 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuning Offline World Models in the Real World
Oct 24, 2023
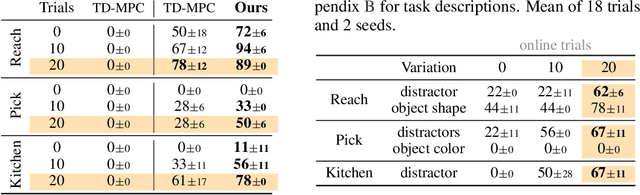


Reinforcement Learning (RL) is notoriously data-inefficient, which makes training on a real robot difficult. While model-based RL algorithms (world models) improve data-efficiency to some extent, they still require hours or days of interaction to learn skills. Recently, offline RL has been proposed as a framework for training RL policies on pre-existing datasets without any online interaction. However, constraining an algorithm to a fixed dataset induces a state-action distribution shift between training and inference, and limits its applicability to new tasks. In this work, we seek to get the best of both worlds: we consider the problem of pretraining a world model with offline data collected on a real robot, and then finetuning the model on online data collected by planning with the learned model. To mitigate extrapolation errors during online interaction, we propose to regularize the planner at test-time by balancing estimated returns and (epistemic) model uncertainty. We evaluate our method on a variety of visuo-motor control tasks in simulation and on a real robot, and find that our method enables few-shot finetuning to seen and unseen tasks even when offline data is limited. Videos, code, and data are available at https://yunhaifeng.com/FOWM .
Deep learning in a bilateral brain with hemispheric specialization
Sep 19, 2022



The brains of all bilaterally symmetric animals on Earth are are divided into left and right hemispheres. The anatomy and functionality of the hemispheres have a large degree of overlap, but they specialize to possess different attributes. The left hemisphere is believed to specialize in specificity and routine, the right in generalities and novelty. In this study, we propose an artificial neural network that imitates that bilateral architecture using two convolutional neural networks with different training objectives and test it on an image classification task. The bilateral architecture outperforms architectures of similar representational capacity that don't exploit differential specialization. It demonstrates the efficacy of bilateralism and constitutes a new principle that could be incorporated into other computational neuroscientific models and used as an inductive bias when designing new ML systems. An analysis of the model can help us to understand the human brain.