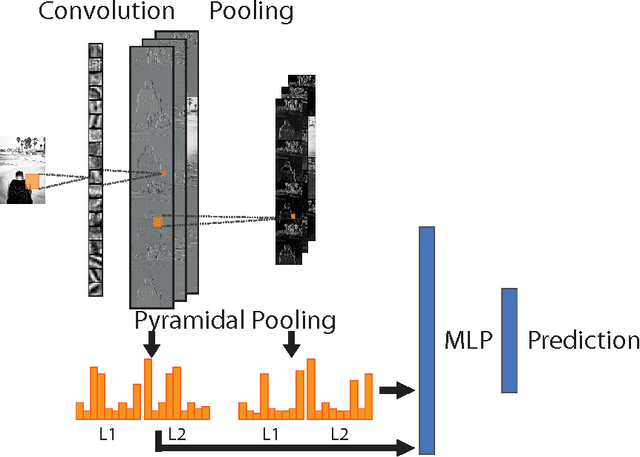

We present a Multi-Scale Pyramidal Pooling Network, featuring a novel pyramidal pooling layer at multiple scales and a novel encoding layer. Thanks to the former the network does not require all images of a given classification task to be of equal size. The encoding layer improves generalisation performance in comparison to similar neural network architectures, especially when training data is scarce. We evaluate and compare our system to convolutional neural networks and state-of-the-art computer vision methods on various benchmark datasets. We also present results on industrial steel defect classification, where existing architectures are not applicable because of the constraint on equally sized input images. The proposed architecture can be seen as a fully supervised hierarchical bag-of-features extension that is trained online and can be fine-tuned for any given task.
Multi-column Deep Neural Networks for Image Classification
Feb 13, 2012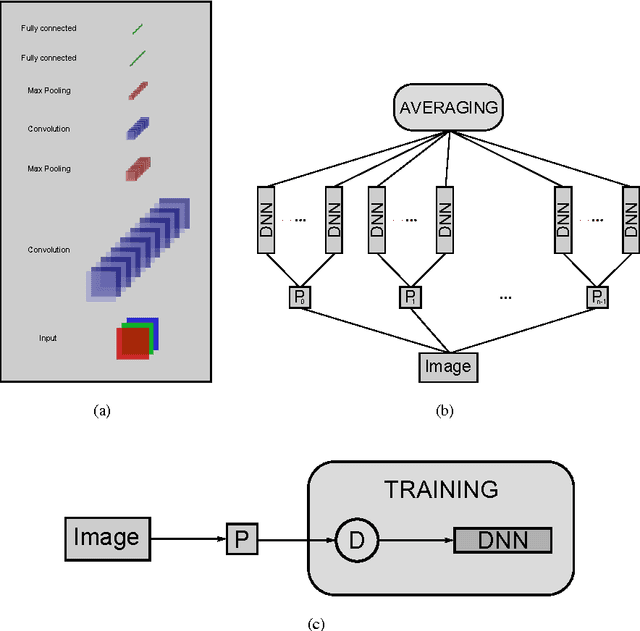
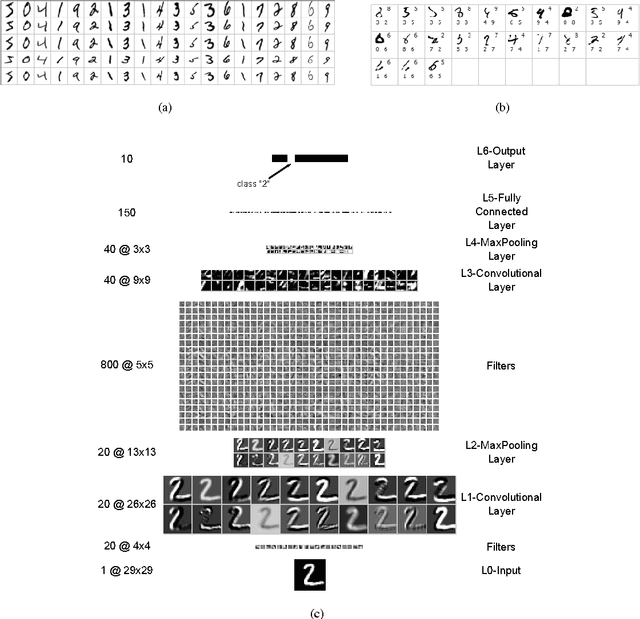

