 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Induced Matching Distance: A Novel Topological Metric with Applications in Robotics
Feb 04, 2025This paper introduces the induced matching distance, a novel topological metric designed to compare discrete structures represented by a symmetric non-negative function. We apply this notion to analyze agent trajectories over time. We use dynamic time warping to measure trajectory similarity and compute the 0-dimensional persistent homology to identify relevant connected components, which, in our context, correspond to groups of similar trajectories. To track the evolution of these components across time, we compute induced matching distances, which preserve the coherence of their dynamic behavior. We then obtain a 1-dimensional signal that quantifies the consistency of trajectory groups over time. Our experiments demonstrate that our approach effectively differentiates between various agent behaviors, highlighting its potential as a robust tool for topological analysis in robotics and related fields.
Resource-Aware Collaborative Monte Carlo Localization with Distribution Compression
Apr 02, 2024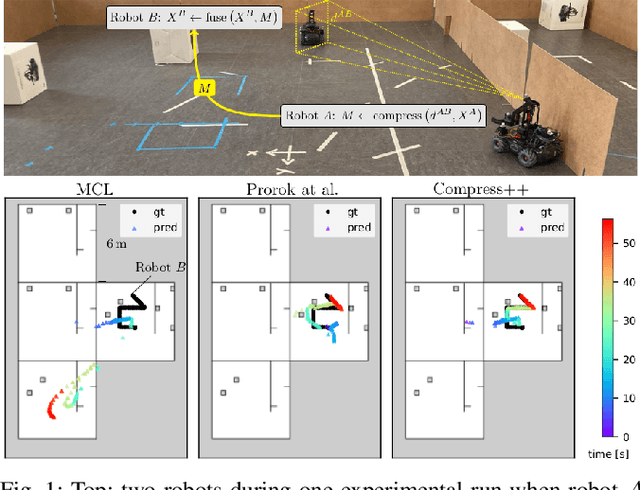
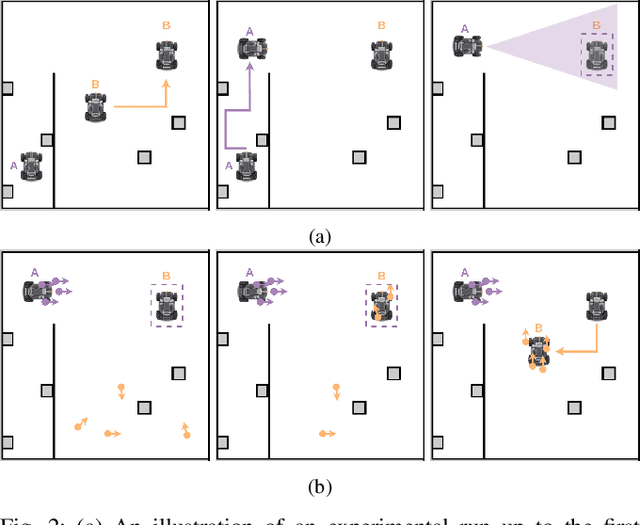
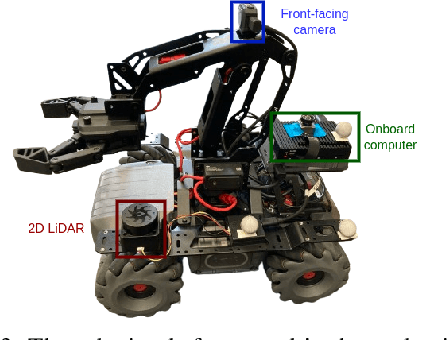
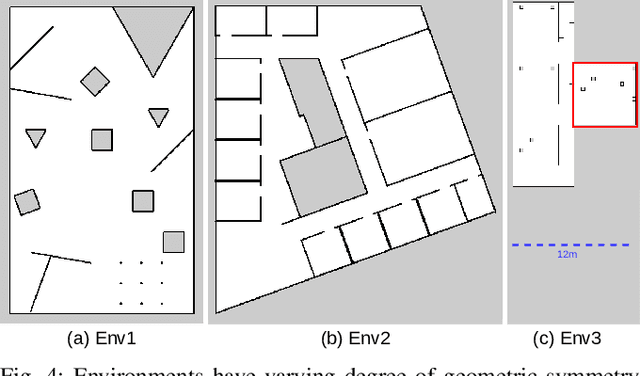
Global localization is essential in enabling robot autonomy, and collaborative localization is key for multi-robot systems. In this paper, we address the task of collaborative global localization under computational and communication constraints. We propose a method which reduces the amount of information exchanged and the computational cost. We also analyze, implement and open-source seminal approaches, which we believe to be a valuable contribution to the community. We exploit techniques for distribution compression in near-linear time, with error guarantees. We evaluate our approach and the implemented baselines on multiple challenging scenarios, simulated and real-world. Our approach can run online on an onboard computer. We release an open-source C++/ROS2 implementation of our approach, as well as the baselines
Safe Road-Crossing by Autonomous Wheelchairs: a Novel Dataset and its Experimental Evaluation
