 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraceful task adaptation with a bi-hemispheric RL agent
Jul 16, 2024



In humans, responsibility for performing a task gradually shifts from the right hemisphere to the left. The Novelty-Routine Hypothesis (NRH) states that the right and left hemispheres are used to perform novel and routine tasks respectively, enabling us to learn a diverse range of novel tasks while performing the task capably. Drawing on the NRH, we develop a reinforcement learning agent with specialised hemispheres that can exploit generalist knowledge from the right-hemisphere to avoid poor initial performance on novel tasks. In addition, we find that this design has minimal impact on its ability to learn novel tasks. We conclude by identifying improvements to our agent and exploring potential expansion to the continual learning setting.
Augmenting Replay in World Models for Continual Reinforcement Learning
Jan 30, 2024



In continual RL, the environment of a reinforcement learning (RL) agent undergoes change. A successful system should appropriately balance the conflicting requirements of retaining agent performance on already learned tasks, stability, whilst learning new tasks, plasticity. The first-in-first-out buffer is commonly used to enhance learning in such settings but requires significant memory. We explore the application of an augmentation to this buffer which alleviates the memory constraints, and use it with a world model model-based reinforcement learning algorithm, to evaluate its effectiveness in facilitating continual learning. We evaluate the effectiveness of our method in Procgen and Atari RL benchmarks and show that the distribution matching augmentation to the replay-buffer used in the context of latent world models can successfully prevent catastrophic forgetting with significantly reduced computational overhead. Yet, we also find such a solution to not be entirely infallible, and other failure modes such as the opposite -- lacking plasticity and being unable to learn a new task -- to be a potential limitation in continual learning systems.
Left/Right Brain, human motor control and the implications for robotics
Jan 25, 2024Neural Network movement controllers promise a variety of advantages over conventional control methods however they are not widely adopted due to their inability to produce reliably precise movements. This research explores a bilateral neural network architecture as a control system for motor tasks. We aimed to achieve hemispheric specialisation similar to what is observed in humans across different tasks; the dominant system (usually the right hand, left hemisphere) excels at tasks involving coordination and efficiency of movement, and the non-dominant system performs better at tasks requiring positional stability. Specialisation was achieved by training the hemispheres with different loss functions tailored toward the expected behaviour of the respective hemispheres. We compared bilateral models with and without specialised hemispheres, with and without inter-hemispheric connectivity (representing the biological Corpus Callosum), and unilateral models with and without specialisation. The models were trained and tested on two tasks common in the human motor control literature: the random reach task, suited to the dominant system, a model with better coordination, and the hold position task, suited to the non-dominant system, a model with more stable movement. Each system out-performed the non-favoured system in its preferred task. For both tasks, a bilateral model outperforms the 'non-preferred' hand, and is as good or better than the 'preferred' hand. The Corpus Callosum tends to improve performance, but not always for the specialised models.
Deep learning in a bilateral brain with hemispheric specialization
Sep 19, 2022



The brains of all bilaterally symmetric animals on Earth are are divided into left and right hemispheres. The anatomy and functionality of the hemispheres have a large degree of overlap, but they specialize to possess different attributes. The left hemisphere is believed to specialize in specificity and routine, the right in generalities and novelty. In this study, we propose an artificial neural network that imitates that bilateral architecture using two convolutional neural networks with different training objectives and test it on an image classification task. The bilateral architecture outperforms architectures of similar representational capacity that don't exploit differential specialization. It demonstrates the efficacy of bilateralism and constitutes a new principle that could be incorporated into other computational neuroscientific models and used as an inductive bias when designing new ML systems. An analysis of the model can help us to understand the human brain.
One-shot learning for the long term: consolidation with an artificial hippocampal algorithm
Feb 15, 2021
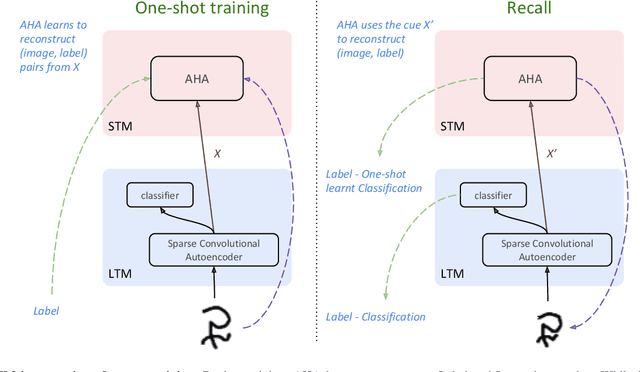