Traditional methods of computer vision and machine learning cannot match human performance on tasks such as the recognition of handwritten digits or traffic signs. Our biologically plausible deep artificial neural network architectures can. Small (often minimal) receptive fields of convolutional winner-take-all neurons yield large network depth, resulting in roughly as many sparsely connected neural layers as found in mammals between retina and visual cortex. Only winner neurons are trained. Several deep neural columns become experts on inputs preprocessed in different ways; their predictions are averaged. Graphics cards allow for fast training. On the very competitive MNIST handwriting benchmark, our method is the first to achieve near-human performance. On a traffic sign recognition benchmark it outperforms humans by a factor of two. We also improve the state-of-the-art on a plethora of common image classification benchmarks.
* 20 pages, 14 figures, 8 tables
Handwritten Digit Recognition with a Committee of Deep Neural Nets on GPUs
Mar 23, 2011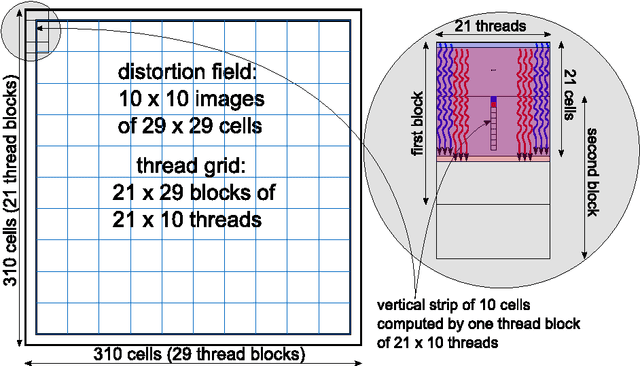
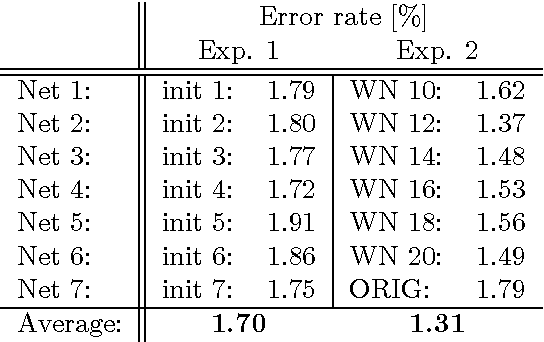
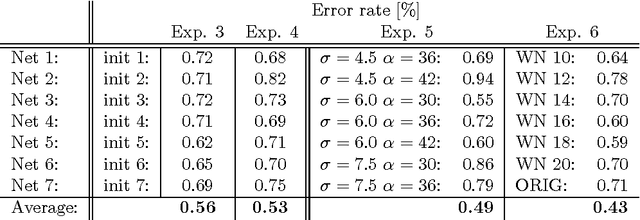
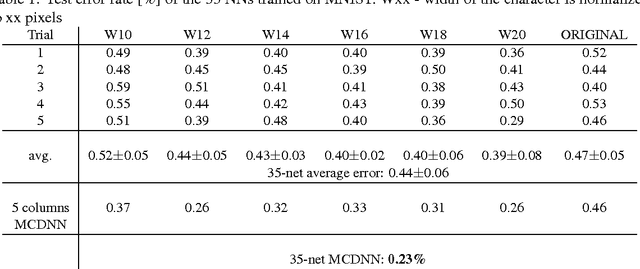
The competitive MNIST handwritten digit recognition benchmark has a long history of broken records since 1998. The most recent substantial improvement by others dates back 7 years (error rate 0.4%) . Recently we were able to significantly improve this result, using graphics cards to greatly speed up training of simple but deep MLPs, which achieved 0.35%, outperforming all the previous more complex methods. Here we report another substantial improvement: 0.31% obtained using a committee of MLPs.
High-Performance Neural Networks for Visual Object Classification
Feb 01, 2011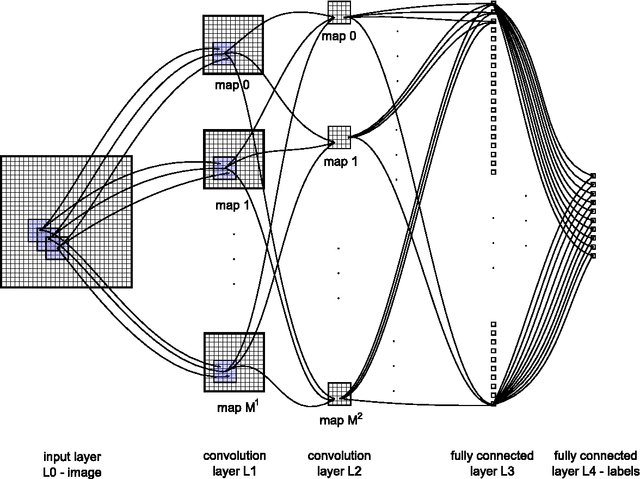


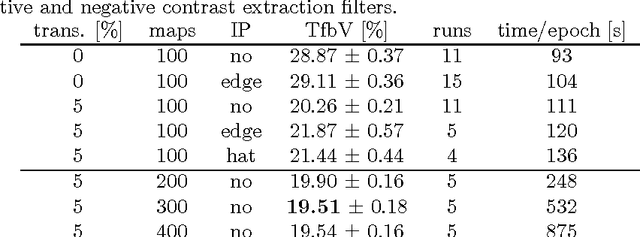
We present a fast, fully parameterizable GPU implementation of Convolutional Neural Network variants. Our feature extractors are neither carefully designed nor pre-wired, but rather learned in a supervised way. Our deep hierarchical architectures achieve the best published results on benchmarks for object classification (NORB, CIFAR10) and handwritten digit recognition (MNIST), with error rates of 2.53%, 19.51%, 0.35%, respectively. Deep nets trained by simple back-propagation perform better than more shallow ones. Learning is surprisingly rapid. NORB is completely trained within five epochs. Test error rates on MNIST drop to 2.42%, 0.97% and 0.48% after 1, 3 and 17 epochs, respectively.
Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition
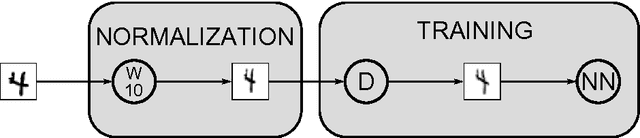
Mar 01, 2010Good old on-line back-propagation for plain multi-layer perceptrons yields a very low 0.35% error rate on the famous MNIST handwritten digits benchmark. All we need to achieve this best result so far are many hidden layers, many neurons per layer, numerous deformed training images, and graphics cards to greatly speed up learning.
* 14 pages, 2 figures, 4 listings