 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Video Object Segmentation by Motion-Aware Mask Propagation
Paper and Code
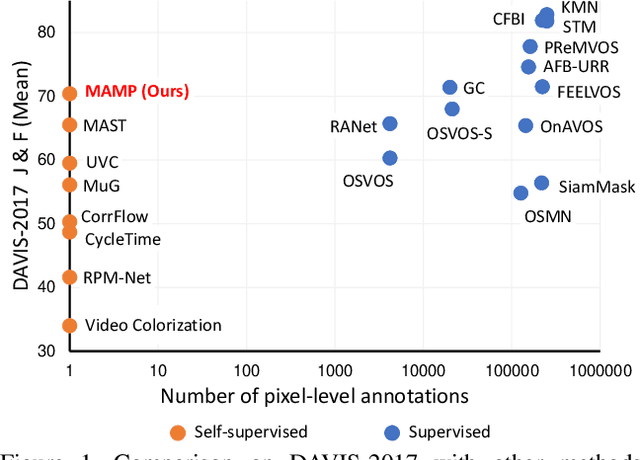

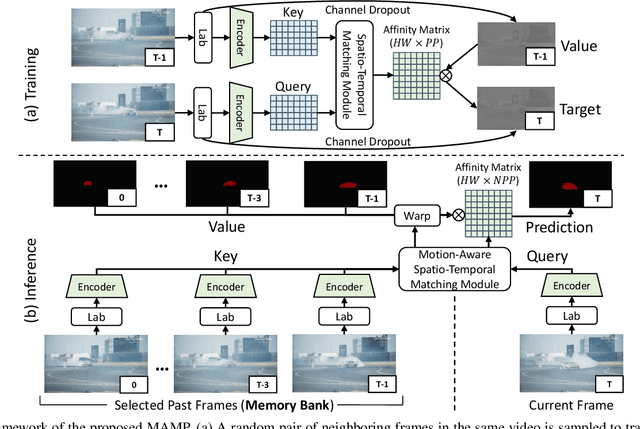
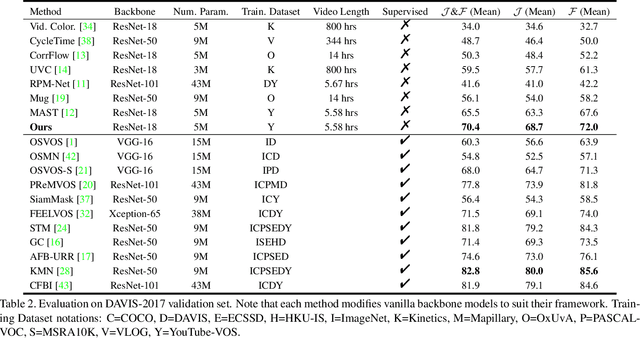
We propose a self-supervised spatio-temporal matching method coined Motion-Aware Mask Propagation (MAMP) for semi-supervised video object segmentation. During training, MAMP leverages the frame reconstruction task to train the model without the need for annotations. During inference, MAMP extracts high-resolution features from each frame to build a memory bank from the features as well as the predicted masks of selected past frames. MAMP then propagates the masks from the memory bank to subsequent frames according to our motion-aware spatio-temporal matching module, also proposed in this paper. Evaluation on DAVIS-2017 and YouTube-VOS datasets show that MAMP achieves state-of-the-art performance with stronger generalization ability compared to existing self-supervised methods, i.e. 4.9\% higher mean $\mathcal{J}\&\mathcal{F}$ on DAVIS-2017 and 4.85\% higher mean $\mathcal{J}\&\mathcal{F}$ on the unseen categories of YouTube-VOS than the nearest competitor. Moreover, MAMP performs on par with many supervised video object segmentation methods. Our code is available at: \url{https://github.com/bo-miao/MAMP}.