Standard few-shot experiments involve learning to efficiently match previously unseen samples by class. We claim that few-shot learning should be long term, assimilating knowledge for the future, without forgetting previous concepts. In the mammalian brain, the hippocampus is understood to play a significant role in this process, by learning rapidly and consolidating knowledge to the neocortex over a short term period. In this research we tested whether an artificial hippocampal algorithm, AHA, could be used with a conventional ML model analogous to the neocortex, to achieve one-shot learning both short and long term. The results demonstrated that with the addition of AHA, the system could learn in one-shot and consolidate the knowledge for the long term without catastrophic forgetting. This study is one of the first examples of using a CLS model of hippocampus to consolidate memories, and it constitutes a step toward few-shot continual learning.
Unsupervised One-shot Learning of Both Specific Instances and Generalised Classes with a Hippocampal Architecture
Oct 30, 2020



Established experimental procedures for one-shot machine learning do not test the ability to learn or remember specific instances of classes, a key feature of animal intelligence. Distinguishing specific instances is necessary for many real-world tasks, such as remembering which cup belongs to you. Generalisation within classes conflicts with the ability to separate instances of classes, making it difficult to achieve both capabilities within a single architecture. We propose an extension to the standard Omniglot classification-generalisation framework that additionally tests the ability to distinguish specific instances after one exposure and introduces noise and occlusion corruption. Learning is defined as an ability to classify as well as recall training samples. Complementary Learning Systems (CLS) is a popular model of mammalian brain regions believed to play a crucial role in learning from a single exposure to a stimulus. We created an artificial neural network implementation of CLS and applied it to the extended Omniglot benchmark. Our unsupervised model demonstrates comparable performance to existing supervised ANNs on the Omniglot classification task (requiring generalisation), without the need for domain-specific inductive biases. On the extended Omniglot instance-recognition task, the same model also demonstrates significantly better performance than a baseline nearest-neighbour approach, given partial occlusion and noise.
AHA! an 'Artificial Hippocampal Algorithm' for Episodic Machine Learning
Nov 01, 2019



The majority of ML research concerns slow, statistical learning of i.i.d. samples from large, labelled datasets. Animals do not learn this way. An enviable characteristic of animal learning is 'episodic' learning - the ability to rapidly memorize a specific experience as a composition of existing concepts, without provided labels. The new knowledge can then be used to distinguish between similar experiences, to generalize between classes, and to selectively consolidate to long-term memory. The Hippocampus is known to be vital to these abilities. AHA is a biologically-plausible computational model of the Hippocampus. Unlike most machine learning models, AHA is trained without any external labels and uses only local and immediate credit assignment. We demonstrate AHA in a superset of the Omniglot classification benchmark. The extended benchmark covers a wider range of known Hippocampal functions by testing pattern separation, completion, and reconstruction of original input. These functions are all performed within a single configuration of the computational model. Despite these constraints, results are comparable to state-of-the-art deep convolutional ANNs. In addition to the demonstrated high degree of functional overlap with the Hippocampal region, AHA is remarkably aligned to current macro-scale biological models and uses biologically plausible micro-scale learning rules.
Learning distant cause and effect using only local and immediate credit assignment
May 28, 2019


We present a recurrent neural network memory that uses sparse coding to create a combinatoric encoding of sequential inputs. Using several examples, we show that the network can associate distant causes and effects in a discrete stochastic process, predict partially-observable higher-order sequences, and enable a DQN agent to navigate a maze by giving it memory. The network uses only biologically-plausible, local and immediate credit assignment. Memory requirements are typically one order of magnitude less than existing LSTM, GRU and autoregressive feed-forward sequence learning models. The most significant limitation of the memory is generalization to unseen input sequences. We explore this limitation by measuring next-word prediction perplexity on the Penn Treebank dataset.
Sparse Unsupervised Capsules Generalize Better
Apr 17, 2018


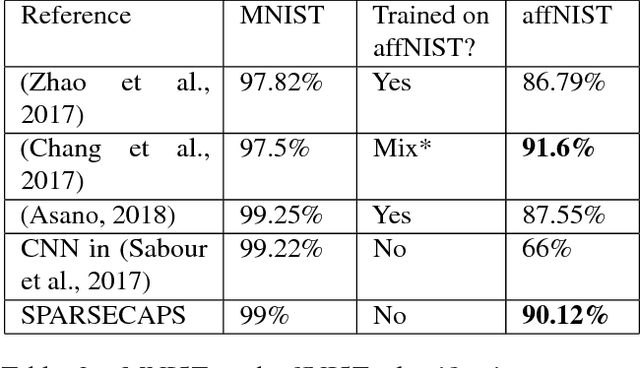
We show that unsupervised training of latent capsule layers using only the reconstruction loss, without masking to select the correct output class, causes a loss of equivariances and other desirable capsule qualities. This implies that supervised capsules networks can't be very deep. Unsupervised sparsening of latent capsule layer activity both restores these qualities and appears to generalize better than supervised masking, while potentially enabling deeper capsules networks. We train a sparse, unsupervised capsules network of similar geometry to Sabour et al (2017) on MNIST, and then test classification accuracy on affNIST using an SVM layer. Accuracy is improved from benchmark 79% to 90%.