 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Supervision Enhances Geospatial Representations in Vision-Language Models
Jun 05, 2026Geospatial understanding is a critical yet underexplored dimension in the development of machine learning systems for tasks such as image geolocation and spatial reasoning. In this work, we analyze the geospatial representations acquired by three model families: vision-only architectures (e.g., ViT), vision-language models (e.g., CLIP), and large-scale multimodal foundation models (e.g., LLaVA, Qwen, and Gemma). By evaluating across image clusters, including people, landmarks, and everyday objects, grouped based on the degree of localizability, we reveal systematic gaps in spatial accuracy and show that textual supervision enhances the learning of geospatial representations. Our findings suggest the role of language as an effective complementary modality for encoding spatial context and multimodal learning as a key direction for advancing geospatial AI.
Towards AI-Guided Open-World Ecological Taxonomic Classification
Dec 22, 2025AI-guided classification of ecological families, genera, and species underpins global sustainability efforts such as biodiversity monitoring, conservation planning, and policy-making. Progress toward this goal is hindered by long-tailed taxonomic distributions from class imbalance, along with fine-grained taxonomic variations, test-time spatiotemporal domain shifts, and closed-set assumptions that can only recognize previously seen taxa. We introduce the Open-World Ecological Taxonomy Classification, a unified framework that captures the co-occurrence of these challenges in realistic ecological settings. To address them, we propose TaxoNet, an embedding-based encoder with a dual-margin penalization loss that strengthens learning signals from rare underrepresented taxa while mitigating the dominance of overrepresented ones, directly confronting interrelated challenges. We evaluate our method on diverse ecological domains: Google Auto-Arborist (urban trees), iNat-Plantae (Plantae observations from various ecosystems in iNaturalist-2019), and NAFlora-Mini (a curated herbarium collection). Our model consistently outperforms baselines, particularly for rare taxa, establishing a strong foundation for open-world plant taxonomic monitoring. Our findings further show that general-purpose multimodal foundation models remain constrained in plant-domain applications.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
Periocular in the Wild Embedding Learning with Cross-Modal Consistent Knowledge Distillation
Dec 12, 2020
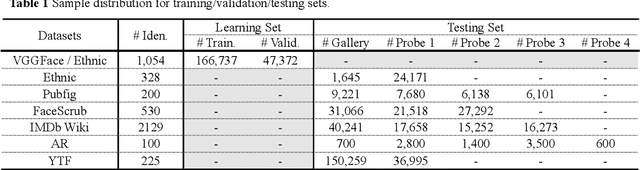
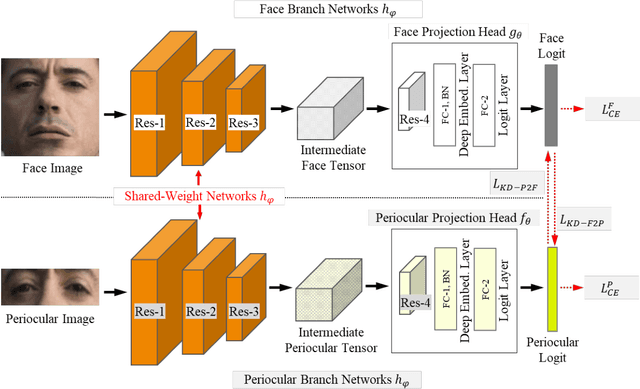

Periocular biometric, or peripheral area of ocular, is a collaborative alternative to face, especially if a face is occluded or masked. In practice, sole periocular biometric captures least salient facial features, thereby suffering from intra-class compactness and inter-class dispersion issues particularly in the wild environment. To address these problems, we transfer useful information from face to support periocular modality by means of knowledge distillation (KD) for embedding learning. However, applying typical KD techniques to heterogeneous modalities directly is suboptimal. We put forward in this paper a deep face-to-periocular distillation networks, coined as cross-modal consistent knowledge distillation (CM-CKD) henceforward. The three key ingredients of CM-CKD are (1) shared-weight networks, (2) consistent batch normalization, and (3) a bidirectional consistency distillation for face and periocular through an effectual CKD loss. To be more specific, we leverage face modality for periocular embedding learning, but only periocular images are targeted for identification or verification tasks. Extensive experiments on six constrained and unconstrained periocular datasets disclose that the CM-CKD-learned periocular embeddings extend identification and verification performance by 50% in terms of relative performance gain computed based upon face and periocular baselines. The experiments also reveal that the CM-CKD-learned periocular features enjoy better subject-wise cluster separation, thereby refining the overall accuracy performance.
Multi-Fold Gabor, PCA and ICA Filter Convolution Descriptor for Face Recognition
Oct 19, 2017



This paper devises a new means of filter diversification, dubbed multi-fold filter convolution (M-FFC), for face recognition. On the assumption that M-FFC receives single-scale Gabor filters of varying orientations as input, these filters are self-cross convolved by M-fold to instantiate a filter offspring set. The M-FFC flexibility also permits cross convolution amongst Gabor filters and other filter banks of profoundly dissimilar traits, e.g., principal component analysis (PCA) filters, and independent component analysis (ICA) filters. The 2-FFC of Gabor, PCA and ICA filters thus yields three offspring sets: (1) Gabor filters solely, (2) Gabor-PCA filters, and (3) Gabor-ICA filters, to render the learning-free and the learning-based 2-FFC descriptors. To facilitate a sensible Gabor filter selection for M-FFC, the 40 multi-scale, multi-orientation Gabor filters are condensed into 8 elementary filters. Aside from that, an average histogram pooling operator is employed to leverage the 2-FFC histogram features, prior to the final whitening PCA compression. The empirical results substantiate that the 2-FFC descriptors prevail over, or on par with, other face descriptors on both identification and verification tasks.