 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton based Zero Shot Action Recognition in Joint Pose-Language Semantic Space
Paper and Code
Nov 26, 2019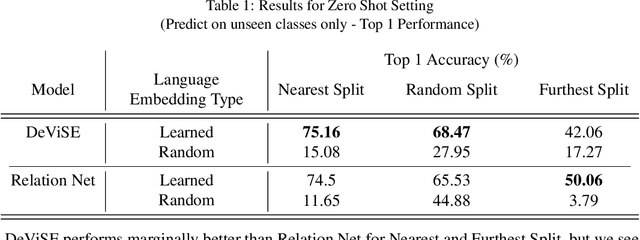
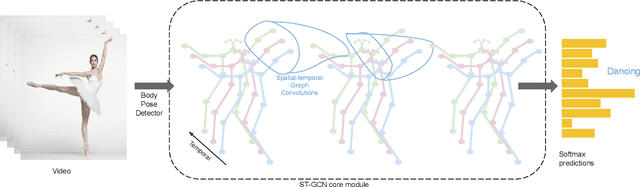
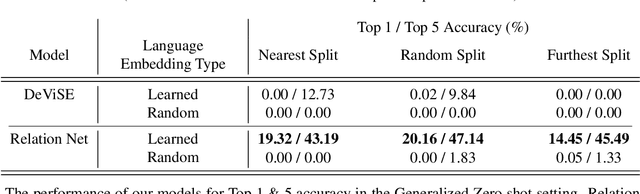
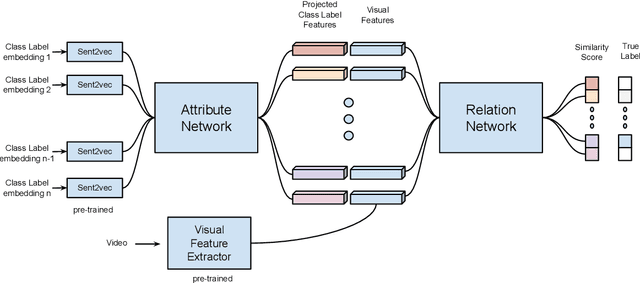
How does one represent an action? How does one describe an action that we have never seen before? Such questions are addressed by the Zero Shot Learning paradigm, where a model is trained on only a subset of classes and is evaluated on its ability to correctly classify an example from a class it has never seen before. In this work, we present a body pose based zero shot action recognition network and demonstrate its performance on the NTU RGB-D dataset. Our model learns to jointly encapsulate visual similarities based on pose features of the action performer as well as similarities in the natural language descriptions of the unseen action class names. We demonstrate how this pose-language semantic space encodes knowledge which allows our model to correctly predict actions not seen during training.