 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion Aware Video Object Segmentation with Deep Motion Modeling
Paper and Code
Jul 21, 2022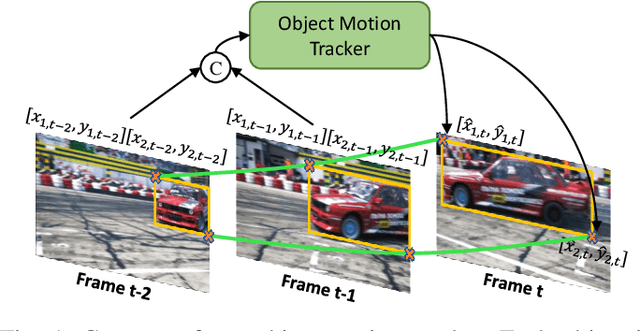
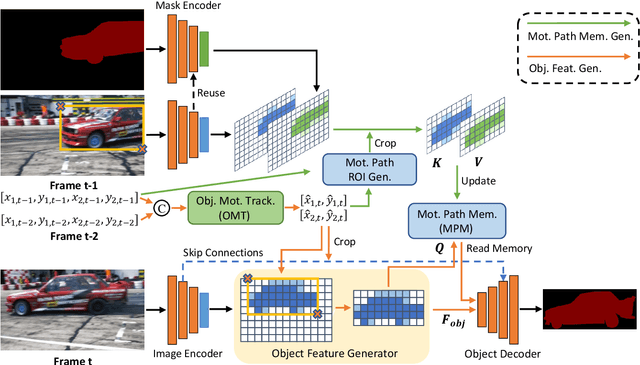

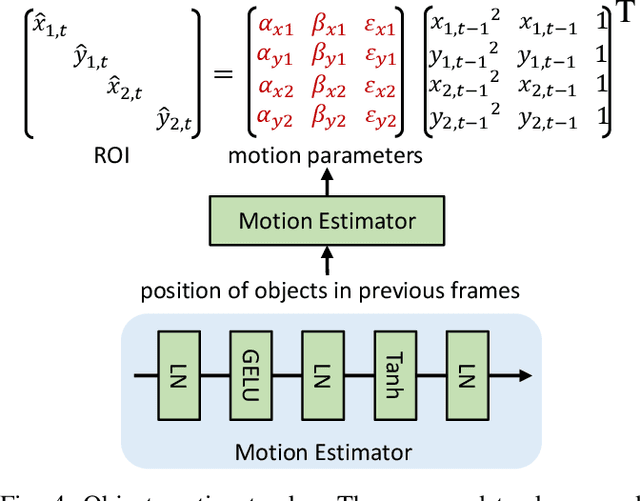
Current semi-supervised video object segmentation (VOS) methods usually leverage the entire features of one frame to predict object masks and update memory. This introduces significant redundant computations. To reduce redundancy, we present a Region Aware Video Object Segmentation (RAVOS) approach that predicts regions of interest (ROIs) for efficient object segmentation and memory storage. RAVOS includes a fast object motion tracker to predict their ROIs in the next frame. For efficient segmentation, object features are extracted according to the ROIs, and an object decoder is designed for object-level segmentation. For efficient memory storage, we propose motion path memory to filter out redundant context by memorizing the features within the motion path of objects between two frames. Besides RAVOS, we also propose a large-scale dataset, dubbed OVOS, to benchmark the performance of VOS models under occlusions. Evaluation on DAVIS and YouTube-VOS benchmarks and our new OVOS dataset show that our method achieves state-of-the-art performance with significantly faster inference time, e.g., 86.1 J&F at 42 FPS on DAVIS and 84.4 J&F at 23 FPS on YouTube-VOS.