 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Induced Matching Distance: A Novel Topological Metric with Applications in Robotics
Feb 04, 2025This paper introduces the induced matching distance, a novel topological metric designed to compare discrete structures represented by a symmetric non-negative function. We apply this notion to analyze agent trajectories over time. We use dynamic time warping to measure trajectory similarity and compute the 0-dimensional persistent homology to identify relevant connected components, which, in our context, correspond to groups of similar trajectories. To track the evolution of these components across time, we compute induced matching distances, which preserve the coherence of their dynamic behavior. We then obtain a 1-dimensional signal that quantifies the consistency of trajectory groups over time. Our experiments demonstrate that our approach effectively differentiates between various agent behaviors, highlighting its potential as a robust tool for topological analysis in robotics and related fields.
Application of the representative measure approach to assess the reliability of decision trees in dealing with unseen vehicle collision data
Apr 15, 2024


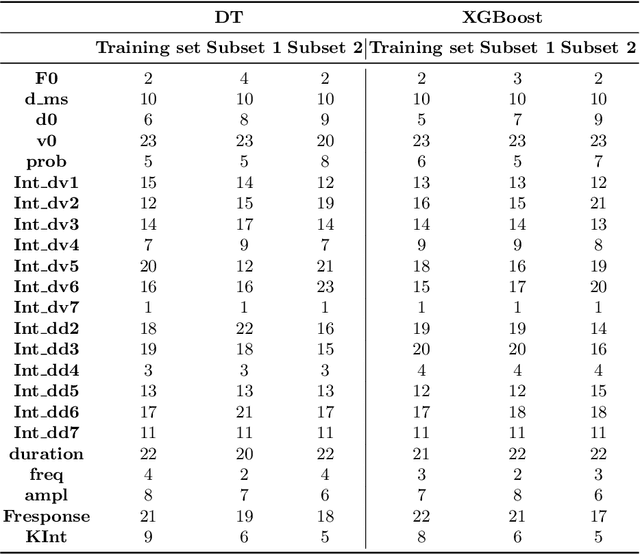
Machine learning algorithms are fundamental components of novel data-informed Artificial Intelligence architecture. In this domain, the imperative role of representative datasets is a cornerstone in shaping the trajectory of artificial intelligence (AI) development. Representative datasets are needed to train machine learning components properly. Proper training has multiple impacts: it reduces the final model's complexity, power, and uncertainties. In this paper, we investigate the reliability of the $\varepsilon$-representativeness method to assess the dataset similarity from a theoretical perspective for decision trees. We decided to focus on the family of decision trees because it includes a wide variety of models known to be explainable. Thus, in this paper, we provide a result guaranteeing that if two datasets are related by $\varepsilon$-representativeness, i.e., both of them have points closer than $\varepsilon$, then the predictions by the classic decision tree are similar. Experimentally, we have also tested that $\varepsilon$-representativeness presents a significant correlation with the ordering of the feature importance. Moreover, we extend the results experimentally in the context of unseen vehicle collision data for XGboost, a machine-learning component widely adopted for dealing with tabular data.
An In-Depth Analysis of Data Reduction Methods for Sustainable Deep Learning
Mar 22, 2024
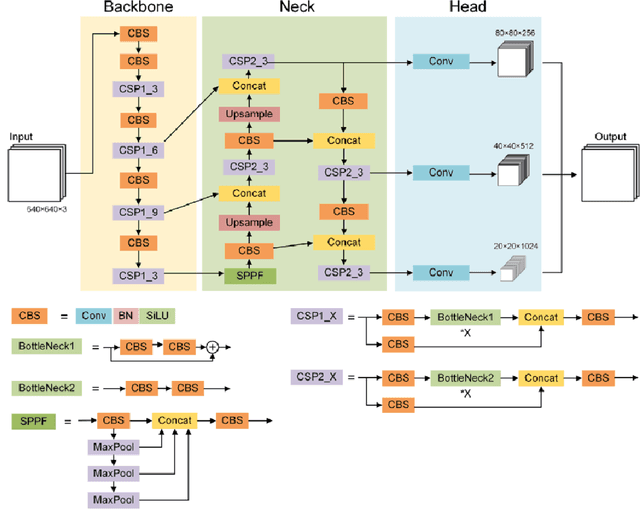
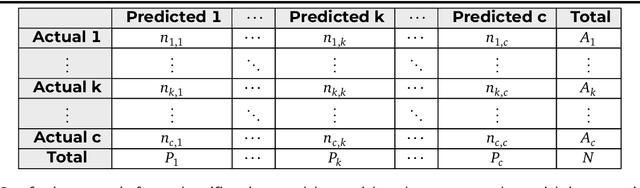
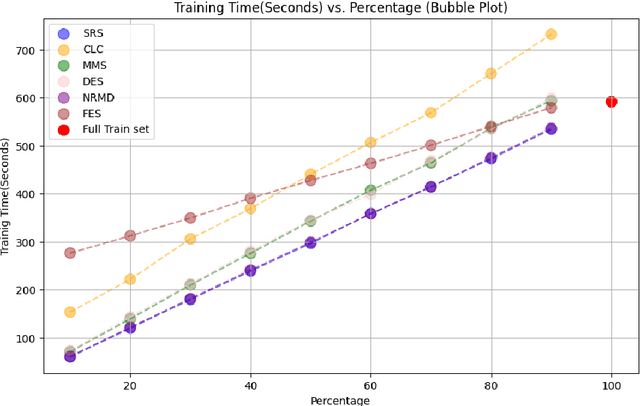
In recent years, Deep Learning has gained popularity for its ability to solve complex classification tasks, increasingly delivering better results thanks to the development of more accurate models, the availability of huge volumes of data and the improved computational capabilities of modern computers. However, these improvements in performance also bring efficiency problems, related to the storage of datasets and models, and to the waste of energy and time involved in both the training and inference processes. In this context, data reduction can help reduce energy consumption when training a deep learning model. In this paper, we present up to eight different methods to reduce the size of a tabular training dataset, and we develop a Python package to apply them. We also introduce a representativeness metric based on topology to measure how similar are the reduced datasets and the full training dataset. Additionally, we develop a methodology to apply these data reduction methods to image datasets for object detection tasks. Finally, we experimentally compare how these data reduction methods affect the representativeness of the reduced dataset, the energy consumption and the predictive performance of the model.