 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector
Paper and Code
Apr 04, 2025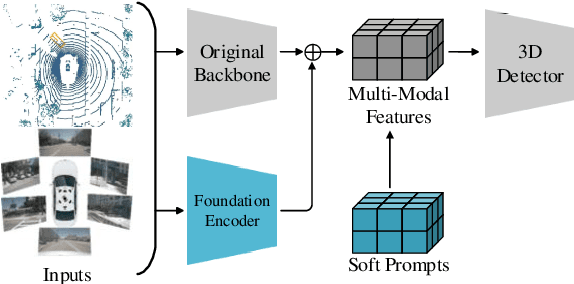
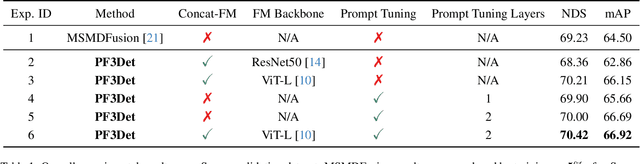
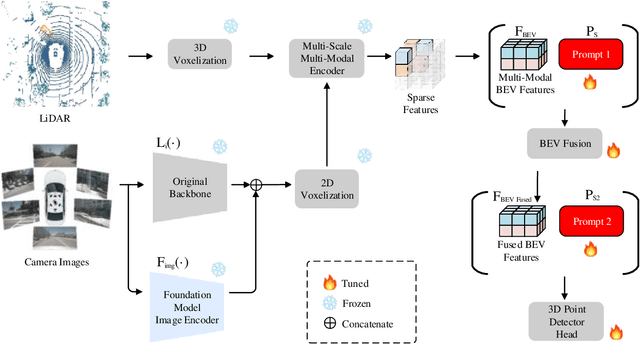

3D object detection is crucial for autonomous driving, leveraging both LiDAR point clouds for precise depth information and camera images for rich semantic information. Therefore, the multi-modal methods that combine both modalities offer more robust detection results. However, efficiently fusing LiDAR points and images remains challenging due to the domain gaps. In addition, the performance of many models is limited by the amount of high quality labeled data, which is expensive to create. The recent advances in foundation models, which use large-scale pre-training on different modalities, enable better multi-modal fusion. Combining the prompt engineering techniques for efficient training, we propose the Prompted Foundational 3D Detector (PF3Det), which integrates foundation model encoders and soft prompts to enhance LiDAR-camera feature fusion. PF3Det achieves the state-of-the-art results under limited training data, improving NDS by 1.19% and mAP by 2.42% on the nuScenes dataset, demonstrating its efficiency in 3D detection.