Mar 13, 2024Safe road-crossing by self-driving vehicles is a crucial problem to address in smart-cities. In this paper, we introduce a multi-sensor fusion approach to support road-crossing decisions in a system composed by an autonomous wheelchair and a flying drone featuring a robust sensory system made of diverse and redundant components. To that aim, we designed an analytical danger function based on explainable physical conditions evaluated by single sensors, including those using machine learning and artificial vision. As a proof-of-concept, we provide an experimental evaluation in a laboratory environment, showing the advantages of using multiple sensors, which can improve decision accuracy and effectively support safety assessment. We made the dataset available to the scientific community for further experimentation. The work has been developed in the context of an European project named REXASI-PRO, which aims to develop trustworthy artificial intelligence for social navigation of people with reduced mobility.
Challenges in Visual Anomaly Detection for Mobile Robots
Sep 22, 2022
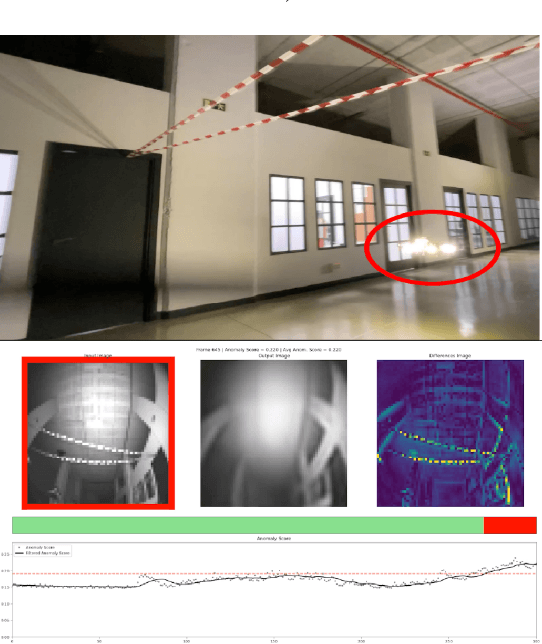
We consider the task of detecting anomalies for autonomous mobile robots based on vision. We categorize relevant types of visual anomalies and discuss how they can be detected by unsupervised deep learning methods. We propose a novel dataset built specifically for this task, on which we test a state-of-the-art approach; we finally discuss deployment in a real scenario.
An Outlier Exposure Approach to Improve Visual Anomaly Detection Performance for Mobile Robots
Sep 20, 2022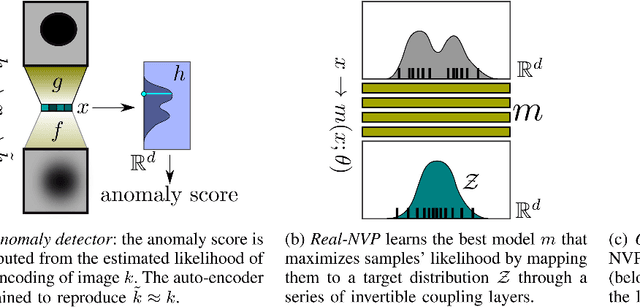


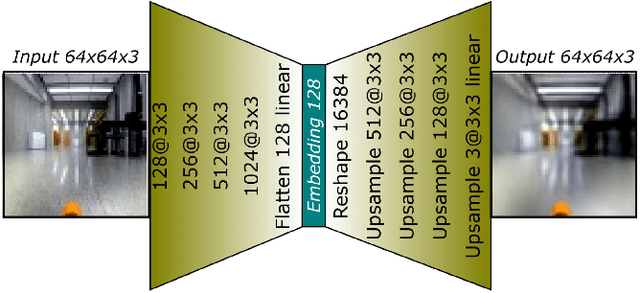
We consider the problem of building visual anomaly detection systems for mobile robots. Standard anomaly detection models are trained using large datasets composed only of non-anomalous data. However, in robotics applications, it is often the case that (potentially very few) examples of anomalies are available. We tackle the problem of exploiting these data to improve the performance of a Real-NVP anomaly detection model, by minimizing, jointly with the Real-NVP loss, an auxiliary outlier exposure margin loss. We perform quantitative experiments on a novel dataset (which we publish as supplementary material) designed for anomaly detection in an indoor patrolling scenario. On a disjoint test set, our approach outperforms alternatives and shows that exposing even a small number of anomalous frames yields significant performance improvements.
