 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailedCore: Few-Shot Sampling for Unsupervised Long-Tail Noisy Anomaly Detection
Apr 03, 2025



We aim to solve unsupervised anomaly detection in a practical challenging environment where the normal dataset is both contaminated with defective regions and its product class distribution is tailed but unknown. We observe that existing models suffer from tail-versus-noise trade-off where if a model is robust against pixel noise, then its performance deteriorates on tail class samples, and vice versa. To mitigate the issue, we handle the tail class and noise samples independently. To this end, we propose TailSampler, a novel class size predictor that estimates the class cardinality of samples based on a symmetric assumption on the class-wise distribution of embedding similarities. TailSampler can be utilized to sample the tail class samples exclusively, allowing to handle them separately. Based on these facets, we build a memory-based anomaly detection model TailedCore, whose memory both well captures tail class information and is noise-robust. We extensively validate the effectiveness of TailedCore on the unsupervised long-tail noisy anomaly detection setting, and show that TailedCore outperforms the state-of-the-art in most settings.
Face Reconstruction Transfer Attack as Out-of-Distribution Generalization
Jul 02, 2024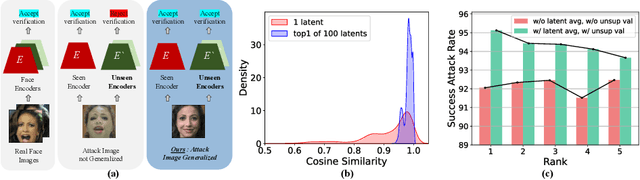
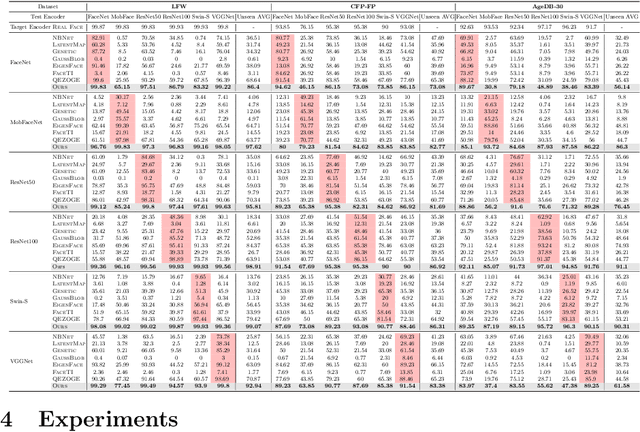
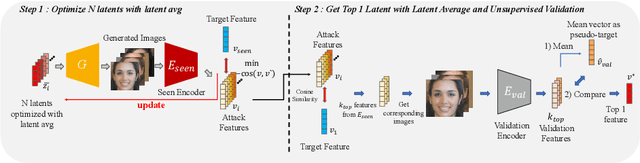
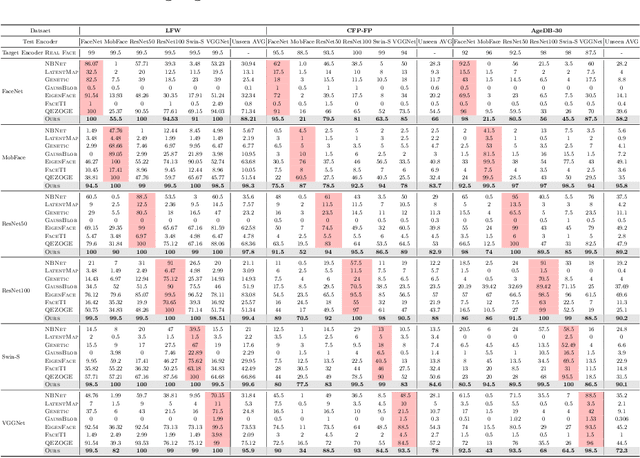
Understanding the vulnerability of face recognition systems to malicious attacks is of critical importance. Previous works have focused on reconstructing face images that can penetrate a targeted verification system. Even in the white-box scenario, however, naively reconstructed images misrepresent the identity information, hence the attacks are easily neutralized once the face system is updated or changed. In this paper, we aim to reconstruct face images which are capable of transferring face attacks on unseen encoders. We term this problem as Face Reconstruction Transfer Attack (FRTA) and show that it can be formulated as an out-of-distribution (OOD) generalization problem. Inspired by its OOD nature, we propose to solve FRTA by Averaged Latent Search and Unsupervised Validation with pseudo target (ALSUV). To strengthen the reconstruction attack on OOD unseen encoders, ALSUV reconstructs the face by searching the latent of amortized generator StyleGAN2 through multiple latent optimization, latent optimization trajectory averaging, and unsupervised validation with a pseudo target. We demonstrate the efficacy and generalization of our method on widely used face datasets, accompanying it with extensive ablation studies and visually, qualitatively, and quantitatively analyses. The source code will be released.
Nearest Neighbor Guidance for Out-of-Distribution Detection
Sep 26, 2023Detecting out-of-distribution (OOD) samples are crucial for machine learning models deployed in open-world environments. Classifier-based scores are a standard approach for OOD detection due to their fine-grained detection capability. However, these scores often suffer from overconfidence issues, misclassifying OOD samples distant from the in-distribution region. To address this challenge, we propose a method called Nearest Neighbor Guidance (NNGuide) that guides the classifier-based score to respect the boundary geometry of the data manifold. NNGuide reduces the overconfidence of OOD samples while preserving the fine-grained capability of the classifier-based score. We conduct extensive experiments on ImageNet OOD detection benchmarks under diverse settings, including a scenario where the ID data undergoes natural distribution shift. Our results demonstrate that NNGuide provides a significant performance improvement on the base detection scores, achieving state-of-the-art results on both AUROC, FPR95, and AUPR metrics. The code is given at \url{https://github.com/roomo7time/nnguide}.
Periocular in the Wild Embedding Learning with Cross-Modal Consistent Knowledge Distillation
Dec 12, 2020
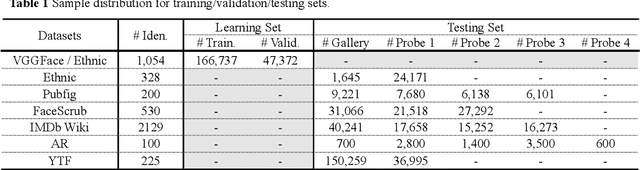
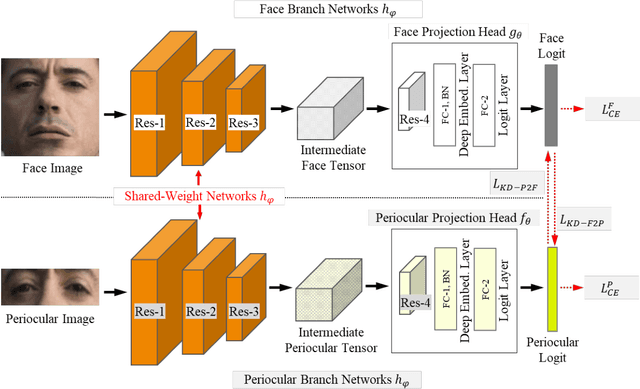

