 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMPO: Automatic Multi-Branched Prompt Optimization
Oct 11, 2024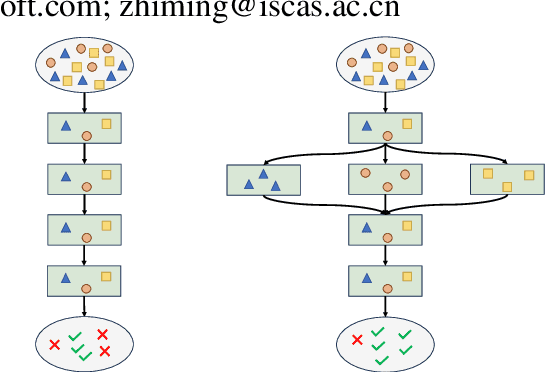
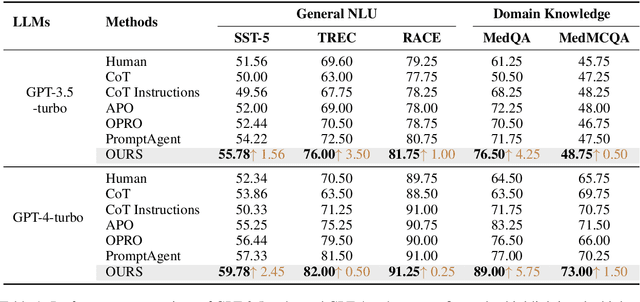
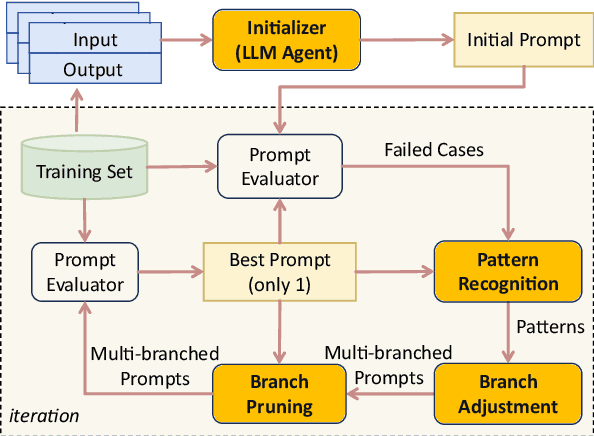
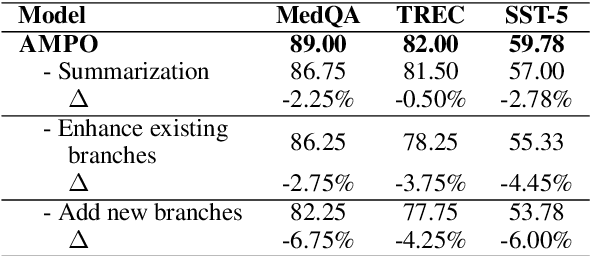
Prompt engineering is very important to enhance the performance of large language models (LLMs). When dealing with complex issues, prompt engineers tend to distill multiple patterns from examples and inject relevant solutions to optimize the prompts, achieving satisfying results. However, existing automatic prompt optimization techniques are only limited to producing single flow instructions, struggling with handling diverse patterns. In this paper, we present AMPO, an automatic prompt optimization method that can iteratively develop a multi-branched prompt using failure cases as feedback. Our goal is to explore a novel way of structuring prompts with multi-branches to better handle multiple patterns in complex tasks, for which we introduce three modules: Pattern Recognition, Branch Adjustment, and Branch Pruning. In experiments across five tasks, AMPO consistently achieves the best results. Additionally, our approach demonstrates significant optimization efficiency due to our adoption of a minimal search strategy.
StraGo: Harnessing Strategic Guidance for Prompt Optimization
Oct 11, 2024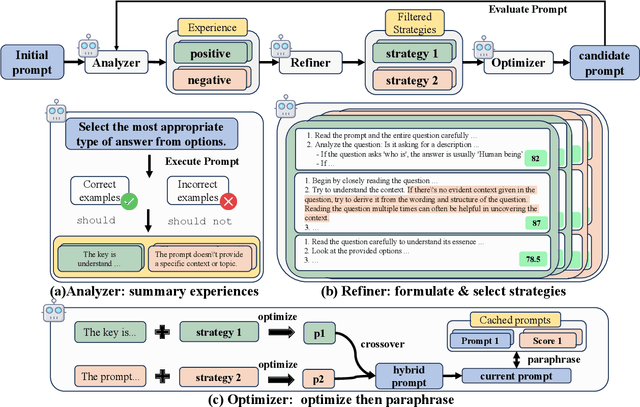
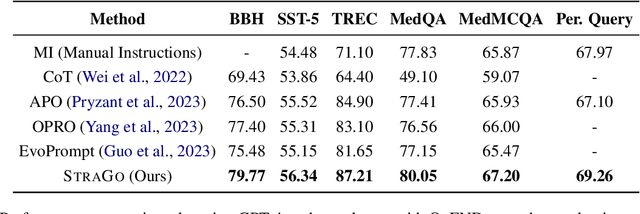
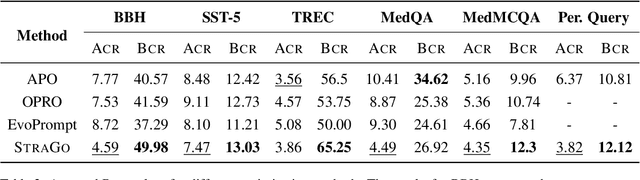
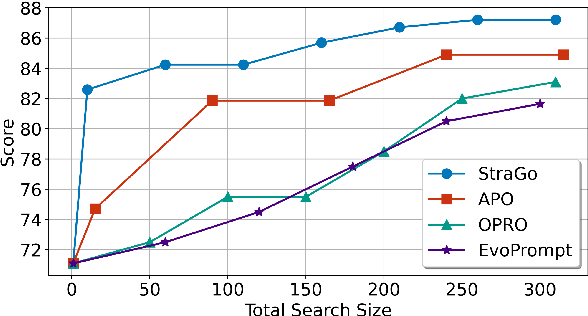
Prompt engineering is pivotal for harnessing the capabilities of large language models (LLMs) across diverse applications. While existing prompt optimization methods improve prompt effectiveness, they often lead to prompt drifting, where newly generated prompts can adversely impact previously successful cases while addressing failures. Furthermore, these methods tend to rely heavily on LLMs' intrinsic capabilities for prompt optimization tasks. In this paper, we introduce StraGo (Strategic-Guided Optimization), a novel approach designed to mitigate prompt drifting by leveraging insights from both successful and failed cases to identify critical factors for achieving optimization objectives. StraGo employs a how-to-do methodology, integrating in-context learning to formulate specific, actionable strategies that provide detailed, step-by-step guidance for prompt optimization. Extensive experiments conducted across a range of tasks, including reasoning, natural language understanding, domain-specific knowledge, and industrial applications, demonstrate StraGo's superior performance. It establishes a new state-of-the-art in prompt optimization, showcasing its ability to deliver stable and effective prompt improvements.