Sensing Anomalies as Potential Hazards: Datasets and Benchmarks
Oct 27, 2021

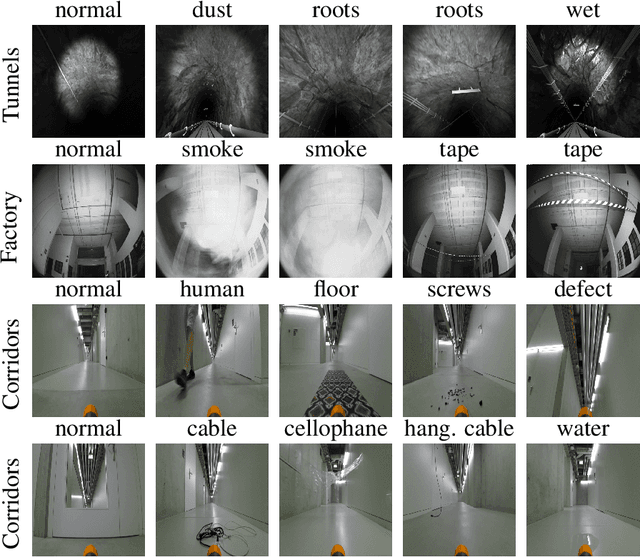
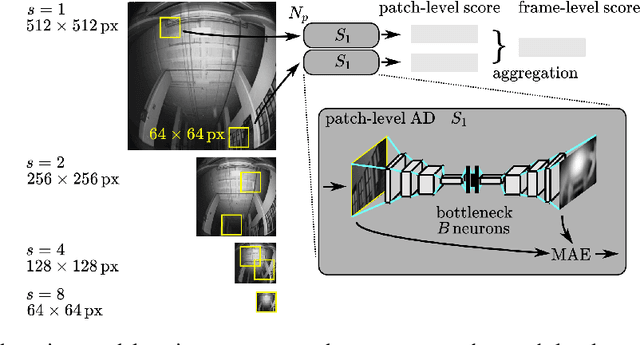
We consider the problem of detecting, in the visual sensing data stream of an autonomous mobile robot, semantic patterns that are unusual (i.e., anomalous) with respect to the robot's previous experience in similar environments. These anomalies might indicate unforeseen hazards and, in scenarios where failure is costly, can be used to trigger an avoidance behavior. We contribute three novel image-based datasets acquired in robot exploration scenarios, comprising a total of more than 200k labeled frames, spanning various types of anomalies. On these datasets, we study the performance of an anomaly detection approach based on autoencoders operating at different scales.
Training Lightweight CNNs for Human-Nanodrone Proximity Interaction from Small Datasets using Background Randomization
Oct 27, 2021


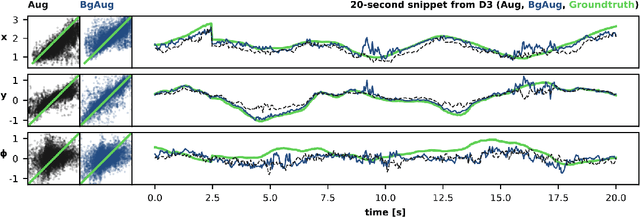
We consider the task of visually estimating the pose of a human from images acquired by a nearby nano-drone; in this context, we propose a data augmentation approach based on synthetic background substitution to learn a lightweight CNN model from a small real-world training set. Experimental results on data from two different labs proves that the approach improves generalization to unseen environments.