Periocular biometric, or peripheral area of ocular, is a collaborative alternative to face, especially if a face is occluded or masked. In practice, sole periocular biometric captures least salient facial features, thereby suffering from intra-class compactness and inter-class dispersion issues particularly in the wild environment. To address these problems, we transfer useful information from face to support periocular modality by means of knowledge distillation (KD) for embedding learning. However, applying typical KD techniques to heterogeneous modalities directly is suboptimal. We put forward in this paper a deep face-to-periocular distillation networks, coined as cross-modal consistent knowledge distillation (CM-CKD) henceforward. The three key ingredients of CM-CKD are (1) shared-weight networks, (2) consistent batch normalization, and (3) a bidirectional consistency distillation for face and periocular through an effectual CKD loss. To be more specific, we leverage face modality for periocular embedding learning, but only periocular images are targeted for identification or verification tasks. Extensive experiments on six constrained and unconstrained periocular datasets disclose that the CM-CKD-learned periocular embeddings extend identification and verification performance by 50% in terms of relative performance gain computed based upon face and periocular baselines. The experiments also reveal that the CM-CKD-learned periocular features enjoy better subject-wise cluster separation, thereby refining the overall accuracy performance.
Compact Surjective Encoding Autoencoder for Unsupervised Novelty Detection
Mar 04, 2020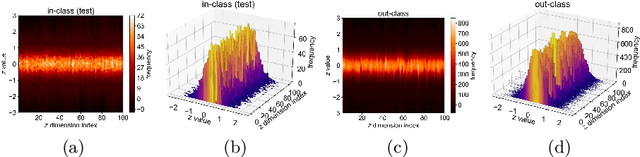
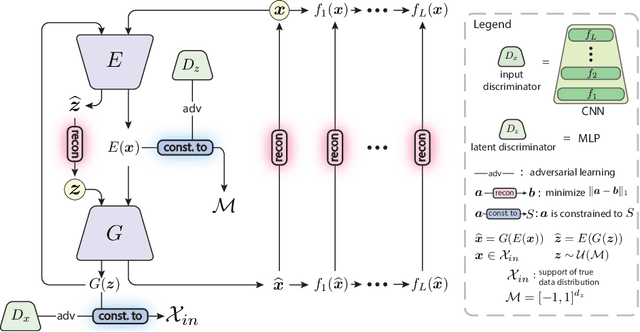
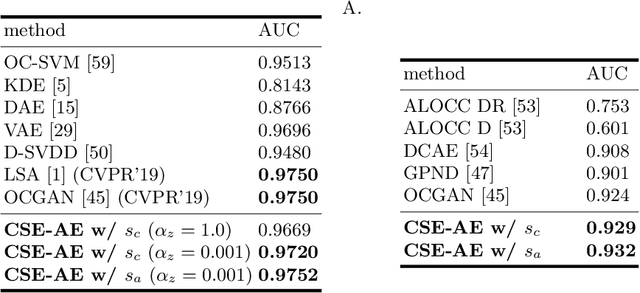

In unsupervised novelty detection, a model is trained solely on the in-class data, and infer to single out out-class data. Autoencoder (AE) variants aim to compactly model the in-class data to reconstruct it exclusively, differentiating it from out-class by the reconstruction error. However, imposing compactness improperly may damage in-class reconstruction and, therefore, detection performance. To solve this, we propose Compact Surjective Encoding AE (CSE-AE). In this model, the encoding of any input is constrained into a compact manifold by exploiting the deep neural net's ignorance of the unknown. Concurrently, the in-class data is surjectively encoded to the compact manifold via AE. The mechanism is realized by both GAN and its ensembled discriminative layers, and results to reconstruct the in-class exclusively. In inference, the reconstruction error of a query is measured using high-level semantics captured by the discriminator. Extensive experiments on image data show that the proposed model gives state-of-the-art performance.