Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Unsupervised Semantic Inpainting: A GAN Based Approach
Paper and Code
Aug 14, 2019
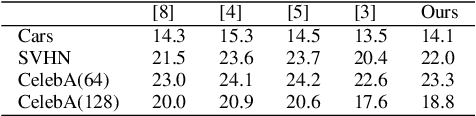


In this paper, we propose to improve the inference speed and visual quality of contemporary baseline of Generative Adversarial Networks (GAN) based unsupervised semantic inpainting. This is made possible with better initialization of the core iterative optimization involved in the framework. To our best knowledge, this is also the first attempt of GAN based video inpainting with consideration to temporal cues. On single image inpainting, we achieve about 4.5-5$\times$ speedup and 80$\times$ on videos compared to baseline. Simultaneously, our method has better spatial and temporal reconstruction qualities as found on three image and one video dataset.
* Accepted as full paper at IEEE ICIP, 2019
View paper on