Uncertainty-Aware Self-Supervised Learning of Spatial Perception Tasks
Mar 22, 2021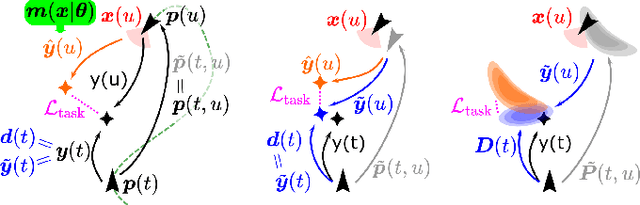
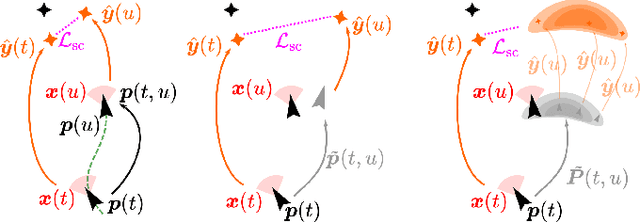
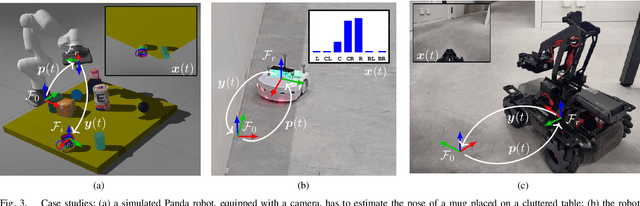

We propose a general self-supervised approach to learn neural models that solve spatial perception tasks, such as estimating the pose of an object relative to the robot, from onboard sensor readings. The model is learned from training episodes, by relying on: a continuous state estimate, possibly inaccurate and affected by odometry drift; and a detector, that sporadically provides supervision about the target pose. We demonstrate the general approach in three different concrete scenarios: a simulated robot arm that visually estimates the pose of an object of interest; a small differential drive robot using 7 infrared sensors to localize a nearby wall; an omnidirectional mobile robot that localizes itself in an environment from camera images. Quantitative results show that the approach works well in all three scenarios, and that explicitly accounting for uncertainty yields statistically significant performance improvements.
Fully Onboard AI-powered Human-Drone Pose Estimation on Ultra-low Power Autonomous Flying Nano-UAVs
Mar 19, 2021
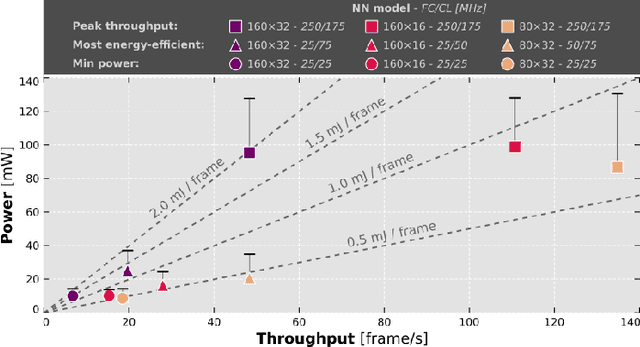
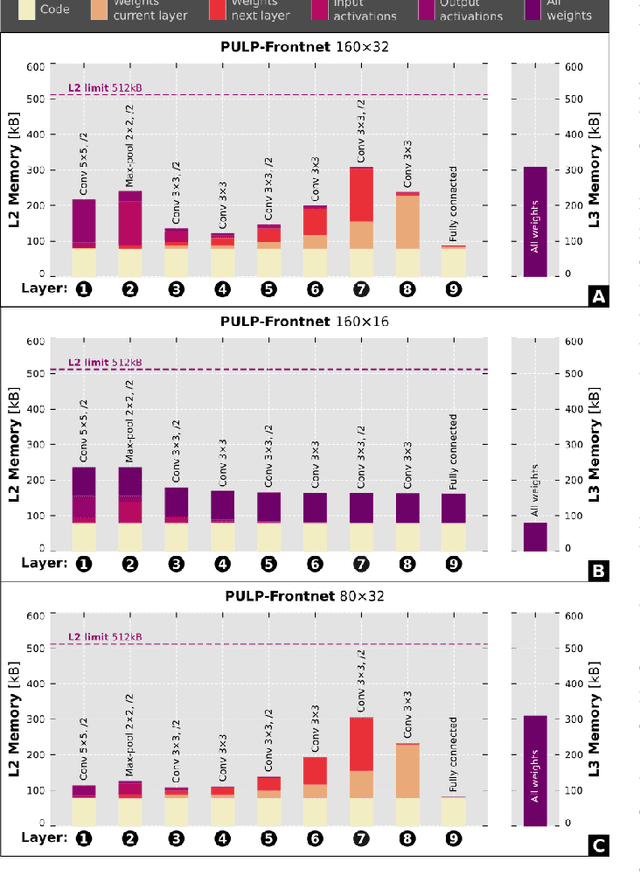
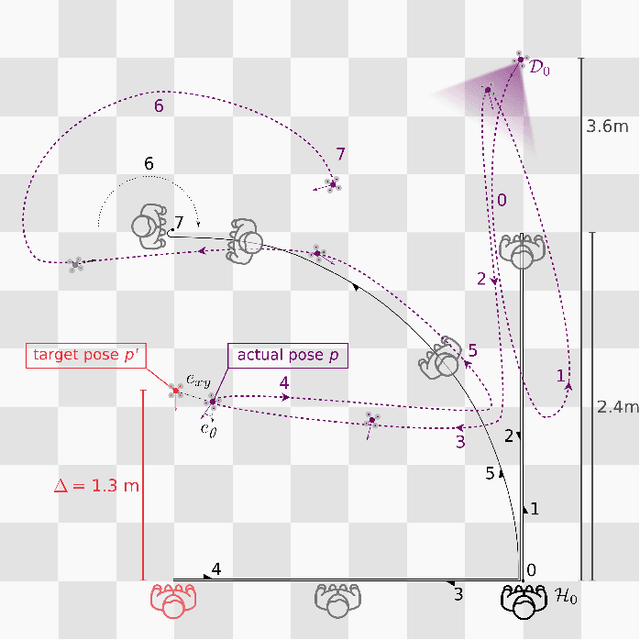
Artificial intelligence-powered pocket-sized air robots have the potential to revolutionize the Internet-of-Things ecosystem, acting as autonomous, unobtrusive, and ubiquitous smart sensors. With a few cm$^{2}$ form-factor, nano-sized unmanned aerial vehicles (UAVs) are the natural befit for indoor human-drone interaction missions, as the pose estimation task we address in this work. However, this scenario is challenged by the nano-UAVs' limited payload and computational power that severely relegates the onboard brain to the sub-100 mW microcontroller unit-class. Our work stands at the intersection of the novel parallel ultra-low-power (PULP) architectural paradigm and our general development methodology for deep neural network (DNN) visual pipelines, i.e., covering from perception to control. Addressing the DNN model design, from training and dataset augmentation to 8-bit quantization and deployment, we demonstrate how a PULP-based processor, aboard a nano-UAV, is sufficient for the real-time execution (up to 135 frame/s) of our novel DNN, called PULP-Frontnet. We showcase how, scaling our model's memory and computational requirement, we can significantly improve the onboard inference (top energy efficiency of 0.43 mJ/frame) with no compromise in the quality-of-result vs. a resource-unconstrained baseline (i.e., full-precision DNN). Field experiments demonstrate a closed-loop top-notch autonomous navigation capability, with a heavily resource-constrained 27-gram Crazyflie 2.1 nano-quadrotor. Compared against the control performance achieved using an ideal sensing setup, onboard relative pose inference yields excellent drone behavior in terms of median absolute errors, such as positional (onboard: 41 cm, ideal: 26 cm) and angular (onboard: 3.7$^{\circ}$, ideal: 4.1$^{\circ}$).
Vision-based Control of a Quadrotor in User Proximity: Mediated vs End-to-End Learning Approaches
Feb 25, 2019


We consider the task of controlling a quadrotor to hover in front of a freely moving user, using input data from an onboard camera. On this specific task we compare two widespread learning paradigms: a mediated approach, which learns an high-level state from the input and then uses it for deriving control signals; and an end-to-end approach, which skips high-level state estimation altogether. We show that despite their fundamental difference, both approaches yield equivalent performance on this task. We finally qualitatively analyze the behavior of a quadrotor implementing such approaches.